
Fターム[5D015BB02]の内容
Fターム[5D015BB02]に分類される特許
1 - 20 / 46
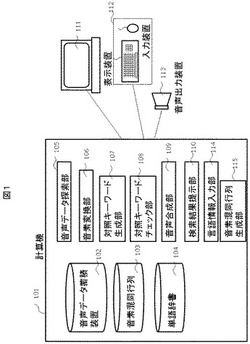
音声データ検索システムおよびそのためのプログラム
【課題】
音声データ検索システムにおいて、検索結果の正解/不正解の判定を容易に行うことができるようにする。
【解決手段】
音声データ検索システムにおいて、キーワードを入力する入力装置112と、入力された前記キーワードを音素表記へ変換する音素変換部106と、音素表記のキーワードを元に音声データ中で当該キーワードが発話された個所を検索する音声データ探索部105と、ユーザごとの音素混同行列103に基づいて、ユーザが聴取混同する可能性のある対照キーワードの集合を生成する対照キーワード生成部107と、前記音声データ探索部105からの検索結果および前記対照キーワード生成部107からの前記対照キーワードをユーザへ提示する検索結果提示部110を備える。
(もっと読む)
音声認識装置、方法及びプログラム

【課題】音声認識精度を向上することにある。
【解決手段】一実施形態に係る音声認識装置は、業務推定部、音声認識部及び特徴量抽出部を含む。業務推定部は、利用者の業務に関連する非音声情報を用いて利用者が行っている業務を推定し、該業務の内容を示す業務情報を生成する。音声認識部は、前記業務情報に対応する音声認識手法に従って前記利用者が発した音声情報に対して音声認識を行い、音声認識結果を生成する。特徴量抽出部は、前記音声認識結果から、前記利用者が行っている業務に関連する特徴量を抽出する。前記業務推定部は、少なくとも前記特徴量を用いて前記利用者の業務を再推定し、前記音声認識部は、再推定の結果得られる業務情報に基づいて音声認識を行う。
(もっと読む)
音声認識装置、音声認識方法及びプログラム
【課題】様々な分割の粒度に対応した音声単位列を取得し、そのうちから音声データに対応する音声単位列を登録する。
【解決手段】音声入力部201は、音声データを入力する。分割部203は、分割の粒度に係る複数の変数を設定し、変数毎に前記音声データを複数の区間に分割する。認識部204は、変数毎に前記各区間の音声単位を認識する。接続部205は、変数毎に各区間の音声単位を接続することにより、前記変数毎の音声単位列を取得する。尤度計算部206は、変数毎の音声単位列の夫々について音声データに対する尤度を計算する。登録部207は、計算された尤度に基づいて、変数毎の音声単位列から前記音声データに対応する音声単位列を登録する。
(もっと読む)
音声認識装置
【課題】図1に示される構成と同様の構成を有するシステムの確度を高めて計算負荷を軽減し、それによってレスポンスを高速化したり、処理能力がさほど強力でないハードウェアを使用できるようにすること。
【解決手段】音声認識方法は表音認識器によって出力される表音シーケンスを受け取る工程を含む。方法は、参照リストに格納された複数の参照音素シーケンスの内の、表音シーケンスに最もぴったり合った1つと表音シーケンスを突き合わせる工程も含む。参照リストに格納された複数の参照音素シーケンスの内の少なくとも1つは、表音認識器によって出力され得る表音シーケンスに関する付加情報を含む。
(もっと読む)
音声認識装置、音声認識方法、及びプログラム
【課題】発音の変化にも対応可能な音声認識装置を提供する。
【解決手段】音響モデル記憶部11、辞書情報記憶部12、音声信号に応じた特徴量を受け付け、音響モデル、辞書情報、辞書情報に含まれる音素列に関する言語モデルである音素列言語モデルを用いて、特徴量に対応する確率の高い音素列の並びを取得する取得部16、音素の並びと、音素の並びに対応する文字列の並びとを対応付けるパラレルコーパスから生成された変換モデルが記憶される変換モデル記憶部17、文字列言語モデルが記憶される文字列言語モデル記憶部18、変換モデルと文字列言語モデルを用いて、取得された音素列の並びに対応する文字列の並びのうち、確率の高いものを選択することによって、音素列の並びを文字列の並びに統計的に変換する変換部19、変換後の文字列の並びである音声認識結果を出力する出力部20を備える。
