
Fターム[5L096BA16]の内容
イメージ分析 (61,341) | 入力画像・用途の種類 (5,501) | 特定画像 (1,491) | 音声 (62)
Fターム[5L096BA16]に分類される特許
41 - 60 / 62
動作分析装置

【課題】 動作確認の担当者の負担を軽減し、作業効率を向上できる動作分析装置を提供する。
【解決手段】 人物を撮像して得られた一連のフレーム画像データを含んでなる動画像データについて、フレーム画像データごとに、撮像された人体の所定一部が撮像されている画像領域を少なくとも一つ検出する。また、当該検出した人体の所定一部等に基づき、少なくとも一つの特徴量情報を生成し、当該特徴量情報が所定の条件を満足するタイミングでのフレーム画像データを特定する情報を特徴時点情報として生成し、この特徴時点情報が、動画像の表示の処理に供される動作分析装置である。
(もっと読む)
人物追跡システム

【課題】画像と音声を同時に利用するとともに能動的な追跡方式として着目追跡対象人物の同定の確実性を高めること。
【解決手段】探査用音源1,2、探査用受音器3〜5、応答音源6〜8は、応答音源システムを構成し、追跡対象人物A〜Cの位置を特定する。処理手段17は、例えば探査用音源1から探査音波が発生された時刻から応答音源6からの応答音波が探査用受音器3〜5で受音された時刻までの時間に基づいて応答音源6の位置を特定する。また、処理手段17は、応答音源6の位置と撮像手段14〜16が撮像した画像における画像的特徴領域とに基づいて画像中の画像中の追跡対象人物Aの画像領域を特定するとともに、受音器9〜13で受音した音声中の追跡対象人物Aの音声を応答音源6の位置を用いて分離する.
(もっと読む)
音声通話装置および音声通話システム
【課題】 発話者の無声音声と発声時の口唇の動画情報を利用して、通常の有声音を含む発話時に想定される音声を合成する音声通話装置および音声通話システムを提供することを目的とする。
【解決手段】 音声通話装置は固定電話や携帯電話等であり、マイクロフォン100と音声信号分析器101、カメラ102、映像信号分析器103、音声信号合成器104、辞書情報データベース105から構成されている。マイクロフォン100は、音声を入力するためのものであり、マイクロフォン100から入力された音声(ここでは、無声音)が音声信号分析器101へ送信される。音声信号分析器101は、マイクロフォン100から入力された無声音で主に子音に関する情報が抽出される。
(もっと読む)
情報処理装置、情報処理方法およびプログラム
【課題】 振り返りを支援できる情報処理装置を提供することを目的とする。
【解決手段】 マルチモーダル認識部3は、挙手、起立、板書などの動作解析などの画像処理、話者交代、話者同定や、キーパーソンの抽出などにより会議の重要部分を観測し、時間ごとの重要度重みを算出する。次に、マルチモーダル認識部3は、この重要度重みを発話単位毎に集計し、会議の重要部分を同定する。また、マルチモーダル認識部3は、所定区間内で、発話単語数、言い淀みの感動詞、声量、声量の変化率、音声のピッチ変化、顔の傾きを、所定の重みで換算し、場面ごとの重要度係数を算出する。次に、マルチモーダル認識部3は、この重要度係数に基づいて、場面ごとにキーパーソンを推定する。
(もっと読む)
個人認証装置、個人認証処理方法、そのためのプログラム及び記録媒体
【課題】時系列の動画像を用いて、高精度な個人認証を実現する。
【解決手段】ユーザの発語時の時系列の顔画像を取得する手段と、前記時系列の顔画像にもとづいて、人物認証を行う手段を設ける。ここで、前記人物認証を行う手段は、例えば、前記時系列の顔画像を構成するフレーム画像から、顔面の特徴点を抽出する手段と、前記特徴点のフレーム内での変位を検出する手段と、前記変位と所定値との類似度を評価する手段からなる。
