
Fターム[5B091CA05]の内容
Fターム[5B091CA05]の下位に属するFターム
Fターム[5B091CA05]に分類される特許
161 - 180 / 258
コミュニケーションを支援する装置、方法およびプログラム

【課題】対話を円滑に行うコミュニケーション支援装置を提供する。
【解決手段】第1言語文の入力を受付ける第1言語受付部101と、第1言語文を構文解析して1または複数の単語を構成要素とする第1言語構造情報を生成する第1言語解析部102と、受付けた第1言語文を翻訳した第2言語文を生成する第2言語文生成部104と、第2言語文を受付ける第2言語受付部111と、第2言語文を構文解析して1または複数の単語を構成要素とする第2言語構造情報を生成する第2言語解析部112と、第1言語構造情報を構成する第1単語と、第2言語構造情報を構成する第2単語とを比較し、同一または類似の意味内容を含む第1単語が存在しない第2単語を抽出する抽出部131と、第2言語文を翻訳し、抽出した第2単語に対応する第3単語を、抽出した第2単語以外に対応する第4単語より優先して出力する第1言語文を生成する第1言語文生成部114と、を備えた。
(もっと読む)
自然言語処理装置、プログラム及び方法

【課題】 上位語及び下位語の関係にある単語の表現も適切に統合する自然言語処理装置を統合する。
【解決手段】 本発明の自然言語処理装置は、類義語辞書、係り受け抽出手段及び係り受け統合処理手段を有する。類義語辞書は、見出し単語に対する類義語として、上位語若しくは下位語の少なくとも一方の要素を格納していることもあり得る。係り受け抽出手段は、入力された電子文書について係り受け情報を抽出し、係り受け統合処理手段は、類義語辞書を参照し、抽出された複数の係り受け情報における係り側単語又は受け側単語の少なくとも一方について類義語を検索し、類義語が検出された場合には、検出された類義語の部分を、検出された全ての類義語を含む組に統合する。
(もっと読む)
文書解析装置、および文書解析方法、並びにコンピュータ・プログラム
【課題】効率的かつ正確なパターンマッチによる文書解析を実行する装置および方法を実現する。
【解決手段】パターンマッチ条件に基づき登録データの出力を行なうルールから構成される構文パターン集をルールの複雑度に応じて区分して、複数の構文パターン集として設定し、ルールの複雑度の低い構文パターン集から、ルールの複雑度の高い構文パターン集を、順次適用して構文パターンマッチ解析処理を実行する。本構成により効率的かつ正確なパターンマッチによる文書解析が実現される。
(もっと読む)
自然言語のテキストからオントロジを開発するための、コンピュータによって使用される方法
本発明は、自然言語のテキスト(10)のオントロジ(70)を開発するための、コンピュータによって使用される方法であって、
前記テキスト(10)からテキスト・データを受信するステップと、
前記受信データの文法的分析(S100)によって、前記テキストから構文と有意味の単語(20)を抽出するステップと、
前記テキストの前記有意味の単語(20)のうちの少なくとも一部ごとに、少なくとも1つの電子辞書(30、35)を用いてその単語(20)の定義(40)を検索するステップ(S200)と、前記定義の前記構文と前記有意味の単語を抽出するステップと、およびその定義の基本の語彙グラフ(50)をその定義の前記構文と前記有意味の単語に基づいて作成するステップ(S300)と、
前記テキストの前記構文に応じて、前記テキストの少なくとも1つの意味グラフ(60)を作成するために、作成された前記基本の語彙グラフ(50)のうちの少なくとも2つを統合するステップ(S400)とを含む方法に関する。
本発明はさらに、本発明の方法のステップを実装するように適合された、コンピュータ・プログラム製品と、コード手段を含む電子データ処理システムに関する。 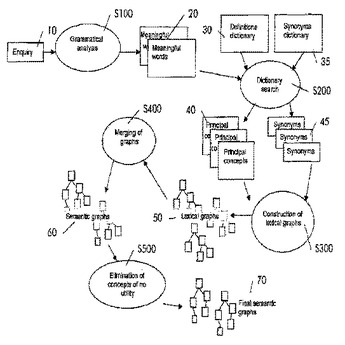 (もっと読む)
(もっと読む)
概念ネットワーク生成システム、概念ネットワーク生成方法及び概念ネットワーク生成プログラム
