
Fターム[5B091BA11]の内容
Fターム[5B091BA11]の下位に属するFターム
Fターム[5B091BA11]に分類される特許
21 - 40 / 71
音声翻訳装置および方法
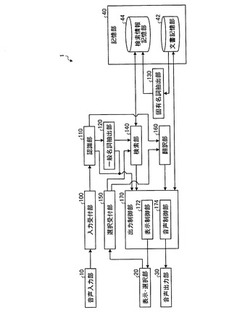
【課題】翻訳したい発話内容に目的言語の固有名詞が含まれる場合であっても、当該発話内容を音声入力する必要のある利用者の負担を軽減させることができる音声翻訳装置おび方法を提供する。
【解決手段】固有名詞抽出部は、文書から目的言語の固有名詞と意味クラスを抽出して検索情報記憶部に記憶させ、入力受付部は、原言語の音声発話の入力を受け付け、認識部は、受け付けられた音声発話を認識して文字列を生成し、一般名詞抽出部は、生成された文字列から一般名詞と意味クラスを抽出し、検索部は、抽出された一般名詞が属する意味クラスに属する固有名詞を検索情報記憶部から検索し、表示制御部は、検索された固有名詞を表示させ、選択受付部は、翻訳に用いる固有名詞の選択を受け付け、翻訳部は、生成された原言語の文字列を、翻訳に用いる固有名詞を用いて目的言語に翻訳し、出力制御部は、翻訳結果を出力させる。
(もっと読む)
情報処理装置および情報処理方法

【課題】同様の翻訳を効率よく実行する。
【解決手段】第1の言語の第1の候補単語に入替え可能な可変部を有する第1の例文と、対応する第1の候補単語を第2の言語で記述した第2の候補単語に入替え可能な第2の可変部を有する第2の例文とを対応付けるテンプレートが格納され、複数キーワードから選択キーワードが指定され、それを第1の候補単語として入替え可能な可変部を持つ第1の例文が1つまたは複数抽出され、その可変部に選択キーワードを入れた第1の例文が表示され、それらから1つが選択され、その第1の例文のテンプレートの内容を特定可能なテンプレート特定情報が格納され(S5812)そのテンプレート特定情報で特定される第1の例文が表示され(S5821〜3)それらから1つの第1の例文が選択され(S5831)テンプレート特定情報で特定される選択された第1の例文に対応する第2の例文が表示される(S5832)。
(もっと読む)
情報処理装置および情報処理方法
【課題】ユーザが、所望するコンテンツを容易に検索できる装置を提供する。
【解決手段】会話アシスト装置100は、入力部410と記憶部420と処理部440と出力部460とを備える。記憶部422に格納されているテンプレートデータベース422は、複数のテンプレート500からなる。各テンプレート500は、複数の言語のカテゴリ文と、キーワードとを対応付けている。キーワードは、1つのキーワードの表記と、1つまたは複数の文字入力(キーワードの読み)とで指定される。入力部410が複数の文字入力のいずれかを受け付けると、例文選択部440は、入力された文字入力に対応するキーワードをもつテンプレート500を抽出する。
(もっと読む)
情報処理装置および情報処理方法
【課題】ユーザが例文に含まれる可変部の単語を容易に変更できる装置を提供する。
【解決手段】例文選択部444は、入力部410が受け付けた指示に基づいて、テンプレートデータベースから例文を選択する。訳文出力部446は、例文選択部444が選択した例文、および、例文の訳文を表示部462に表示する。さらに、訳文出力部446は、例文選択部444が選択した例文の可変部に対応付けて、可変部を指定する指定記号を表示部462に表示する。また、訳文出力部446は、入力部410が指定記号に対応する文字入力を受け付けると、入力された文字に対応する可変部に入替え可能な単語候補を、表示部462に表示する。
(もっと読む)
統計的機械翻訳装置
【課題】特定のクラスの入力文をより安定して頑健に翻訳するSMTシステムを提供する。
【解決手段】SMTシステム30は、ソース文48のクラスメンバーシップを表す確率ベクトルW1、W2及びW3を決定する分類器92と。それぞれのクラスのトレーニングデータで統計的にトレーニングされたクラス特定SMTサブシステムと、サブシステムから出力された確率を補間することによって計算されたターゲット言語の可能な単語シーケンスの確率に従って、最も尤度の高い翻訳仮説50を推定するためのデコーダ96とを含む。
(もっと読む)
翻訳メモリ翻訳装置および翻訳プログラム
【課題】 従来の翻訳メモリ翻訳装置を改良し、翻訳カバー率を向上させた翻訳メモリ翻訳装置を提供する。