(もっと読む)
図形中心線算出装置、声道断面積関数算出装置及びコンピュータプログラム
【課題】画像内の図形の中心線を正確に検出することができる装置を提供する。
【解決手段】コンピュータ読取可能なMRI画像内の声道の中心線を検出するための装置は、声道断面形状の声帯位置を定める線分を決定する処理部302と、線分に対し一方向に存在する画素で、上記線分からの距離が互いに等しい画素からなる画素群の各々の重心位置を算出する処理部304〜306と、算出された重心位置に対し区分近似関数を適用して声道中心線を求める処理部310とを含む。
(もっと読む)
画像認識装置及び画像認識プログラム
ネット等の障害物で区画された領域間で対戦するスポーツを記録したコンテンツから選手の動作を認識する画像処理装置であって、前記コンテンツから少なくとも一方の選手の動作が映った映像情報を取得する映像情報取得部と、前記領域間を移動するボール等の使用用具の打撃時に発生する打撃音等の前記映像情報と同期した音響情報を前記コンテンツから取得する音響情報取得部103と、前記音響情報に基づき前記使用用具を打撃した打撃時刻を特定する打撃時刻情報特定部105と、当該スポーツのルール情報を格納するルール情報格納部102と、前記映像情報と前記打撃時刻における使用用具の位置と前記ルール情報とに基づき、その映像情報が示す選手の動作を含む画像内容を認識する画像内容認識部106を備える。  (もっと読む)
(もっと読む)
発声内容認識装置
【課題】 発声者が収音器の近くにおらず低精度の音声認識が行われることを抑制すること。
【解決手段】 収音する収音器16と、収音器16に対し音声を発する発声者の画像を撮影する撮影機18と、前記収音される音声に基づく音声認識を行う音声認識機能部132と、前記撮影される画像に前記発声者の少なくとも一部を示す発声者画像が含まれていない場合に、音声認識機能部132が音声認識を行うことを制限する認識・学習判定部142と、を含むことを特徴とする発声内容認識装置10。
(もっと読む)
照合装置及び登録装置
セキュリティの向上、照合処理の高速化、個人を確認する情報を伝送する通信路の負荷軽減を図ることができる照合装置を提供する。これにより、着脱可能な可搬記憶媒体3を有し、サーバ4とネットワークで接続された照合装置2であって、マルチメディア情報取得部21で取得した個人を確認する情報を、複数の場所に分散配置された記憶部23,31,41の中に予め格納されている照合用の個人を確認する情報のそれぞれと照合処理P1,P2,P3で段階的に照合するにより問題の解決を図る。 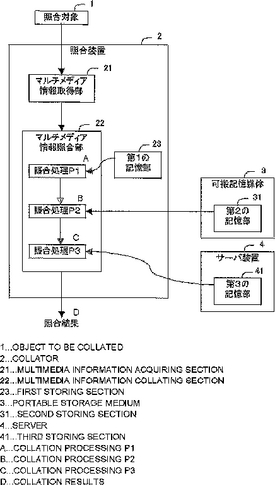 (もっと読む)
(もっと読む)
データのストリームにおけるセグメント境界の位置の決定方法、データサブセットを近隣のデータサブセットと比較してセグメント境界を決定する方法、コンピュータによって実行可能な命令のプログラム、ならびにデータのストリームにおける境界及び非境界を識別するシステム又は装置
【課題】データのストリームにおけるセグメント境界の位置の決定方法を提供する。
【解決手段】本決定方法は、(a)前記データのストリーム内のデータサブセットを、現在及び未来のデータサブセットの群から選択された1つ以上のデータサブセットと比較することによって1つ以上の類似度値を決定することであって、前記未来のデータサブセットが前記データのストリーム内の前記データサブセットよりも時間的に後に生じ、前記現在のデータサブセットが前記データのストリーム内の前記データサブセットと同時に生じる、前記1つ以上の類似度値を決定することと、(b)類似度値の1つ以上のセットを分類することと、を含む。
(もっと読む)
学習装置および学習方法、認識装置および認識方法、生成装置および生成方法、並びにプログラム
