
Fターム[5B091BA11]の内容
Fターム[5B091BA11]の下位に属するFターム
Fターム[5B091BA11]に分類される特許
61 - 71 / 71
翻訳装置、翻訳方法およびプログラム
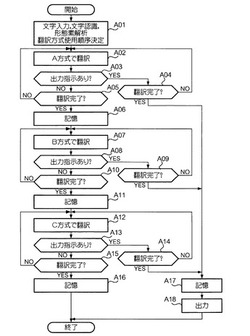
【課題】 短時間でできるだけ精度の高い翻訳結果を得ることのできる技術の提供を目的とする。
【解決手段】 翻訳装置1は、互いに異なる複数の翻訳方式を翻訳精度の低いものから順次使用して原文を翻訳し、複数の翻訳方式の各々による翻訳が完了し次第、翻訳の完了した翻訳方式による翻訳文を記憶する。そして、翻訳文の出力が指示された時点で、記憶されている翻訳文の中から最後に記憶された翻訳文を抽出し、この翻訳文を表すデータを出力する。
(もっと読む)
翻訳システム、翻訳装置、翻訳方法及びプログラム

【課題】 翻訳先言語を母国語として利用している者から見ても、より自然な文章となるように翻訳する。
【解決手段】 翻訳装置10は、機械翻訳により得られた複数の翻訳文候補を、インターネット20上の検索エンジンサーバ装置30に対して検索キーワードとして入力する。検索エンジンサーバ装置30は、指定された検索キーワードと、WWWサイトで公開されている様々な文章とを比較し、そのヒット件数乃至ヒット確率を出力する。つまり、この検索エンジンでヒットする件数乃至確率が高い表現は、多くの人間が使用している表現であると言える。よって、複数の翻訳文候補のうち、ヒットした件数乃至確率が大きい翻訳文候補は、語句の組み合わせや順序などがより自然で一般的な文章と言える。従って、検索エンジンでヒットした件数乃至確率が大きい翻訳文候補を用いて翻訳文を作成すれば、ネイティブスピーカにとって自然な言い回しの翻訳文となる。
(もっと読む)
単語ラティス翻訳装置及び音声翻訳システム
【課題】入力音声を高品質で翻訳しながら、計算コストの増加を避けることのできる音声翻訳システムを提供する。
【解決手段】単語ラティス翻訳装置は、ソース言語の単語ラティスをターゲット言語の単語グラフに変換する処理を行なうための変換セクション144と、ターゲット言語の単語グラフ内で最も確率の高い経路を探索することによって単語グラフを翻訳し、その経路に対応する翻訳を出力する処理を行なうための単語ラティス翻訳モジュール146とを含む。
(もっと読む)
翻訳装置及びコンピュータプログラム
【課題】 計算コストを減じつつ、貪欲デコードアルゴリズムを用いる翻訳装置を提供する。
【解決手段】 第1の言語の文46を第2の言語の文72に翻訳するための翻訳装置30は、第1の言語の文46を第2の言語の仮説56に翻訳するためのMTエンジン52と、統計に基づき、仮説56中から、初期仮説から仮説を生成するための予め定められたアルゴリズムにおいてより良い仮説を生成するであろう仮説を選択するための分類器58及び仮説選択部74と、分類器58及び仮説選択部74によって選択された仮説から、予め定められたアルゴリズムを用いて翻訳文72を生成するためのデコーダ68とを含む。
(もっと読む)
プログラム、自動翻訳装置、自動翻訳システム及び音声認識システム
【課題】より翻訳精度の高い自動翻訳装置、自動翻訳システム及び音声認識システム、及びプログラムを提供する。
【解決手段】本プログラムは、第1の言語の発話内容を第2の言語に翻訳を行う際に必要な辞書データが記憶された辞書データベース182,184と、前記発話内容、及び前記発話内容のイメージを連想するためのメタ情報を受け取り、前記メタ情報に基づき辞書データベースを検索して、前記発話内容を第2の言語に翻訳する翻訳処理部110,120としてコンピュータを機能させ、前記辞書データベースは、第1の言語の各単語に対応づけて、第2の言語の訳語と、各単語の意味、関連語句及び使用例の少なくとも一つを含む付属情報が記憶され、前記翻訳処理部は、前記メタ情報を用いて前記辞書データベースを検索し、第1の言語の発話内容を構成する語句を特定し、特定した語句に対応した単語の訳語を用いて第2の言語への翻訳を行う。
(もっと読む)
用例翻訳装置、及び用例翻訳方法
【課題】対訳用例コーパスを用いて、原言語から目的言語への翻訳を可能とする用例翻訳装置を提供する。
【解決手段】文書情報を受け付ける受付部11と、複数の原言語用例と目的言語における原言語用例の訳である複数の目的言語用例とを対応付けて有する対訳用例コーパスを記憶している対訳用例コーパス記憶部12と、対訳用例コーパスの複数の原言語用例から、文書情報と類似する2以上の原言語用例を選択する選択部13と、選択された2以上の原言語用例に対応する2以上の目的言語用例を用いて、文書情報の翻訳の候補を示す翻訳候補情報を作成する翻訳候補情報作成部14と、翻訳候補情報から所定の条件を充たす翻訳の候補を選択し、その選択した翻訳の候補を示す翻訳文書情報を作成する翻訳文書情報作成部15と、翻訳文書情報を出力する出力部16と、を備える。
(もっと読む)