【解決手段】 翻訳メモリ翻訳装置100は、例文対訳辞書128を参照し、入力文と完全に一致する第1言語の例文を検索する検索手段と、検索手段により一致する例文が検索されないとき、入力文と第1言語の例文との差分に基づき入力文に類似する第1言語の例文候補を選択する例文選択部142と、例文候補の対訳となる第2言語の例文の中から差分に対応する文字列を識別し、入力文と第2言語の例文の対応関係を求める単語アライメント部144と、識別された文字列を差分に基づき変換することで入力文の第2言語の訳文を生成する訳文生成部148とを有する。
(もっと読む)
翻訳プログラム、翻訳システム及び対訳データ生成方法
【課題】処理負荷が小さく、かつ、翻訳精度の高い翻訳システム及び翻訳プログラム、並びに、対訳データ生成方法を提供すること。
【解決手段】翻訳システム1は、第1言語で表現された複数の第1言語単文データと、第2言語で表現された複数の第2言語単文データとを含み、対訳関係を有する前記第1言語単文データと前記第2言語単文データとが関連付けられて記憶された第1の対訳データ記憶部32と、前記第1言語で表現された原文データを受け取り、前記原文データの訳文データを出力する翻訳処理部40とを含む。前記翻訳処理部40は、前記原文データに基づいて前記第1の対訳データ記憶部に記憶されたいずれかの第1言語単文データを翻訳対象として選択する翻訳対象選択処理部44と、翻訳対象として選択された第1言語単文データと対訳関係を有する第2言語単文データを前記第1の対訳データ記憶部から読み出して、読み出した第2言語単文データに基づき前記訳文データを出力する対訳出力処理部48とを含む。
(もっと読む)
普遍言語による表現を生成するシステムおよびこれに用いられる変換規則を記録した記録媒体
【課題】多種多様な言語間でのコミュニケイションを少ない負担で、容易かつ正確に行える、普遍言語による表現を生成するシステムに用いられる変換規則を記録した記録媒体を提供する
【解決手段】多種多様な言語間でのコミュニケイションを行うシステムにおいて用いられる。変換処理部(300)では、与えられた自然言語による表現について、普遍語辞書(200)を参照して、当該自然語表現を構成する構成要素を、前記普遍語辞書(200)における対応する普遍言語要素に書き替える。また、書き替えられた複数の普遍言語要素について、その配列に従って書替規則(220)を適用して結合させ、かつ、前記二項関係で表記するための規則に従って、二項関係で表記される普遍言語による表現を生成する。
(もっと読む)
機械翻訳装置、機械翻訳方法、及びプログラム
【課題】二言語間の機械翻訳を繰り返すことによって、第1言語から第N言語(Nは3以上の整数である)までの翻訳を行う機械翻訳装置を提供する。
【解決手段】第1言語の翻訳対象となる翻訳対象文書を受け付ける翻訳対象文書受付部11、第1言語から第N言語までの同義の単語の組である多言語対訳情報が1以上記憶される多言語対訳情報記憶部12、その1以上の多言語対訳情報から、第i言語(iは1からN−1の整数である)の翻訳対象文書に含まれる単語を含む多言語対訳情報を選択する多言語対訳情報選択部13、選択後の多言語対訳情報に含まれる二言語間の対訳関係が用いられるように、第1言語の翻訳対象文書からはじめて、第i言語の翻訳対象文書を第(i+1)言語に機械翻訳する処理を第N言語まで繰り返す機械翻訳部14、機械翻訳後の第N言語の文書を出力する出力部15を備える。
(もっと読む)
音訳モデル作成装置、音訳装置、及びそれらのためのコンピュータプログラム
【課題】言語の実情に即した音訳モデルを生成し、その音訳モデルを利用して言語間の音訳を信頼性高く行なうことが可能な音訳装置を提供する。
【解決手段】音訳装置20は、第1及び第2の言語の単語の音訳対を記憶する音訳対記憶装置30と、それら音訳対の各々について、第1の言語と第2の言語の単語又は単語列を構成する文字又は文字列を互いに対応付け、互いに対応付けられた音訳対の各々の第1の言語の文字及び第2の言語の文字を互いの訳語とみなして翻訳モデル48を作成し、音訳モデルとして出力する翻訳モデル作成部44と、第2の言語の文字を単位とするNグラム言語モデル50を作成言語モデル昨西部46と、第1の言語の入力単語52が与えられると、翻訳モデル48をと言語モデル50とを用いた統計的自動翻訳により入力単語52を第2の言語の単語56に音訳して出力する自動翻訳装置54とを含む。