(もっと読む)
音声認識エラー予測値としての文法適合度評価のための方法およびシステム
【課題】音声認識システムに使用する、文法の適合度を評価する技術を提供する。
【解決手段】文法構造内から複数のステートメントを受け取る(701)。前記ステートメントを単語セット単位で整合させることによって、前記ステートメントにわたって幾つかのアライメント領域が特定される(703)。前記ステートメントにわたって、幾つかの混同可能性ゾーンが特定される(705)。前記特定された混同可能性ゾーンのそれぞれについて、当該混同可能性ゾーン内の単語の音声的発音が解析され、前記演算イベント中に音声認識システムによって聴取できる状態で処理される際の、前記単語間の混同確率の尺度が決定される(707)。文法構造の改善を容易にするために、前記ステートメントにわたる前記混同可能性ゾーンの識別子と、その対応する混同確率の尺度とが報告される(709)。
(もっと読む)
音声検索装置および音声検索方法
【課題】辞書に存在しない未知語あるいは認識誤りを含む大量の音声データから、音声およびテキスト入力による音声検索装置および音声検索方法を提供すること
【解決手段】音声あるいはテキストによる検索入力により、前記入力からの音声データを認識する大語彙連続音声認識において未知語に索引を付与し、さらに未知語の音声データに対して未知語もしくは検索語を音素あるいは音節に分割し、前記未知語の索引に対して複数の検出候補を生成することにより、辞書に存在しない未知語あるいは認識誤りを含む大量の音声データから検索結果を提示する。
(もっと読む)
線形分類モデルに基づく音響モデルパラメータ学習方法とその装置、音素重み付き有限状態変換器生成方法とその装置、それらのプログラム
【課題】音響モデルと言語モデルを同一のモデルで表現する。
【解決手段】この発明の音響モデルパラメータ学習方法は、モデルパラメータ初期化過程とモデルパラメータ更新過程を含む。モデルパラメータ初期化過程は、認識スコアを求めるモデルパラメータを初期化する。モデルパラメータ更新過程は、特徴量ベクトルを入力としてその特徴量ベクトルとモデルパラメータの内積値の累積に基づく目的関数が外部から与えられ、その目的関数を最大化するモデルパラメータを、上記初期化されたモデルパラメータを更新して求め、各音素に対応する所定フレーム数から成る部分モデルパラメータを出力する。
(もっと読む)
音声認識装置、音声認識方法、及び音声認識ロボット
【課題】未登録語を登録する際、ユーザが音声のみを用いて認識した音韻を訂正することができる音声認識装置、音声認識方法、及び音声認識ロボットを提供する。
【解決手段】音声入力部は音声を入力し、音韻認識部は入力された音声の音韻を認識して訂正発話を示す第1の音韻列を生成し、マッチング部は第1の音韻列と元発話を示す第2の音韻列とをマッチングを行い、音韻訂正部はマッチングを行った結果に基づき第2の音韻列の音韻を訂正する。
(もっと読む)
音声認識装置およびプログラム
【課題】実際の発声強度に適切な音響モデルを利用して高精度な音声認識を実現する。
【解決手段】強度測定部34は、音声信号Vの観測強度Pを順次に測定する。第1照合部42は、相異なる発声強度Lに対応する複数の音素モデルMPの各々と音声信号Vとを照合する。相関特定部44は、強度測定部34が測定した観測強度Pと複数の音素モデルMPのうち音声信号Vの出現確率λが最大となる音素モデルMPに対応する発声強度Lとに基づいて、観測強度Pと発声強度Lとの関係を規定する強度テーブルTBL1を生成する。記憶装置24は、相異なる発声強度Lに対応する複数の音素モデルMPが音素毎に設定された音響モデルMを記憶する。第2照合部46は、音響モデルMの各音素に設定された複数の音素モデルMPのうち、強度測定部34が測定した観測強度Pに強度テーブルTBL1にて対応する発声強度Lの音素モデルMPを利用して、音声信号Vと音響モデルMとを照合する。
(もっと読む)
音素分割装置、方法及びプログラム
【課題】音素境界時刻の推定を従来よりも精度良く行なう。