音声作成方法および音声作成装置
【課題】 正確な翻訳処理のみならず、従来と比してより品質の高い、音声合成、音声出力を実現する音声作成方法を提供する。
【解決手段】 ユーザーインターフェースへの入力操作に基づいて実行される、第一の言語で記述された複数の例文と、第一の言語で記述された複数の例文のそれぞれに対応する第二の言語で記述された複数の例文とを保持しているデータベースから、第一の言語で記述された例文を少なくとも一つ選択する選択ステップと、選択ステップにより選択された例文に対し所定のパラメータを付与しつつ編集を行う編集ステップと、編集ステップにより編集が行われた第一の言語で記述された例文を第二の言語に変換する変換ステップと、変換ステップにより変換された第二の言語で記述された例文を、第二の言語に対応する音声合成手段により音声合成する音声合成ステップとを有する音声作成方法を提供する。
(もっと読む)
翻訳装置、翻訳プログラム及び翻訳方法
【課題】翻訳作業を効率的に進めることができ、迅速で、信頼性の高い翻訳を行う。
【解決手段】入力文を受付ける入力文受付部と、例文の部分列を作成する部分列作成部と、例文の部分列を用いて第1言語と第2言語の対訳例文を検索する対訳例文検索部と、対訳例文から所定の対訳例文をフレーズ候補として抽出するフレーズ候補抽出部と、フレーズ候補から所定のフレーズを選択するフレーズ候補整理部と、入力文の構文を解析する構文解析部と、構文の意味を解析し対応訳語を含む概念構造を生成する意味解析部と、フレーズ候補における第1言語の単語で前記対応訳語を検索する対応訳語検索部と、対応訳語がヒットした場合に、意味解析部で生成された概念構造の対応訳語における第2言語の単語を、フレーズ候補における第1言語の単語に対応する第2言語の単語に置き換える訳語置き換え部と、置き換えられた訳語を用いて訳文を生成する訳文生成部とを備える。
(もっと読む)
ツリーレット翻訳対の抽出
【課題】構文の依存関係のツリーレットを使用する機械翻訳システムを提供すること。
【解決手段】本発明の一実施形態では、デコーダが、原言語入力として依存関係ツリーを受け取り、統計モデルのセットにアクセスし、統計モデルのセットから、対数線形のフレームワークで組み合わせられた出力が生成される。デコーダは、ツリーレット翻訳対のテーブルにもアクセスし、原言語の依存関係ツリー、ツリーレット翻訳対テーブルへのアクセス、および統計モデルの適用に基づいて、目標言語の依存関係ツリーを返す。
(もっと読む)
疑似インターリングア及び交雑アプローチを用いた英語からヒンディ語及びその他のインド諸語への複数言語機械翻訳システム
本発明は、ソース言語をターゲット言語に翻訳する方法及びシステムであって、ソース文書から抽出されたテキストの性質を識別するステップと、前記抽出されたテキストのテキスト・フォーマット及び構造情報をフィルタリングし記憶するステップと、前記抽出されたテキストの性質に基づき、適切なテキスト翻訳エンジンを選択するステップと、前記テキスト翻訳エンジンを用いて、前記抽出されたテキストを解析し、フォーマットされていない翻訳済テキストに翻訳するステップと、前記記憶されたテキスト・フォーマット及び構造情報を用い、前記フォーマットされていないテキストを処理して、ターゲット言語の構造化された翻訳済テキスト文書を取得するステップと、を含む方法及びシステムに関する。  (もっと読む)
(もっと読む)
自動翻訳装置及びその自動翻訳装置を利用した自動翻訳方法並びにその自動翻訳装置が記録された記録媒体
本発明は、自動翻訳装置及びその自動翻訳装置を利用した自動翻訳方法並びにその自動翻訳装置が記録された記録媒体に関し、より詳しくは、英語を中国語にあるいは中国語を英語に翻訳する場合、目的原語の対訳語文章をより自然かつ正確な翻訳に生成することができる。これは、中国語特有の様々な文法的特性を考慮して作製したアルゴリズムを本発明の自動翻訳装置及び記録媒体に採用することによって実現できた。前記特殊翻訳アルゴリズムは、本発明の基本概念であると同時に主要概念である。
本発明による自動翻訳装置は、辞典DB100、形態素分析手段200、基礎文章成分規定手段300、加工文章要素規定手段400、特殊文章要素翻訳手段500、一般文章要素翻訳手段600、完成翻訳文出力手段700で構成される。特殊文章成分翻訳手段500と連結されている特殊文章要素連結ポインターは、5種類の特殊翻訳モジュール501〜505と連係して作動する。前記100〜700、及び特殊翻訳モジュール501〜505のプロセスを通じて英語と中国語間の翻訳をより自然かつ正確に生成することができる。
本発明は、特許出願者が2003年3月開発した試製品(本発明の核心である特殊翻訳アルゴリズムを適用)により、理論の実際適用が妥当であることが検証された。本発明の実施例(図5、6、7、8、9)は、試製品を実際に作動させて得られた翻訳文の例である。
 (もっと読む)
(もっと読む)
61 - 71 / 71
[ Back to top ]