【課題】 時系列データの教師なし学習と、その学習結果を用いた時系列データの認識や生成を、容易に行う。
【解決手段】 記憶部5は、時系列データのパターンである時系列パターンを表現する、例えば、HMMなどの時系列パターンモデルを有する複数のノードNiから構成されるネットワークである時系列パターン記憶ネットワークを記憶しており、時系列パターン記憶ネットワークが、時系列データの観測値に基づいて、自己組織的に更新される。本発明は、例えば、ロボットなどに適用できる。
(もっと読む)
携帯端末装置
【課題】 音が四方に拡散されず、ユーザの耳の近傍においてのみ音を発生させることができる携帯端末装置を提供する。
【解決手段】 ユーザが携帯テレビ電話機を顔から一定距離離して設置し、カメラ14を自分の顔に向ける。ユーザの顔が表示部4の液晶表示器に表示されると、CPU1が表示された顔の大きさに基づいて、携帯テレビ電話機から顔(または耳)までの距離を計測する。次に、CPU1はROM3から、計測された距離に対応するフィルタ係数を読み出し、立体音響処理部16のフィルタ17、18に設定する。これにより、スピーカ19R、19Lからの音波に基づく音像が、ユーザの顔の位置に定位される。この結果、スピーカ19R、19Lからの音声が周囲に拡散することなく、ユーザの顔の位置に収束される。
(もっと読む)
バイオメトリクスを表現するための装置、方法、プログラム記憶装置、およびコンピュータ・プログラム(指紋バイオメトリック・マシン)
【課題】 バイオメトリクスを表現するための装置、方法、およびプログラム記憶装置を提供することにある。
【解決手段】 この装置はバイオメトリック特徴抽出器と変換器とを含む。バイオメトリック特徴抽出器は、画像内に描かれたバイオメトリクスに対応する特徴を抽出し、その特徴のうちの1つまたは複数により1つまたは複数の幾何学的形状からなる1つまたは複数のセットを定義するためのものである。1つまたは複数の幾何学的形状のそれぞれは、その画像の少なくとも一部分に適用される第1のセットの変換に関して変化しない1つまたは複数の幾何学的特徴を有する。変換器は、1つまたは複数の幾何学的特徴のうちの1つまたは複数を含む1つまたは複数の特徴表現を入手するためにその画像の少なくとも一部分に第1のセットの変換を適用し、1つまたは複数の変換された特徴表現を入手するために1つまたは複数の特徴表現に第2のセットの変換を適用するためのものである。
(もっと読む)
録画された会議のタイムラインに使用するための自動顔領域抽出
【課題】ビデオ画像処理において、ビデオ再生に用いるインデックス付タイムラインを提供すること。
【解決手段】打合せまたは会議における話し手の顔が自動的に検出され、各話し手に対応する顔画像が顔データベースに記憶される。会議の録画を再生する際に各話し手がいつ話しているかを、グラフィックスを用いて識別するためにタイムラインが作成される。タイムラインの各話し手を汎用的に識別する代わりに、顔画像を示してタイムラインに関連付けられた各話し手を識別する。
(もっと読む)
推定装置、及びその制御方法
【課題】 ユーザが現在の感情に至った原因を推定し、推定した原因に応じてユーザとのコミュニケーションを図るための技術を提供すること。
【解決手段】 状況解析部1302は画像、音声、生体情報に基づくユーザの周囲環境、ユーザの心理状態を推定し、原因推定部1303は推定した心理状態が所定の状態である場合には、生体情報に基づいてユーザの体調が不良であるのか否かを推定し、推定した心理状態が所定の状態である場合には上記周囲環境に基づいてユーザの心理状態の原因を推定する。
(もっと読む)
発話識別方法及びこれを用いたパスワード照合装置
