
Fターム[5L096JA16]の内容
Fターム[5L096JA16]に分類される特許
81 - 100 / 210
目標追尾装置

【課題】追尾対象物の見かけ上の色が変化した場合にも精度の高い追尾処理を行えるようにする。
【解決手段】時系列的に取り込まれる画像データ中の目標物体を追尾する目標追尾装置であって、追尾対象の指定を受け付ける追尾対象物指定受付部と、指定された追尾対象の色を目標色として設定する目標色設定部と、パーティクルを用いて、パーティクル周辺の色と目標色との比較によって求められる色尤度の測定を行ない、色尤度が所定の基準を満たす場合には、その測定結果に基づいて画像データ中の追尾対象の領域を推定する一方、色尤度が所定の基準を満たさない場合には、パーティクルを用いて、時間差のある画像データ間の輝度差分によって求められる輝度尤度の測定を行ない、その測定結果に基づいて画像データ中の追尾対象の領域を推定し、推定された領域中の色で目標色を更新するパーティクルフィルタ処理部を備える。
(もっと読む)
眼領域検出装置、及びプログラム

【課題】取得した画像にノイズが発生している場合であっても、良好な精度で瞼の位置及び形状並びに虹彩位置を検出する。
【解決手段】瞼尤度λeyelid、第1の虹彩尤度λiris1、及び比較瞼モデルによって表される上瞼及び下瞼の各形状によって囲まれた領域外に存在する比較虹彩モデルによって表される虹彩の輪郭と画像に含まれる虹彩の輪郭とが一致する度合いを示す第2の虹彩尤度λiris2を演算し(108、116)、比較瞼モデルの1つと比較虹彩モデルの1つとで表された目モデルの各々について、瞼尤度λeyelid及び第1の虹彩尤度λiris1の各々が大きくなるに従って大きくなるように定めた値を、第2の虹彩尤度λiris2によって小さくなるように補正した値を目尤度λとして演算し(110、118、122)、演算された最も大きい目尤度λに対応する第1のモデルパラメータ及び第2のモデルパラメータで表されるモデルの瞼の位置及び形状並びに虹彩位置を検出する(124)。
(もっと読む)
動作認識装置、方法及びプログラム
【課題】手などの認識対象物の動作を認識する際に、背景を誤認識する可能性を低減しつつ、機器の操作方法として十分な機能をユーザに提供可能な動作認識技術を提供する。
【解決手段】画像選択部53は、画像入力部51から入力され画像記憶部52に記憶された画像から3つの時刻に撮影された画像を選択し、2つの画像の異なる組み合わせを選択する。動領域抽出部54は、一方の組み合わせから動きのある動領域を抽出する。非動領域抽出部55は、他方の組み合わせから動きの少ない非動領域を抽出する。色領域抽出部56は、1つの画像から、認識対象物に固有の色を表す色領域を抽出する。対象領域検出部57は、動領域、非動領域及び色領域を用いて、認識対象物を表す対象領域を検出する。
(もっと読む)
操作入力装置、操作入力方法、プログラム
【課題】被写体の動作により遠隔操作が可能な撮像装置として、これまでよりも実用性が
高く、有用なものを得る。
【解決手段】撮像により得られる画像データに存在する顔について、操作に相当する動き
を判定する。この操作に相当する動きが判定されたことに応じて、デジタルスチルカメラ
が所定の動作を実行するようにする。そのうえで、顔の所定の状態に応じて優先度を設定
し、操作に相当する動きの判定に際しては、この優先順を反映させるようにする。これに
より、複数の被写体に対応する身体部分ごとについて、動きの判定対象として重視される
度合いを変更できる。
(もっと読む)
学習装置および方法、認識装置および方法、並びにプログラム
【課題】画像からより確実に対象物体を検出できるようにする。
【解決手段】仮統合識別器生成部27は、統計学習により求められた、複数の弱識別器からなり、画像から対象物体を検出するための服装識別器および輪郭識別器を統合して、仮の識別器である仮統合識別器を生成する。統合識別器生成部28は、仮統合識別器を構成するいくつかの弱識別器を選択し、選択した弱識別器の線形和を特徴関数とする。さらに、統合識別器生成部28は、生成された任意の数の特徴関数のそれぞれに、特徴量を代入して得られた値のそれぞれを、新たな特徴量とし、それらの新たな特徴量を用いた統計学習により、画像から対象物体を検出するための最終的な統合識別器を生成する。本発明は、学習装置に適用することができる。
