
Fターム[5B091EA07]の内容
Fターム[5B091EA07]に分類される特許
1 - 14 / 14
モデルパラメータ配列装置とその方法とプログラム
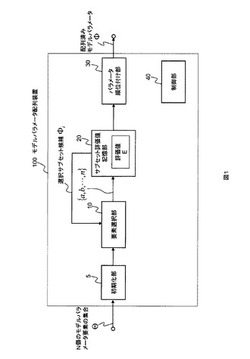
【課題】モデルの要素集合Θのパラメータ要素をその重要度順に配列するモデルパラメータ配列装置を提供する。
【解決手段】初期化部は、選択サブセット候補を空集合で初期化して集合Θと選択サブセット候補を出力する。要素選択部は、集合Θと選択サブセット候補を入力として、サブセット候補として選択サブセット候補と他のパラメータ要素との全ての組を出力する。サブセット評価値記憶部は、サブセット候補を入力として、当該サブセット候補のそれぞれのスコアEtの最大値若しくは最小値と、上記集合Θのスコア値である評価値Eとの差分を求め、その差分が最小若しくは最大となるサブセット候補を選択サブセット候補として記憶する。
(もっと読む)
対訳フレーズ学習装置、フレーズベース統計的機械翻訳装置、対訳フレーズ学習方法、および対訳フレーズ生産方法

【課題】種々の粒度のフレーズペアを学習できなかったり、不適切なフレーズペアを学習したりした。
【解決手段】フレーズテーブルと、フレーズペアの取得を試みて、取得できなかった場合、一の記号を取得する記号取得部と、フレーズペアを取得できなかった場合、当該フレーズペアより小さい2つのフレーズペアを生成する部分フレーズペア生成部と、取得した記号に従って、新しいフレーズペアを生成する、または、2つのフレーズペアを順に繋げた新しいフレーズペアを生成する、または、2つのフレーズペアを逆順に繋げたフレーズペアを生成する、のいずれかを行う新フレーズペア生成部とを具備し、上記の処理を再帰的に行い、フレーズテーブルの各フレーズペアに対するスコアを算出し、当該スコアを各フレーズペアに対応付けて蓄積する対訳フレーズ学習装置により、多数の適切なフレーズペアを学習できる。
(もっと読む)
機械翻訳装置及び機械翻訳プログラム
【課題】翻訳対象原文の訳文の翻訳精度や完成度が高く、しかも訳文の合成がし易くなるように翻訳用例の優先度を調整できる機械翻訳装置及び機械翻訳プログラムを提供することである。
【解決手段】翻訳用例検索手段32は翻訳対象原文に含まれる単語または文字と同一の単語または同一の文字が含まれる割合が予め定めた割合以上の翻訳用例を翻訳用例データベース29から検索し、差分対応付け手段33は翻訳用例検索手段32で複数の翻訳用例が検索された場合には各々の翻訳用例の原文と翻訳対象原文との差異部分を対応付け、用例優先度付与手段34は差分対応付け手段33で対応付けられた各々の翻訳用例の原文と翻訳対象原文との差異部分について構文上の役割を判定し構文上の役割が同じである割合が高いほど高い優先度を翻訳用例に付与する。
(もっと読む)
機械翻訳に対するパラメータの最適化
言語翻訳のための、コンピュータプログラム製品を含む、方法、システム、および装置が開示される。一実施形態では、方法が提供される。この方法は、仮説空間にアクセスするステップと、証拠空間に関して計算された分類の予想される誤りを最小化する翻訳仮説を得るために仮説空間上でデコードを実行するステップと、ターゲット翻訳において提案された翻訳としてユーザーが使用するための得られた翻訳仮説を提供するステップとを含む。 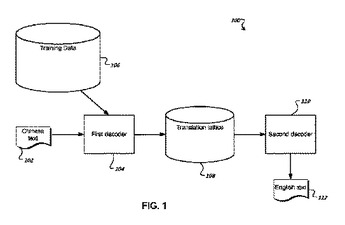 (もっと読む)
(もっと読む)
処理対象として適切なテキストを選択する技術
【課題】機械翻訳の精度の検証に適したテキストの集合を選択する。
【解決手段】複数のテキストの中から、あるフレーズが前記複数のテキストに含まれるかどうかに基づいて、出力するテキストを選択するシステムであって、前記複数のテキストのそれぞれに、予め定められた複数のフレーズのそれぞれが含まれるかどうかを判断する判断部と、前記複数のフレーズのそれぞれについて、当該フレーズを含むテキストのうち、テキスト間に予め定められた優先順位が最高のテキストに対応付けて、他のテキストと比較してより大きい指標値を算出する指標算出部と、算出した前記指標値をテキストごとに合計した合計値が、より大きいテキストを優先して選択し、選択したテキストの集合を出力する出力部とを備えるシステムを提供する。