【解決手段】マッチングスコア計算部3及び音素境界候補計算部5が、予め推定された初期音素境界に対応する複数のスペクトルテンプレートを用いて、その初期音素境界についての音素境界候補をひとつ以上決定する。最適音素境界探索部6が、連続するR個の音素を区切る音素境界候補の組が複数ある場合には、それらの連続するR個の音素の全体を考慮して最適な音素境界候補の組を選択する。これにより、音素境界の推定の精度が従来よりも高くなる。
(もっと読む)
電子辞書で音声認識を用いた単語探索装置及びその方法
【課題】電子辞書の音声認識機能にN−best認識結果を出力して単語検索を迅速に行える電子辞書で音声認識を用いた単語探索装置及びその方法を提供する。
【解決手段】本発明は電子辞書で音声認識を用いた単語探索技術に関するものであり、音声認識誤りが発生しても多数の音声認識候補(N−best)に対する認識結果を出力してユーザがそのうちの1つを選択できるようにすることで、音声認識誤りの不便さを軽減し、特に英韓辞書の検索において、本来の辞書的単語の発音はもちろん、発音を知らない場合にアルファベットの連続発音の組み合わせをその単語の発音として認識できるように発音の変移を多重で提供してユーザが発音を知らない英文単語でも音声で容易に検索することを特徴とする。本発明によれば、既存の英語アルファベット単位の音声認識方法に比べて高い正確率で英韓辞書の検索を非常に迅速に行うことができ、音声認識誤りが発生してもN−best候補から正解を選択でき、電子辞書のユーザ利便性を大幅に改善できる。
(もっと読む)
サンプルを用いずあらゆる言語を識別可能な識別方法
【課題】ある連続音の特徴を改善し、あらゆる言語文を正しく識別でき、よって、サンプルを用いず、台湾中国語、英語、日本語、ドイツ語、フランス語、韓国語、ロシア語、広東語、台湾語等のすべての言語を識別可能なあらゆる言語を識別可能な識別方法を提供する。
【解決手段】ある連続音(word)が1個以上の単音を含み、あらゆる言語のある連続音の特徴は、あらゆる言語の未知の連続音から抽出し、これら未知の連続音は、マトリックス値を用いて表示し、144次元空間内に散布され、あらゆる言語の既知の連続音の特徴は、144次元空間に散らばり、知の連続音周囲の未知の連続音の特徴によりシミュレート及び計算され、本発明は12個の弾性フレームを含み、長さが等しく、フィルターが無く、オーバーラップせず、ある連続音を、長さがさまざまな音波(さまざまな音節数を持つ)12×12マトリックスに転換し、ベイズ識別法により比較識別する。
(もっと読む)
音声認識装置およびそれを用いたナビゲーション装置
【課題】ユーザが発話する認識単位を誤認識することなく高精度に認識する音声認識装置およびそれを用いたナビゲーション装置を提供する。
【解決手段】音声認識装置は、次にマイクから入力される音声信号を格納するために音声バッファを空にし(S400)、一定時間間隔でスピーカからテンポ音を発生させるテンポ信号が出力されるまで(S404:Yes)、マイクから入力される音声信号を音声バッファに格納する(S402)。音声バッファにユーザの発話が入っている場合(S406:Yes)、音声認識装置は、予め指定されたユーザが発話する認識単位、例えば1桁の数字または1モーラに基づいて、音声バッファに入っている音声信号と標準音声パターンとを比較し、認識単位毎に音声信号を認識する(S408)。音声認識装置は、一つの認識単位で音声信号を認識すると、S400に処理を移行し、次のテンポ信号まで音声信号を音声バッファに格納する。
(もっと読む)
パターン認識方法および装置ならびにパターン認識プログラムおよびその記録媒体
【課題】認識率を低下させることなく状態仮説を効率良く枝刈りできるパターン認識方法および装置ならびにパターン認識プログラムおよびその記録媒体を提供する。
【解決手段】第2探索部15において、尤度計算部151は、第2データベース20に記憶された木構造辞書および第3データベース21に記憶された音響モデルに音響特徴パラメータの時系列データを照合させて音響的な尤度を算出し、この尤度を時間方向に累積して累積尤度を求める。自己遷移部152は、探索過程で各状態仮説を自己遷移させる。LR遷移部153は、探索過程で各状態仮説をLR遷移させる。報酬付与部154は、探索過程において各状態仮説に、到達可能な単語数に応じた報酬を加算して累積尤度を嵩上げする。枝刈り部155は、探索過程で尤度の低い状態仮説を探索対象から除外する。