(もっと読む)
リアルタイム発話自然言語翻訳のための方法およびそのための装置
発話言語のリアルタイム自動翻訳を実行するための方法および装置が提供される。発話言語入力が、一方の側で少なくとも1つのソース言語を含む形で受け取られ、自然言語処理テクノロジおよび言語翻訳処理テクノロジを使用して、他方の側で少なくとも1つのターゲット言語を含む形で送出される。発話言語入力は、1人のユーザから他のユーザに伝達する、音声、単語、文、アクセント、句、発音を含む。伝達発話言語入力は、ターゲット出力言語翻訳のために、一方の側で、自然言語分解テクノロジによって実行される分解プロセスを通過し、デジタル化グローバルソース分解言語フォーマットに符号化される。符号化分解デジタル化グローバルソース言語フォーマットは、他方の側によって受け取られ、統合デジタル化グローバルターゲット言語フォーマットに復号され、それは、他方の側で、自然言語統合テクノロジによって実行されるさらなる統合復号プロセスを通過し、少なくとも1つのターゲット言語を含む発話言語出力に翻訳される。  (もっと読む)
(もっと読む)
自動同時通訳システム
本通訳システムは、起点言語で書かれ、または発音された文の視覚的または聴覚的取得手段および音声の変換手段、取得手段で取得した入力信号から、起点言語への文の転写である起点言語文を生成するための認識手段(30)、起点言語文から、目標言語への起点言語文の翻訳である目標言語文を生成するための翻訳手段(32)および目標言語文から、音響変換手段によって再生されることのできる出力音響信号を生成するための音声合成手段 (34)を含む通訳システムである。本発明では、本通訳システムは、リアルタイムで、起点言語での文を目標言語に生成するために、認識手段(30)、翻訳手段(32)および音声合成手段 (35)を呼び出すための平滑化手段(40)を含んでいる。 (もっと読む)
自然言語の定式化
自然言語テキストの一義的モデルを作ることを可能にする自然言語の定式化のための方法が開示されている。自然言語で名前が付けられる実体についての基本概念を決定すると共に、各基本概念に対して、固有の番号又は名前と記述が添付され、更に、使用される各自然言語について、基本概念を指定できる語のリストが添付される。一義的モデルは基本概念のみを使用する。この方法では、機械が一義的モデルを解釈する共に、知識やデータをベースにインプットするか、又は一義的モデルを用いて他の自然言語でテキストを生成する。また、プログラム言語等の人工言語でテキストを生成することもできる。 (もっと読む)
電子機器、その制御方法、および、その制御プログラム
【課題】複数の言語が混在する文である多言語混在文に関し、種々の情報を取扱うことのできる電子機器、その制御方法、および、その制御プログラムを提供する。
【解決手段】電子機器では、入力文と翻訳文(出力文)が、出力文における優先出力言語と混在言語の割合を表わす画像(スライドバー表示部101)とともに表示される。スライドバー表示部101の中に、スライドバー102とともに、その下部に五段階で翻訳文(出力文)における言語の割合を示すための割合表示記号101A〜101Eを表示させる。スライドバー102は、割合表示記号101A〜101Eのいずれかに対応する位置に表示される。
(もっと読む)
機械翻訳装置、機械翻訳方法、および生成規則作成装置、生成規則作成方法、ならびにそれらのプログラムおよび記録媒体
【課題】翻訳精度を向上させることのできる機械翻訳技術を提供する。
【解決手段】機械翻訳装置2は、翻訳元または翻訳先の文を構成する部分木の階層的特徴を表現する素性を示す階層的素性119と、翻訳元に含まれずに翻訳先の文に挿入されている単語と翻訳元単語との関係を表現する素性を示す翻訳先言語挿入素性118と、ルールテーブル114に格納された翻訳モデルとを含む素性に対応した重みを、素性重み学習用対訳学習データ250に基づいて学習し、素性重み211を格納する素性重み学習手段221と、素性ベクトルと素性重みベクトルとの内積を部分仮説スコアとして算出する部分仮説スコア算出手段243と、入力文に対して適用可能な部分仮説を探索し、部分仮説を拡張することによって最終的に生成された部分仮説のうちで部分仮説スコアが最大となる部分仮説を仮説として探索する仮説探索手段244とを備える。