【課題】 発話者の発話の仕方に左右されずに発話内容の識別誤り率を低減できる発話識別方法及び発話入力されたパスワードの識別誤りを低減するパスワード照合装置を提供する。
【解決手段】 発話内容に対する唇の縦幅と横幅の変化パターンから異なる発話内容で変化パターンの類似性が高いものは同一グループ、異なる発話内容で変化パターンの類似性が低いものは別グループとし、発話内容をグループ分類に基づいて識別する。また、パスワード登録者の発話状態を撮像するカメラ2と、撮像画像から唇の縦幅と横幅の変化パターンを測定する画像処理部3と、画像処理部3の測定データとデータベース5の登録グループ分類データからパスワード登録者の発話したパスワードを認識する発話識別部4と、発話識別部4の認識結果と登録パスワードを照合する照合部7とを備える。
(もっと読む)
制御システム
【課題】顔画像の認識結果に基づいてMIDIメッセージを生成し、当該MIDIメッセージによりMIDI機器を制御することで、当該顔画像の変化に対応した音声出力をなすこと。
【解決手段】本発明の制御システムは、入力された画像データの中で顔の所定部位の位置を検出し数値データとして出力する第1の機能と、この数値データを指定されたアルゴリズムを利用して変換処理しMIDIメッセージを生成する第2の機能と、予め所定の表現効果や所定のMIDI機器の操作に係るパラメータをプリセットする第3の機能と、を備え、上顔の所定部位の位置の変化に基づいてMIDI機器の音声出力を制御する制御手段を有し、制御手段は、MIDIメッセージの少なくとも一部を顔の所定部位の位置の変化に連動して動的に変更し、上記第3の機能により所定のパラメータが指定された場合には上記MIDIメッセージの生成に際して当該パラメータを参照する。
(もっと読む)
アバタ通信システム
【課題】 立体アバタを用いた自然な通信を実現する。
【解決手段】 受信手段30は、携帯電話装置2からの音声および動画像を受信する。音声認識手段32は、受信した音声について音声認識を行い、音素に対応する口唇形状を生成する。動画像認識手段34は、受信した動画像に基づいて、口唇形状を含む顔の表情を認識する。アバタ動作決定手段36は、音声認識手段32の出力と動画像認識手段34の出力とに基づいて、アバタの動作を示すアバタ動作データを生成する。アバタ動作決定手段36は、口唇形状決定手段38を含んでいる。口唇形状決定手段38は、音声認識手段32による口唇形状と、動画像認識手段34による口唇形状とを統合して口唇動作データ(アバタ動作データの一部)を決定する。送信手段40は、得られたアバタ動作データを相手方の携帯電話装置に送信する。
(もっと読む)
映像の未知の内容のパターンを発見するためのコンピュータ化された方法
【課題】本方法は、映像の未知の内容のパターンを発見するものである。
【解決手段】映像は、重なり合わないセグメントの集合に分割される。各集合は、映像の全てのフレームを含み、映像の選択された低レベルの特徴に従って分割される。重なり合わないセグメントは、対応するクラスタの集合にグループ化され、各クラスタは類似のセグメントを含む。次にクラスタはラベルを付され、ラベル間で相関ルールが特定されて、映像の未知の内容の高レベルのパターンを発見する。  (もっと読む)
(もっと読む)
映像の内容をマイニングする方法
【課題】本方法は、最初に映像の1つまたは複数の低レベルの特徴を選択することにより、その映像の未知の内容をマイニングする。
【解決手段】選択された特徴、あるいは特徴の組み合わせ毎に、時系列データが生成される。その後、その時系列データは自己相関をとられ、低レベルの特徴に基づいて映像の類似のセグメントが特定される。その類似のセグメントはクラスタにグループ化され、映像の未知の内容の中にある高レベルのパターンが発見される。  (もっと読む)
(もっと読む)
41 - 60 / 62
[ Back to top ]