(もっと読む)
電子機器、その制御方法、および、その制御プログラム
【課題】複数の言語が混在する文である多言語混在文に関し、種々の情報を取扱うことのできる電子機器、その制御方法、および、その制御プログラムを提供する。
【解決手段】電子機器では、入力文と翻訳文(出力文)が、出力文における優先出力言語と混在言語の割合を表わす画像(スライドバー表示部101)とともに表示される。スライドバー表示部101の中に、スライドバー102とともに、その下部に五段階で翻訳文(出力文)における言語の割合を示すための割合表示記号101A〜101Eを表示させる。スライドバー102は、割合表示記号101A〜101Eのいずれかに対応する位置に表示される。
(もっと読む)
コミュニケーションを支援する装置、方法およびプログラム
【課題】対話を円滑に行うコミュニケーション支援装置を提供する。
【解決手段】第1言語文の入力を受付ける第1言語受付部101と、第1言語文を構文解析して1または複数の単語を構成要素とする第1言語構造情報を生成する第1言語解析部102と、受付けた第1言語文を翻訳した第2言語文を生成する第2言語文生成部104と、第2言語文を受付ける第2言語受付部111と、第2言語文を構文解析して1または複数の単語を構成要素とする第2言語構造情報を生成する第2言語解析部112と、第1言語構造情報を構成する第1単語と、第2言語構造情報を構成する第2単語とを比較し、同一または類似の意味内容を含む第1単語が存在しない第2単語を抽出する抽出部131と、第2言語文を翻訳し、抽出した第2単語に対応する第3単語を、抽出した第2単語以外に対応する第4単語より優先して出力する第1言語文を生成する第1言語文生成部114と、を備えた。
(もっと読む)
翻訳機能付き携帯電話装置、音声データ翻訳方法、音声データ翻訳プログラムおよびプログラム記録媒体
【課題】マイクから入力される音声を文字変換した音声データにおける欠落部分や感情部分を補正して翻訳する翻訳機能付き携帯電話装置を提供する。
【解決手段】翻訳機能付き携帯電話装置を制御する制御部105として、ユーザの顔画像を撮影可能なカメラ部分101にて撮影したユーザの顔画像の目、眉、眉間、額、鼻、口唇のいずれか1ないし複数の各パーツ間の相対位置とその変化量を画像解析部204にて解析して、その解析結果に基づいて、表情データ抽出部205にて、マイク102から入力した音声を音声データ生成部201にて文字変換した音声データの欠落部分を抽出するとともに、当該ユーザの感情を示す表情データを生成して、文字変換した音声データの欠落部分や感情部分を音声データ補正部202にて補正した補正音声データを生成し、該補正音声データを音声データ翻訳部203にて通話相手の言語の翻訳文に翻訳して、通話相手に送信する動作を行う。
(もっと読む)
音声自動翻訳装置、音声自動翻訳方法、音声自動翻訳プログラム
【課題】処理能力の低い装置にも適用することができる翻訳の高速化方法等を提供すること
【解決手段】音声自動翻訳装置1は、単語または語句を話題別にグループ分けして登録した翻訳ライブラリ31と標準翻訳時間32を記憶する記憶部30と、入力された音声情報を音声認識してテキストを生成する音声認識手段21と、グループに設定された検索優先順に従って翻訳ライブラリを検索し、テキストを翻訳する翻訳手段22と、翻訳テキストを翻訳音声情報に変換する音声合成手段23により音声を自動的に翻訳する。検索優先順序変更手段24は、翻訳手段による翻訳に要した翻訳時間を複数回計測し、複数の翻訳時間と標準翻訳時間とを比較し、その比較結果が所定の条件を満たす場合に入力音声の話題を判定し、その判定結果に対応するグループの検索優先順を上げる方向に変更する。
(もっと読む)
機械翻訳装置
【課題】 類似概念がグループ化された階層構造のある索引付き文書の翻訳を効率良く行うことができる機械翻訳装置を提供するものである。
