
Fターム[5D015LL07]の内容
Fターム[5D015LL07]の下位に属するFターム
キー入力装置 (26)
Fターム[5D015LL07]に分類される特許
21 - 40 / 87
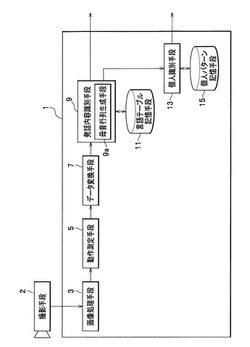
発話内容識別装置及び個人識別装置
【課題】口唇動作から発話内容を識別する際の識別誤差を小さくすることができる発話内容識別装置及び口唇動作の特徴から個人を識別することができる個人識別装置を提供する。
【解決手段】発話内容識別装置1は、撮影手段2で撮影された、発話者が発話している際の口唇部分の映像から当該発話者の口唇動作を得て、この口唇動作から発話内容を識別するものであって、口唇部分の特徴点の位置を抽出する画像処理手段3と、動作履歴グラフを測定する動作測定手段5と、動作スペクトルグラフに変換するデータ変換手段7と、母音行列を生成する母音行列生成手段9aと、発話内容を識別する発話内容識別手段9と、を備えた。
(もっと読む)
利用者と対話する装置、方法およびプログラム

【課題】自然な対話を実現することができる対話装置を提供する。
【解決手段】応答と、表示部136に対する注視度と、スピーカ134および表示部136に対する応答の出力方法とを対応づけて記憶する応答記憶部154と、音声を受付ける音声受付部103と、受付けた音声を認識する認識部104と、認識結果から要求を抽出する抽出部106と、抽出された要求に基づいて応答を決定する応答決定部107と、利用者の視線方向を検出する方向検出部101aと、検出した視線方向に基づいて注視度を決定する注視度決定部102と、決定された応答と決定された注視度とに対応する出力方法を応答記憶部154から取得し、取得した出力方法で、スピーカ134および表示部136に応答を出力する出力制御部120と、を備えた。
(もっと読む)
言語発音練習支援システム
【課題】相手に言葉が通じ会話できるように、正しい発音を身に着ける練習をしていく、言語の習得を支援する。
【解決手段】発音評価装置45による画像解析技術を組み合わせ、唇の動きを追跡、解析する。つまり、音声評価判定処理部44による音声データに対する音声処理だけでなく、唇の動きを撮影したビデオデータを合わせて解析するものである。これにより、正確な発音の判定が可能になる。
(もっと読む)
画像出力装置及び画像出力方法
【課題】 プレゼンテーションの内容に沿ってプレゼンテーション画像データの切り替えを行うことができる画像出力装置及び画像出力方法を提供する。
【解決手段】 プレゼンテーション装置110は、第1ページのプレゼンテーション画像データ201を出力している際に、プレゼンテーションの説明者により入力された音声の認識結果が第1ページのプレゼンテーション文書データに含まれるページ切り替えのための文字列と一致した場合に、投影装置107へ出力する画像データを、第1ページのプレゼンテーション画像データから第2ページのプレゼンテーション画像データに切り替える。
(もっと読む)
映像を用いた発音の推定方法
【課題】ヒトの映像を用いることにより、周囲の雑音等に左右されることなく、発言者の発音および発言内容を推定する方法を提供する。
【解決手段】ヒトの顔の映像を用いて、口唇の輪郭形状を所定の単位時間毎に計測し、その形状の特徴を、フーリエ記述子法により有限個のフーリエ記述子として定量化し、これらの値を記録した後、所定のフーリエ記述子のデータを用いて、その値の変化により該ヒトの発音の開始点および終了点を判定するとともに、これら開始点から終了点までの間における前記所定のフーリエ記述子を含む複数個のフーリエ記述子のデータを用いて、回帰計算により近似のn次多項式を算出し、これらのフーリエ記述子の個々について、n+1個の係数を取得してから、これら各係数と、母音および子音ごとにあらかじめ定めておいた各係数の標準値とを、線形判別関数を用いて比較することにより、前記ヒトが発言した文字を推定する。
(もっと読む)
音声認識装置
【課題】ユーザにとって使い勝手のよい音声認識処理を行う。
【解決手段】ユーザへの問い掛けに応じて、音声信号取得手段から非言語が入力された場合には、この非言語が入力された際の状況に応じて、非言語の入力の有効性を判断し、有効性の判断結果に応じて、作業内容の確認、作業内容の保留、および、作業内容の実行のいずれかを判断する。
(もっと読む)
行き先設定装置及び行き先設定方法
【目的】1回の発声でナビゲーションにおける行き先を正しく音声認識できるようにする「行き先設定装置及び行き先設定方法」を提供することである。
【構成】音声認識により行き先をナビゲーション装置に設定する際、音声認識エンジン12は入力された行き先音声を認識し、音声録音部13は該行き先音声を録音する。音声認識エンジン12は行き先を正しく認識できなければ、行き先を絞り込むために入力された絞込み情報(都道府県など)を考慮して録音されてある行き先音声を再度音声認識して行き先をナビゲーション装置10に設定する。
(もっと読む)
コンピュータ実装方法
【課題】
背景技術の問題点を解決するコンピュータ実装方法を提供する。