(もっと読む)
音素分割装置、方法及びプログラム
【課題】音素境界時刻の推定を従来よりも精度良く行なう。
【解決手段】入力された音声の各フレームの音声特徴量を抽出する。複数の音素の音声特徴量についての統計量を用いて、各フレームに最も尤もらしい音素を割り当てて、連続する2つのフレームで割り当てられた音素が異なる場合に、それらの2つのフレームに亘る時間範囲に含まれる時刻の何れかを音素境界時刻とすることにより音素境界時刻を推定する。音素境界時刻が信頼できるかどうか判定する。音素境界時刻が信頼できないと判定された音素境界を構成する各音素に、その各音素の継続長の、平均値が大きいほど長く、分散が大きいほど大きく伸縮した時間を割り当てることにより、その音素境界時刻が信頼できないと判定された音素境界の音素境界時刻を推定する。
(もっと読む)
単語のセットを対応するパーティクルのセットに変換する方法
【課題】自動音声認識(ASR)システムの性能を改善し、認識時間を減少する。単語数と比較してパーティクル数を減少し、スループットも同様に増大する。再現率によって測定されるIRシステムの性能も改善する。
【解決手段】単語のセットが対応するパーティクルのセットに変換される。単語及びパーティクルは、各セット内で一意である。単語毎に、この単語の、パーティクルへの全ての可能性のある分割を求め、可能性のある分割毎のコストを求める。最小コストに関連付けられる、可能性のある分割のパーティクルをパーティクルのセットに追加する。
(もっと読む)
音声認識装置、音声認識プログラム、および音声認識方法
【課題】短い語を表す複数の冗長な表現の音声データを認識できるようにする。
【解決手段】情報処理装置10は、音節数閾値以下の音節数を有する複数の短い語と、その短い語を説明するための、その短い語を含みその短い語の音節数より多い音節数をそれぞれ有する複数の冗長な音素データ列とを対応づけて格納する辞書データベース36と、音素認識部によって生成された冗長な音素データ列を認識し、さらに、その辞書データベースを検索して、その認識された冗長な音素データ列に対応する冗長な音素データ列に対して、その冗長な音素データ列に対応づけられた短い語を出力する音素データ認識部30と、を含む。
(もっと読む)
音響モデル作成装置、その方法及びプログラム
【課題】Viterbiアルゴリズムによる高速性を担保しつつ、学習精度が向上された音響モデル作成装置を実現する。
【解決手段】音声信号から音声特徴量系列otを抽出する特徴量分析部と音声信号に対応する学習ラベルを音素系列に分解し更に状態系列に変換する状態系列変換部と音響モデルを記憶する音響モデル記憶部と音声特徴量系列otと状態系列とから状態系列に対応する音響モデルを用いて前向き計算を行い前向き計算履歴を出力する前向き計算部と前向き計算履歴から最尤パスを求めこれを辿りながら十分統計量を蓄積する十分統計量蓄積部と十分統計量から学習後音響モデルを構築しこれにより音響モデルを更新するモデル更新部とを備え、十分統計量蓄積部での十分統計量の蓄積に際して用いる事後確率変数の値は最尤パスが時刻tに状態iを通る場合には状態出現確率fi(ot)(0≦fi(ot)≦1)でありそれ以外の場所では0である。
(もっと読む)
有限状態トランスデューサ決定化装置及び有限状態トランスデューサ決定化方法
【課題】事前処理なしに単値でないNFSTを決定化すること。
【解決手段】有限状態トランスデューサが有する状態のうち、同一の入力記号により遷移する複数の状態を抽出して併合する状態併合部と、併合前の前記複数の状態のそれぞれから次の状態への遷移毎に対応する識別記号を、前記次の状態への入力記号として付与することにより決定化する記号決定部と、を有し、前記識別記号は、前記有限状態トランスデューサが有する遷移に割り当てられている入力記号とは異なる記号であることを特徴とする。
(もっと読む)
1 - 20 / 46
[ Back to top ]