(もっと読む)
ポータブル・デバイス上での画像アノテーション
画像およびビデオの自動アノテーションのためのシステムは、モバイル・デバイスを建造物または景観などの対象物に向けると、対象物のアノテーションを有するシーンの画像がデバイスに表示されるようにする。アノテーションは、名称、歴史的情報、ならびに画像、ビデオ、およびオーディオ・ファイルのデータベースへのリンクを備えることができる。アノテーションの位置的配置を決定するための異なる技法を使用することができ、複数の技法を使用することによって、位置付けをより正確で信頼性の高いものにすることができる。アノテーション情報の詳細さのレベルは、使用する技法の精度に従って調整することができる。必要とされる計算は、モバイル・デバイス、サーバ、および相互接続ネットワークを備えるアノテーション・システム内に分散させることができ、アノテーションの付いた画像を複雑さのレベルが異なるモバイル・デバイスに適合させることを可能にする。アノテーションの精度と、通信コスト、遅延、および/または電力消費との間のトレードオフを考慮することができる。アノテーション・データベースは、自己組織的な方法で更新することができる。ウェブ上で入手できるような公開情報をアノテーション・データに変換することができる。  (もっと読む)
(もっと読む)
画像処理装置及びその方法並びに画像処理プログラム
【課題】ロバストでかつ高速な追跡を可能とする画像処理装置及びその方法並びに画像処理プログラムを提供すること。
【解決手段】画像処理装置100は、予め生成されたN個の特徴抽出部151を用いて、入力画像からN個の特徴量を抽出し、抽出された前記N個の特徴量から対象物体らしさを表す信頼度を算出する識別部152と、前記信頼度に基づいて前記入力画像に含まれる対象物体を検出する対象検出部120と、前記対象物体の前記信頼度とその背景の前記信頼度との分離度が、N個の特徴抽出部151を用いた場合よりも大きくなるように、N個の特徴抽出部151の中からM個の特徴抽出部を選択する特徴選択部130と、特徴選択部130で選択されたM個の特徴抽出部を用いて、前記入力画像からM個の特徴量を抽出し、抽出された前記M個の特徴量を用いて前記対象物体を追跡する対象追跡部140と、を備える。
(もっと読む)
対象物判定装置及びプログラム
【課題】対象物がマスクやサングラスなどの装着物を装着しているか否かを信頼性高く判定することができる対象物判定装置及びプログラムを提供する。
【解決手段】撮像して得られた画像が表す対象物について、マスクを装着した対象物の画像に反応するように学習した機械学習システムを用いてマスクを装着した対象物らしさを示す尤度値を算出し(S104)、マスクを装着していない対象物の画像に反応するように学習した機械学習システムを用いてマスクを装着していない対象物らしさを示す尤度値を算出し(S106)、該算出された2つの尤度値の比に基づいて、該撮像されて得られた画像が表す対象物がマスクを装着しているか否かを判定する(S108)。
(もっと読む)
オブジェクト検出装置、オブジェクト検出方法、オブジェクト検出プログラムおよび印刷装置
【課題】効率よく複数の種類のオブジェクトを検出する。
【解決手段】画像データ13bが示す画像からオブジェクトを検出するにあたり、前記画像データ13bが示す画像における複数の検出窓SWについて所定の第1オブジェクトとの類似度を取得し、少なくとも前記類似度が第1閾値(300)以上である場合、前記検出領域に前記第1オブジェクトが存在すると判定し、少なくとも前記類似度が前記第1閾値よりも小さい所定の第2閾値(100)以上である場合、前記検出窓SWに前記第2オブジェクトが存在すると判定する
(もっと読む)
画像照合方法、画像照合装置、画像データ出力処理装置、プログラム及び記憶媒体
【課題】オリジナル画像がカラー画像である場合に、これをコピーしたりして形成された非オリジナル画像との類似性を、精度よく判定することのできる画像照合装置を実現する。