【課題】適切な単語間の概念関係を得て概念ネットワークを生成することが可能な概念ネットワーク生成システム、概念ネットワーク生成方法及び概念ネットワーク生成プログラムを提供する。
【解決手段】概念ネットワーク生成システムを構成するPC100は、第1及び第2の単語の双方を含む第1検索結果文及びいずれか一方を含む第2検索結果文を取得する検索部12と、第1検索結果文に対応する第1格構造パターン情報と、第2検索結果文に対応する第2格構造パターン情報を生成する解析・格構造生成部14と、第2格構造パターン情報に対応する第2検索結果文における、第1検索結果文内の第2の単語に対応する単語と、第1の単語とを概念関係として設定するオントロジー生成部18とを有する。
(もっと読む)
文書処理装置、文書処理方法、および、文書処理プログラム
【課題】 文書処理において、テキストの類似した意味を持つ頻出パターンの構造から、対応する典型的な自然言語表現を生成する。
【解決手段】 言語解析手段21は、記憶装置100のテキストDB11から文の集合を読み取り各文に対して形態素解析や係り受け解析を行い、頻出パターン抽出手段22は、木構造から頻出して現れる部分構造を抽出し、典型表現生成手段23は、頻出パターン抽出手段22で作成された部分構造に対応する形態素列をスコア付けし、最もスコアの高い自然言語表現、もしくは、スコア順にランキングされた複数の自然言語表現を生成し、出力装置300に出力する。
(もっと読む)
重複データ検出プログラム、重複データ検出方法および重複データ検出装置
【課題】短時間で重複データを検出するためのデータ絞り込みを容易に行う重複データ検出プログラム、重複データ検出方法および重複データ検出装置を提供する。
【解決手段】コンピュータ1は以下の機能を有する。構文木構築手段2が、データ毎に、文字列の隣接しない所定の文字位置の文字を複数個取り出した構文木を構築する。重複データ検出手段3が、構文木の葉ノード毎に、葉ノードに到達したデータが複数存在するか否かを判断し、同一の葉ノードに到達したデータを重複データ候補として検出する。
(もっと読む)
2カ国語コーパスからの変換マッピングの自動抽出プログラム
【課題】機械翻訳システムを改善する必要性に対処するシステムまたは方法を提供する。
【解決手段】2カ国語コーパス取得される依存構造のノードを整列させるメソッド300は、第1の段階302が、該依存構造のノードを関連付けて仮の対応を形成する2段階アプローチを含む。次いで、段階304において、該依存構造のノードを仮の対応および/または構造的考察に応じて整列させる。整列した依存構造からマッピングを取得する。翻訳実行時により流暢な翻訳が取得できるように、ローカルコンテキストの種類および量の変化に応じてマッピングを拡大することが可能である。
(もっと読む)
データ処理装置
【課題】文書データ中に必要な記述の不足を判定する。
【解決手段】形態素解析部3は、記憶装置2に記憶される入力文書データ中の形態素解析を行なって、文書データ中の各文節を当該文節の品詞情報とともに認識する。構文解析部4は、形態素解析結果を入力して各文節の構文解析を行なって、各文節の文法上の関係を示す構文木を構文解析結果として生成する。判定部6は構文解析結果を示す構文木のルートに対応する文節がない場合には、入力文書データ中の文に欠損がある、つまり文法上の正しい文として成立するための文節が記述されていないと判定する。この場合には、判定部6は、入力文書データ中の文に、文法上の正しい文として成立するための必要な記述が不足している旨を示すメッセージを生成して出力装置8に出力させる。
(もっと読む)
モビール形状概念を基礎にした構文分析方法及びこれを用いた自然語検索方法
【課題】いかなる語順倒置型構文も分析が容易なので、早く処理することができ、文章を構成する表現間の文法的関係を正確に捕捉する。
【解決手段】構文分析方法及び自然語検索方法は、文法規則データベースと、助詞と語尾を共に統語の単位として取り扱う標識理論に基づいて用言語尾の統語的地位を認定し、語彙間の統合関係が完全に文法的に規定され得るように、文章の各構成成分の語幹及び語尾など中心語が有する下位範疇の内訳が格納される下位範疇化データベースとを構築し、入力された文章を形態素分析段階と、分析された形態素を文法規則データベースに格納された文法的規則によって文章の部分的な構造をまず確立し、前記下位範疇化データベースを用いて全体的な構造を確立し、各構造の加重値を計算して、最も適した最適例を確定して出力する構文分析段階と、を備えてなる。