(もっと読む)
原言語文を目的言語文に機械翻訳する装置、方法およびプログラム
【課題】用例ベースの翻訳方式の翻訳精度を向上させる機械翻訳装置を提供する。
【解決手段】原言語による入力文を受付ける受付部101と、入力文と一致または類似する原言語の用例に対応する目的言語の用例に基づいて、入力文を目的言語に翻訳した用例翻訳候補と、用例翻訳候補の確からしさを表す第1尤度とを求める用例翻訳部102と、用例翻訳部102による処理と異なる処理により入力文を目的言語に翻訳し、入力文の単語それぞれに対する翻訳結果の候補のうち、第2尤度が第1閾値以上である候補を表す訳語候補を生成する生成部103と、用例翻訳候補それぞれについて、用例翻訳候補に含まれる訳語が訳語候補に存在しない場合に、第1尤度を所定値だけ下げる変更部105aと、用例翻訳候補から第1尤度が最大の用例翻訳候補を選択する選択部105bと、を備えた。
(もっと読む)
電子機器、その制御方法、および、翻訳文出力用プログラム
【課題】翻訳文として有用な多言語混在文を出力する電子機器を提供する。
【解決手段】辞書メモリ210では、日本語の単語が、その単語の日本語における言語レベルと、その単語の日本語における品詞と、その単語の日本語における意味を特定するグループ番号と、その単語に対応する英単語と、その英単語の英語における言語レベルと、その英単語の英語における品詞と、その英単語の英語における言語レベルと、その単語に対応する中国語の単語と、その中国語の単語の中国語における言語レベルと、その中国語の単語の中国語における品詞と、その中国語の単語の中国語における言語レベルとに関連付けて記憶されている。そして、電子機器では、翻訳文において、ユーザの各言語についての言語レベルに応じて、品詞ごとに使用する単語の言語が選択される。
(もっと読む)
用例ベースの機械翻訳システム
【課題】翻訳するソース言語センテンスのフラグメントを用例ベース中の用例のソース言語部分にマッチさせることによって機械翻訳を行うこと。
【解決手段】用例ベース中のすべての該当する用例を識別すると、それらの用例のフレーズアライメントを行う。フレーズアライメントでは、各用例中のターゲット言語センテンスのフラグメント、同じ用例中のソース言語センテンスのマッチしたフラグメントに対してアラインさせる。次いで、翻訳コンポーネントは、マッチした用例のアラインさせたターゲット言語フレーズをソース言語センテンス中のマッチしたフラグメントと置き換える。
(もっと読む)
翻訳装置、方法及びプログラム
【課題】多言語話者間での効率的な対話を可能にする。
【解決手段】第1の言語の例文に含まれている複数の単語及び句のそれぞれを意味的に抽象化した複数のクラス情報の構文木を蓄積する例文蓄積部と、第1の言語の文に含まれている複数の単語及び句のそれぞれを意味的に抽象化して、複数のクラス情報を特定する意味的抽象化部と、例文蓄積部に蓄積された例文の構文木と、特定されたクラス情報の構文木とが類似する場合に、特定されたクラス情報の構文木の抽象化前の複数の単語及び句の出力単位で分割する分割部と、第1の言語の単語及び句の出力単位と意味的に対応する、第2の言語の単語及び句の出力単位を生成する翻訳出力単位生成部と、第1の言語の単語及び句の出力単位と、生成された第2の言語の単語及び句の出力単位とを、対応する意味同士で対応付ける対応付部と、を備える。
(もっと読む)
翻訳装置及び翻訳プログラム
【課題】入力文に含まれる基本的な情報を翻訳文に確実に反映させることができると共に、入力文と類似する用例や入力文と一致するパターンがなくても、当該入力文を自然な翻訳文にして出力することができる翻訳装置及び翻訳プログラムを提供する。
【解決手段】翻訳装置1は、入力された集合文章から話題を特定して、この話題を特定した集合文章に含まれる第一言語の文章である入力文を、第二言語の文章である翻訳文にして出力するものであって、集合文章話題分類手段3と、キーワードデータベース5と、基本情報取得手段7と、基本情報データベース9と、基本情報値抽出手段11と、基本情報値抽出規則データベース13と、基本情報値翻訳変換手段15と、対訳変換データベース17と、翻訳文出力手段19と、テンプレートデータベース21とを備える構成とした。
(もっと読む)
21 - 40 / 71
[ Back to top ]