【解決手段】本発明の画像照合装置101では、文書照合部2が、入力された画像データより画像の形状に関する特徴を示す形状特徴量を抽出して、登録されている登録画像の形状特徴量と比較する。また、色類似性判定部4が、入力された入力画像と登録画像との類似性を判定し、入力された画像データより画像の色に関する特徴を示す色特徴量を抽出して、登録画像の色特徴量と比較し、上記入力画像と上記登録画像との類似性を判定する。さらに、彩度判定処理部43が、入力された画像データより入力画像の彩度情報を求める。類似性総合判定部5は、上記判定結果と、彩度の情報とを基にして、入力画像と登録画像との類似性を判定する。
(もっと読む)
画像処理装置及び画像処理方法
【課題】画像処理装置及び画像処理方法を提供する。
【解決手段】本発明の画像処理装置は、元画像の画像データを取得する画像取得手段と、前記元画像の背景画素と前景画素を分離する画像処理手段とを含み、前記画像処理手段は、前記元画像を、前記画像データに基づいて、複数の第一画像セグメントに分割する第一の画像分割手段と、前記元画像を、前記画像データの画像距離情報に基づいて、前景セグメントと背景セグメントに分割する第二の画像分割手段と、前記第一の画像分割手段により分割された前記複数の第一画像セグメントの各々が、前記第二の画像分割手段により分割された前記前景セグメントと背景セグメントとの何れに属するかを判定することにより、前記元画像の前景画素領域と背景画素領域とを確定する画像分割確定手段と、を含む。
(もっと読む)
年齢推定方法及び年齢推定装置
【課題】安定して年齢推定することができる年齢推定方法及び年齢推定装置を提供する。
【解決手段】顔の特徴量と年齢は完全な相関関係にない(例外が多い)ことに着目し、所定の年齢以上/未満に大きく分類する判定機3−1〜3−6と、各判定機3−1〜3−6の判定結果を統合することにより顔画像の人物の年齢を推定する判定結果統合部4とを備える。これにより、所定の年齢前後では“実年齢と見かけ年齢の違い”、“見かけ年齢の個人差・バラツキ”、“性別による経年傾向の違い”が原因で誤判定する可能性が少なからずあるものの、所定の年齢から離れた顔に対する判定性能を高くとることができ、従来の年齢推定方法よりも安定した年齢推定が可能となる。また、大まかに分類する判定機3−1〜3−6とすることで少数の学習データで学習が可能となり、学習が容易になる。
(もっと読む)
画像認識装置
【課題】画素ブロック程度の大きさで検出される動く物体を高い精度で認識する画像認識装置を提供する。
【解決手段】画像認識処理部16では、評価値算出部21,動き領域抽出部23が、画像データをMPEG方式の符号化データに符号化する際、又はMEPEG方式で符号化された符号化データを画像データに復号する際に生成される動きベクトル、2次元DCT係数、符号化情報(ピクチャタイプ,ブロックタイプ)を使用して、画像の特徴を表す複数種類の評価値を作成し、更新処理部24が、その評価値と各種オブジェクトとの関係を規定した判定ルールに従い、マクロブロックを最小単位として画像認識を行う。従って、オブジェクトがマクロブロック程度の大きさであり、動きベクトルが発生し難い状況であっても、2次元DCT係数に基づいて生成された評価値から、オブジェクトの動きを検出できる。
(もっと読む)
強識別器の学習装置及びその方法並びに強識別器の学習プログラム
【課題】複数の弱識別器を有する強識別器において、無駄な画像データの処理を低減するとともに、識別処理を高速に行うこと。
【解決手段】強識別器の学習装置200は、弱識別器1(205)及び弱識別器2(206)を有し、弱識別器1(205)及び弱識別器2(206)の各々において、画像データと識別対象との類似度を、設定された閾値と順次比較することによって、前記画像データに前記識別対象が含まれる否かを識別する強識別器204の制御部201と、強識別器204により前記識別対象が含まれると識別された画像データを抽出する抽出部203と、を備え、強識別器204の制御部201は、抽出部203により抽出された画像データに対する弱識別器1(205)及び弱識別器2(206)の類似度の中で、最も低い類似度を弱識別器1(205)及び弱識別器2(206)の各々の閾値に設定する。
(もっと読む)
複数の保存されたディジタル画像を検索するための方法及び装置