【解決手段】
第1の文書のテキストに関連付けられた第1の符号化を含む前記第1の文書を作成するために、発話のオーディオストリームに自動音声認識機能を適用するステップと、
前記第1の文書を自動決定サポートシステムに提供するステップと、
前記自動決定サポートシステムから、前記第1の文書から派生した決定サポート出力を受信するステップと、
前記第1の文書および前記決定サポート出力から派生した第2の文書を受信者に送信するステップと、を含み、前記第2の文書は前記第1の符号化を含まないものである。
(もっと読む)
メディア表現文書情報生成システム
【課題】発話者が発言するときの感情を反映した感情表現文書を容易に生成する感情表現文書情報生成システムの提供
【解決手段】文脈・感情情報取得装置23は、カメラ25及びマイクロフォン27から映像情報、音声情報を取得すると、文脈情報「今日は良い天気だね」、感情ベクトル(笑い、怒り、悲しみ)を取得する。メディア表現文書情報生成装置21は、文脈情報から主単語を「天気」に決定する。また、感情ベクトルから感情方向ベクトル(θ、φ)、感情の強さを取得する。さらに、対応する感情反映パラメータ及び感情反映ロジックを取得する。さらに、取得したメディア表現に対して、感情方向ベクトル(θ、φ)、感情の強さ、及び設定パラメータIDを用いて、感情反映ロジックに対するメディア表現情報の調整を行う。そして、調整したメディア表現、文脈情報「今日は良い天気だね」、及び主単語情報「天気」に基づいてメディア表現文書を生成する。
(もっと読む)
省略語補完装置、省略語補完方法、及びプログラム
【課題】2人以上のユーザが会話している状況において、省略語をより適切に補完できる省略語補完装置等を提供する。
【解決手段】2人以上のユーザが会話している状況における、少なくとも1人のユーザの発した音声を示す音声情報を受け付ける音声情報受付部11と、音声情報を対応する文字情報に変換する文字情報変換部13と、文字情報の示す文書において省略された格要素であるゼロ代名詞を特定するゼロ代名詞特定部14と、2人以上のユーザの位置に関する情報であるユーザ位置情報を少なくとも含む情報であり、その2人以上のユーザの行動に関する情報である行動情報を受け付ける行動情報受付部15と、行動情報を用いてゼロ代名詞の位置に省略語を補完した補完文字情報を生成する省略語補完部21と、補完文字情報を出力する補完文字情報出力部22と、を備える。
(もっと読む)
音声認識装置および音声認識方法、並びにプログラムおよび記録媒体
【課題】音声認識精度を向上させる。
【解決手段】距離計算部47は、発話を行っているユーザからマイク21までの距離を求め、音声認識部41Bに供給する。音声認識部41Bは、複数の異なる距離だけ離れた位置から発せられた音声を収録した音声データそれぞれから生成された、音響環境を考慮した音響モデルのセットを記憶している。そして、音声認識部41Bは、その複数の音響モデルのセットの中から、距離計算部47から供給される距離に最も近い距離の音響モデルのセットを選択し、その音響モデルのセットを用いて、音声認識を行う。
(もっと読む)
画像処理装置および画像処理のプログラム
【課題】 入力される音声情報を極めて高い音声認識率で認識して、使用者の操作を必要とすることなく自動的に文字情報に変換する。
【解決手段】 制御部1は、webページ取得部10によって、ネットワークから得られるwebページに含まれている画像情報をHTML解析部11および画像データ解析部12によって解析し、画像情報から抽出した文字列をキーワードリスト保存部13に登録する。そして、音声入力部5から入力された音声がキーワードリスト保存部13に登録されているいずれかの文字列と一致するか否かを音声認識部6によって判断して、一致すると判断した場合には、文字描画部7によって文字列をビットマップの文字画像に変換し、認識された音声に対応する映像と文字画像とを文字合成部8によって合成して新たな画像情報を生成する。
(もっと読む)
変化情報認識装置および変化情報認識方法
【課題】 認識対象物の変化状態を正確に認識して、たとえば人の話す言葉などを認識することができるようにした変化情報認識装置および変化情報認識方法を提供する。
【解決手段】 変化情報認識装置1は、撮像手段で撮像された動画などの系列情報を記憶する系列情報記憶装置11とその系列情報の変化に対応する変化情報をあらかじめ記憶する基本変化情報記憶装置12を備える。系列情報記憶装置11は系列情報を変化状態比較装置13に出力し、基本変化情報記憶装置12は、基本変化情報を変化状態比較装置13に出力する。本科状態比較装置13では、出力された変化情報と基本変化情報とを比較することにより、変化情報の変化状態を検出する。
(もっと読む)
認識辞書システムおよびその更新方法
【課題】言い換え語彙の発生状況を検出し、発生した言い換え語彙を登録するために認識辞書を更新することで、発生した言い換え語彙を認識できる認識辞書システムおよびその更新方法を提供することにある。