【解決手段】 索引構造解析部23は、第1言語で記述された原文に類似概念がグループ化された階層構造のある索引が付属している場合には索引の階層構造を解析し、その解析結果である索引のグループ情報と階層情報とを情報格納テーブル33に保持する。訳語順序調整部25は、翻訳用対訳辞書32から索引中の原語語句に対する訳語リストを取得し、情報格納テーブル33内の情報を用いて取得した訳語リストの優先順位の調節を行う。また、機械翻訳処理制御部26は訳語順序調整部25で調整された訳語リストの優先順位に基いて翻訳を行う。
(もっと読む)
翻訳情報生成装置、翻訳情報生成方法並びにコンピュータプログラム
【課題】翻訳者が翻訳を行う際に、オリジナルの電子書籍の読み進める順序と翻訳文を表示する位置とを翻訳作業において対応付けて記録することを可能とする。
【解決手段】翻訳情報入力支援装置2において、電子書籍データベース50は、文字に関する情報を含む第1の画像データを記憶する。入力部53は、ユーザの操作を受けて、表示部55により表示される第1の画像データに含まれる文字に関する情報をユーザが読み進める順に翻訳文字を表示する箇所の選択を行い、翻訳文字に関する情報の入力を行う。検出部52は、入力部53が翻訳文字を表示する箇所を選択した際に、当該翻訳文字を表示する箇所を表示位置情報として検出する。記録部54は、入力部53が入力する翻訳文字に関する情報を含み、検出部52が検出した表示位置情報が対応付けられた第2の画像データを生成し、生成した第2の画像データを生成した順に翻訳情報データベース30に記録する。
(もっと読む)
機械翻訳装置及び方法並びにコンピュータプログラム
【課題】 特に対話の様に双方向の翻訳がいつでも発生しうる環境での翻訳システムにおいて、翻訳知識を動的かつ自律的に改変できる機械翻訳装置及び方法を提供する。
【解決手段】 機械翻訳装置は、日本語と英語との間で双方向に機械翻訳を行なう機械翻訳装置であって、日本語の単語列を受け、英語の単語列への翻訳を行なって英語の単語列を出力するための日英翻訳部62と、英語の単語列を受け、日本語への翻訳を行なって日本語の単語列を出力するための英日翻訳部72と、英日翻訳部72が翻訳の際に使用する、英語から日本語への翻訳のための翻訳知識を格納するための英日翻訳知識50と、日英翻訳部62による翻訳結果を使用して、英日翻訳知識50に格納された翻訳知識を変更するための英日翻訳知識の更新部48とを含む。
(もっと読む)
翻訳装置、翻訳方法及び翻訳プログラム
【課題】複数の翻訳辞書を用いて機械翻訳する際に各辞書由来の尤度の偏りを補正して精度の高い翻訳処理を可能とすること。
【解決手段】固有表現抽出手段11で入力文に含まれる固有表現を抽出して固有表現抽出済み文を作成し、句対訳候補列挙手段25で固有表現抽出済み文を構成する各々の句に対応する句対訳候補を翻訳モデル群記憶部21から検索し、その確率値とともに対訳侯補テーブル24に記録し、辞書別重み付け手段26で重み付けテーブル23を参照して句対訳候補に対応する各翻訳辞書由来の確率値に重みを付け、最適経路探索手段27で対訳侯補テーブル24に記録された句対訳候補による組み合わせのうち、重みを付けられたそれぞれの確率値と、言語モデル記憶部22から取得した当該組み合わせにおける連続する2つの単語の確率値との積が最大となる組み合わせを求めて翻訳結果として出力する。
(もっと読む)
翻訳処理方法、文書翻訳装置およびプログラム
【課題】 高品質の翻訳文を取得する。
【解決手段】 ユーザは翻訳処理後の文書において誤訳や不適切な翻訳処理がなされている箇所がないかをチェックし、所望する編集方法に応じたアノテーションを当該翻訳後の文章に付加する。所定の指示を入力して編集対象箇所とアノテーションを確定させると、アノテーションが付加された状態の文書に対応する画像データが生成され、この画像データに対して編集処理(再翻訳処理)が開始される。文章構造解析が行われ文字情報とアノテーションとが分離され、各アノテーションに対し、そのアノテーションが付加されている対象の訳語の箇所と当該アノテーションの種類とが判別される。続いて、翻訳規則テーブルTrを参照し、判別されたアノテーションの種類に対応する編集方法を特定し、当該編集方法に従って編集処理(再翻訳処理)を行い、所定の方法で出力する。
(もっと読む)
1 - 14 / 14
[ Back to top ]