複数の保存されたディジタル画像が検索される。検索クエリに従って、画像が取得される(ステップ204)。該取得された画像は、画像の内容の所定の特徴に従ってクラスタリングされる(ステップ208)。クラスタは、所定の基準に基づいてランク付けされる(ステップ210)。該ランク付けされたクラスタに従って、検索結果が返される(ステップ212)。 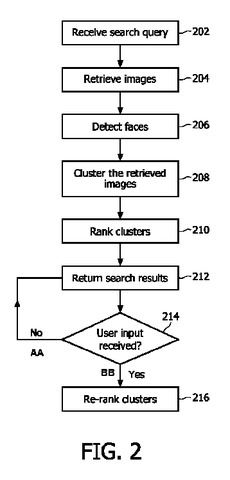 (もっと読む)
(もっと読む)
顔認識装置、顔認識プログラム、顔認識方法
【課題】ユーザが目的としている顔を認識することができる印刷装置を提供する。
【解決手段】画像内の顔を認識する第1の顔認識手段と、前記第1の顔認識手段によって
顔認識した結果を出力する出力手段と、前記出力手段によって出力された認識結果の画像
に対し顔の器官の位置を指定する位置データの入力を受け付ける器官位置入力手段と、前
記器官位置入力手段によって入力される位置データと当該位置データが入力された入力順
序に従って、顔の器官を検出する器官検出手段と、前記器官検出手段の検出結果に基づい
て、器官の位置に従って顔を認識する第2の顔認識手段とを有することを特徴とする。
(もっと読む)
動画像データのシーン分割装置
【課題】非圧縮または圧縮された動画像データを、高度な概念(ショット種別)に分類してからショットを集約することにより、従来技術よりも正確なシーン分割を可能とする動画像データのシーン分割装置を提供する。
【解決手段】動画像データのショット分割を行うショット分割部1と、動画像データを複数の意味的なショット種別に分類するショット種別分類処理部11と、同一のショット種別が連続する区間をシーンと見なし、同一種別を持つショットを統合することにより動画像データをシーンに分割するショット統合部13とからなる。また、ショット種別分類処理部で得られたショット種別の時間的な連続性を考慮して、隣接するショット種別と異なるショット種別を補正するショット種別補正処理部12を具備することができる。
(もっと読む)
インターホン装置
【課題】環境が変化する屋外などで撮影した画像に対しても、誤検知することなく、安定して顔の存在を検知可能な顔検知装置を備えたインターホン装置を提供する。
【解決手段】呼び出し釦158を備えたインターホン子機150と、呼び出し釦の操作に応じて呼び出し音を報知する鳴動部132を備えたインターホン親機100からなるインターホン装置は、インターホン子機150前面の画像を入力する画像入力部152と、呼び出し釦操作したときの入力画像から動き領域を抽出する動き領域抽出部126と、動き領域が所定量以上の場合顔画像を含んでいるか否かを判定する判定部120と、判定部120の判定結果に応じて異なる呼び出し音を鳴動部132に出力する制御部124とを備え、動き領域が所定量未満の場合、更に異なる呼び出し音を鳴動部132に出力する。
(もっと読む)
画像処理装置、画像処理方法、プログラム及び記憶媒体
【課題】混雑度が高く、被写体と被写体との重なりが生じやすくなるような場合であっても、被写体を精度よく検出し、計数することを目的とする。
【解決手段】それぞれ異なる検出方法でフレーム画像に含まれる被写体を検出する複数の検出手段を有する画像処理装置であって、撮像手段よりフレーム画像を取得する取得手段と、取得手段で取得されたフレーム画像に含まれる被写体の混雑度を判定する判定手段と、判定手段で判定された混雑度に基づいて、複数の検出手段の1つを選択する選択手段と、選択手段で選択された検出手段により、取得手段で取得されたフレーム画像から検出された検出結果に基づいて、フレーム画像に含まれる被写体の数を計数する計数手段と、を有することによって課題を解決する。
(もっと読む)
画像処理装置、画像処理方法、プログラム及び記憶媒体
【課題】明るさが変化した場合等においても、精度よく被写体を検出することを目的とする。
【解決手段】撮像手段で撮像された画像より顔領域を検出する顔領域検出手段と、顔領域検出手段で検出された顔領域に係る情報に基づいて、前記画像の画素値を調整する調整手段と、調整手段で調整された前記画像より人物領域を検出する人物領域検出手段と、顔領域検出手段で検出された顔領域と、前記人物領域検出手段で検出された人物領域と、を統合する統合手段と、を有することによって課題を解決する。
(もっと読む)
81 - 100 / 210
[ Back to top ]