(もっと読む)
文書データ解析装置および方法
【課題】係り受け関係同士の関係に着目して、文書データ解析を支援する。
【解決手段】係り受け関係検索条件入力部16は、取り出したい係り受け関係を指定するものである。通常の検索では、キーワードおよびその検索位置(係り部か受け部か、またはその双方)を指定する。係り受け関係検索部17は係り受け関係集合記憶部15の基礎意味チャンク集合記憶部15aを参照して該当する係り受け関係を抽出し、表示部19は検索結果の係り受け関係集合を表示する。左演算/右演算の検索では、左演算/右演算のいずれかの指定、キーワードおよびその検索位置を指定する。係り受け関係検索部17は係り受け関係集合記憶部15のメタ意味チャンク記憶部15bを参照して係り元または係り先の係り受け関係を抽出し、表示部19は検索結果の係り受け関係集合を表示する。
(もっと読む)
文一致度分析装置および方法、ならびに言語変換装置および方法
【課題】単語の表面的な一致度と構文の一致度を適切に加味して一致度を判別する。
【解決手段】翻訳条件指定部101により翻訳条件を指定する。統合一致度算出部102は、単語集合一致度記憶部108および構文一致度記憶部109から該当する単語集合一致度および構文一致度を読み出して、r×(単語集合一致度)+(1−r)×(構文一致度)により、統合一致度を算出する。文選択部103は、条件を満たすコーパス内の1または複数の文を特定し、それに対応する翻訳先の文を選択する。翻訳文出力部104は選択された翻訳結果の文をコーパス記憶部106から読み出して出力する。
(もっと読む)
類似性評価装置及びプログラム
【課題】比較する日本語文全体の特徴を考慮することにより、類似性評価の結果の信頼性を向上させることが可能な類似性評価装置及びプログラムを提供する。
【解決手段】木構造生成部2が、入力日本語文及び対象日本語文を構文解析し、木構造をそれぞれ生成し、部分構造生成部3が、木構造から部分構造を生成する。部分構造評価部4は、部分構造間の構文上の類似度、及び部分構造間の単語の類似度を算出し、これらの構文上の類似度及び単語の類似度に基づいて部分構造間の類似度を算出する。そして、文評価部5は、部分構造間の類似度に基づいて、入力日本語文と対象日本語文との間の類似度を算出する。
(もっと読む)
情報抽出装置、及び情報抽出方法
【課題】ユーザによるキーワード入力などの煩雑な操作なしに、文書のテキスト部分を、時期、場所、主体、対象、態様の5要素の情報および述語情報として抽出できる情報抽出装置、及び情報抽出方法を提供する。
【解決手段】情報抽出装置10は、言語解析部12、要素抽出部13、および補完情報取得部14を備える。言語解析部12は、入力する文書情報からテキスト部分を言語解析する。補完情報取得部14は、文書に付随するプロパティなどの付随情報を取得する。要素抽出部13は、言語解析された結果に対して、取得された付随情報を補完し、テキスト情報中の時期、場所、主体、対象、態様の5要素の情報および述語情報を抽出する。
(もっと読む)
体験情報抽出方法及び装置及びプログラム及びコンピュータ読み取り可能な記録媒体
【課題】ある文書が与えられた時に、キーワードなどの入力がなくても、その文書の筆者が何についてどのような体験を記述しているか、体験の対象と体験した事柄を提示する。
【解決手段】本発明は、物事を利用もしくは体験・経験したことを表すような語句を体験表現とするときに、体験表現と体験の対象となる語句との関係、あるいは該体験表現と該語句を総称したカテゴリとの関係、もしくは、該体験表現と該語句と該カテゴリの関係を含む情報が格納されている体験表現辞書記憶手段を参照して、入力文書中で該当する体験表現に対応する語句やカテゴリを選定する。
(もっと読む)
中国語解析装置、中国語解析方法および中国語解析プログラム