【解決手段】本発明に係る認識辞書システムは、ユーザからの入力情報に対応する第1の語彙が、文字列情報を記憶した認識辞書に記憶された第2の語彙と等価の意味を持ち、異なる文字列情報を持つ場合に、第1の語彙を第2の語彙と対応付けて言い換え語彙として累積記憶し、累積された言い換え語彙の発生頻度が第1の所定値より高い言い換え語彙の少なくとも一つを主要言い換え語彙と判断し、主要言い換え語彙を第2の語彙と対応付けて認識辞書に登録する。
(もっと読む)
ロボット装置の制御装置および方法
【課題】音声認識機能を備えるロボット装置の音声コマンドの誤認識を低減する。
【解決手段】ユーザ10の音声コマンドを認識してロボットを駆動するロボット装置の制御装置において、ユーザの顔を撮像するカメラ2と、カメラの画像からユーザの口が動いているかどうかを判定し、口が動いていると判定している間のみ音声認識部6へ口動作検出信号4を発行する判定部3と、を備え、音声認識部6は、口動作検出信号4が入力されているときの音声コマンドのみを認識し、駆動制御部12に動作コマンドとして発行するよう構成した。
(もっと読む)
情報処理装置及び情報処理方法
【課題】 認識語彙が提示されないと、音声認識を行うときに、何が入力できるかわからない場合がある。一方、常に認識語彙が提示されていると、音声認識を行わないユーザにとっては、冗長な画面表示になる。
【解決手段】 音声認識機能を備えた情報処理装置であって、上記目的を達成するために、本発明に係る情報処理装置は、音声処理開始指示操作を検出する検出手段と、情報の表示を制御する表示制御手段とを備え、前記表示制御手段は、前記検出手段による音声処理開始指示操作の検出に応じて、認識対象語を表示するように制御することを特徴とする。
(もっと読む)
自動音声認識システムにおける孤立語句コマンド認識及び接続語句コマンド認識の同時対応
【課題】音声入力を用いて1つ以上の装置を動作するためのシステム。
【解決手段】音声入力を受信するための受信器と、前記受信器と通信する制御器と、前記音声入力をコンピュータ読取可能なデータに変換するための前記制御器上で実行されるソフトウェアと、前記システムの全ての有効コマンドの一部を含むアクティブコマンドテーブルを生成するための前記制御器上で実行されるソフトウェアと、前記データによって示された少なくとも1つのアクティブコマンドを識別するための前記制御器上で実行されるソフトウェアと、前記アクティブコマンドによって動作可能な少なくとも1つの装置に前記アクティブコマンドを送信するための前記制御器上で実行されるソフトウェアとを具備する。
(もっと読む)
ロボットおよび音声認識装置ならびにその方法
【課題】音声認識の精度を向上させることにより、誤動作の発生を低下させることのできるロボットおよび音声認識装置ならびにその方法を提供することを目的とする。
【解決手段】マイクロフォン14と、マイクロフォン14から入力された音声を認識する音声認識部50と、ロボット本体周辺の人物を検知する人物検知部51aと、人物検知部51aにより人物が検知された場合に、音声認識部50による音声認識結果を有効とする音声認識採否判断部53と、音声認識採否判断部53により音声認識結果が有効とされた場合に、該音声認識結果に対応する応答動作を実行する応答動作実行部53とを具備するロボットを提供する。
(もっと読む)
情報認識装置及び情報認識プログラム
【課題】映像コンテンツを検索する際、音声から抽出された単語候補、デジタルボード等に入力された筆記情報から抽出された単語候補、筆記授業マテリアル等のテキスト中に出現する単語の出現位置・順序・頻度等を用いることにより、検索時に用いる映像箇所を示すタグの付与を正確に行い、ユーザにとって簡便に必要な映像箇所が検索できるようにする。
【解決手段】授業用マテリアルであるテキストから単語抽出を行い、抽出された単語の出現位置・順序・頻度、授業・講演と同時に収録される筆記情報等から抽出される単語情報と音声情報から抽出される単語情報の位置関係を用いて、映像箇所にタグを付与する装置であって、授業・講演との関連情報を用いて音声認識率を向上させ、付与するタグの精度を向上させる。
(もっと読む)
個人認証・識別システム
【課題】 誤識別率の小さい、かつ顔写真や録音された本人の声で詐称できない顔画像と音声を統合した個人認証・識別装置を提供することにある。
【解決手段】 撮像部1から出力されたユーザの顔画像と音声に分離される。顔画像照合部14は、顔画像特徴量抽出部12によって顔画像の静止画像から抽出された特徴量と、予め登録されている個人顔画像データ15とを照合し、尤度αを出力する。一方、音声照合部23は、音声特徴量抽出部22によって音声から抽出された特徴量と、予め登録されている個人音声データ24とを照合し、尤度βを出力する。尤度統合部4は、該尤度αとβを統合して統合尤度を出力し、認証・識別判定部6は該統合尤度を基にユーザの認証及び/又は識別判定をする。前記尤度α、βは、明るさ測定部16からの顔画像の明るさ、背景雑音測定部25からの背景雑音の大きさにより閾値を変えられる。
(もっと読む)
21 - 40 / 87
[ Back to top ]