【課題】離合詞を含む中国語の解析処理において予め挿入成分の列挙をせずに、網羅的かつ正確に離合詞を認識すること。
【解決手段】入力された中国語文から形態素ごとに分割された単語ごとに、該単語に対する係り受けの依存先と該単語に対する係り受けの依存元を解析する依存構造解析部104と、中国語の形態素となる単語であって離合詞を構成しうる第1の単語ごとに該第1の単語と連結することにより離合詞を構成する第2の単語の一覧を示す離合詞リストに基づいて、依存構造解析がなされた単語から第1の単語および第2の単語を検出し、この検出された第1の単語および第2の単語を共に係り受けの依存先とする単語の依存先を、第1の単語および第2の単語を連結した離合詞に変更する離合詞処理部105と、を備えた。
(もっと読む)
機械翻訳の方法およびシステム
言語間の解析モデルを生成し、目的言語にソース言語を機械翻訳するモデルを使用するためのシステムおよび方法が提供される。システムおよび方法は、ソース言語の文の受容、および、各々が目的言語の単語、統語上のラベル、および、要素間の関係を示す役割ラベルで分類される要素を有する候補解析の言語間の解析モデルでの検索および統計学的なランク付けを含む。統計学的に高ランクの解析は、ソース言語の文の言語間の解析を生成するため、目的言語の語順規則に従って統語上のおよび役割ラベルを用いて選ばれ、再配置される。  (もっと読む)
(もっと読む)
情報抽出規則生成方法、装置、およびプログラム
【課題】情報抽出装置用の抽出規則を効率的に生成する。
【解決手段】ユーザがサンプル学習データとして、テキストとそこから抽出されるデータを目的テーブル4に記載し、この2つのデータを装置に入力すると、テキスト入力部1から入力された複数のテキストデータが、辞書3を参照しながら動作するテキスト解析部2により解析され、複数の解析データとして出力される。その複数の解析データと目的テーブル4を比較し、規則生成部5が抽出規則を自動的に作成する。作成された規則データは、規則DB6に蓄積され、規則適応部7で規則としてテキスト解析部2からの解析データに適用され、規則がマッチしたデータが抽出される。抽出されたデータは目的テーブル4と同じ形式で出力される。
(もっと読む)
文章構造解析装置、およびプログラム
【課題】従来の文章構造解析装置においては、構造解析を高精度に行うことができない、という課題があった。
【解決手段】文章情報を分割して取得した1以上の各節情報に対して、一の節情報が含む最終の文節情報を除く文節情報が、当該一の節情報以外の他の節情報が有する文節情報にかかるか否かを、前記被係受文節情報を用いて判断し、一の節情報が含む最終の文節情報を除く文節情報が、当該一の節情報以外の他の節情報が有する文節情報にかかるとの判断の場合、当該一の節情報を単独で構文解析し、前記他の節情報が有する文節情報にかかると判断された文節情報と対になる被係受文節情報を取得し、取得した被係受文節情報を、対応する被係受文節情報に置き換え、出力する1以上の文節情報と被係受文節情報との組を1組以上得て、当該得た情報を出力する文章構造解析装置により、構造解析を高精度に行うことができる。
(もっと読む)
依存構造に基づく例文検索方法、プログラム、および例文検索プログラムを記録した記録媒体、ならびに例文検索装置
【課題】特別な表現による検索条件を必要とすることなく、蓄積された複数の例文から、検索条件に含まれる単語を構文的に含む例文を検索する例文検索方法、装置およびプログラムを提供する。
【解決手段】予め蓄積された複数の例文と、そのそれぞれの例文を構成する単語間の依存関係を予め解析して得られた依存構造情報とをあわせて蓄積する言語資料蓄積工程と、検索しようとする文に含まれる複数の単語と該単語の順序とに基づく検索条件を設定する検索条件設定工程と、複数の単語の依存構造を表現する依存構造パターンを生成する依存構造パターン生成工程と、前記依存構造パターン生成工程によって、前記複数の例文のうち、前記検索条件に含まれるすべての単語間の依存構造を一の依存構造パターンで生成できたものを前記検索条件に該当するものとして選択する文選択工程とを有する。
(もっと読む)
161 - 180 / 258
[ Back to top ]