
国際特許分類[G10L13/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声の合成;テキストを音声に変換するシステム (2,199)
国際特許分類[G10L13/00]の下位に属する分類
合成音作成の方法;音声合成器 (464)
音声合成器で使われる音声素片;結合規則 (315)
テキストから音声を合成するための,テキストの分析,またはパラメータの生成,例.表記素から音素への変換,韻律の生成または強勢またはイントネーションの決定 (495)
国際特許分類[G10L13/00]に分類される特許
891 - 900 / 925
メッセージを変更するための方法及びシステム
本発明は、音声コンテンツを有する入力メッセージ(IM)を変更するための方法及びシステムについて記載する。当該方法は、入力メッセージ(IM)の音声コンテンツ(A)をテキスト表示(TR)の要素に変換するステップと、入力メッセージ(IM)の音声コンテンツ(A)をテキスト表示(TR)に関連する構成音声要素(As)に分割するステップと、編集入力に従って、テキスト表示(TR)を編集するのに適した形式でテキスト表示(TR)をレンダリングするステップと、出力メッセージ(OM)の変更された音声コンテンツ(A’)を与えるように、編集されたテキスト表示(TR’)に従って、音声コンテンツ(A)の関連する音声要素(As)を改変するステップとを有する。 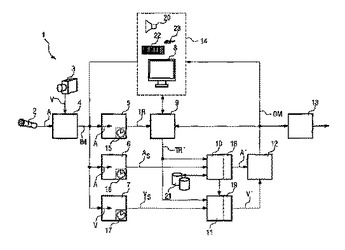 (もっと読む)
(もっと読む)
ショートメッセージサービスを通じる音声
移動体通信デバイスによる音声メッセージの送信方法に関する。この方法には、移動体通信デバイスのユーザから発話を受信する工程と、受信した発話の非文字表現を生成する工程と、非文字表現を文字メッセージの本体へ挿入する工程と、無線メッセージングチャネルを通じて移動体通信デバイスから受信者のデバイスへ文字メッセージを送信する工程とが含まれる。  (もっと読む)
(もっと読む)
共通の対話管理システムによる複数アプリケーションの駆動方法
本発明は、共通の対話管理システム(1)による複数のアプリケーション(A1、A2、A3、...、An)の駆動方法を説明する。ここで、ユニークな音響アイコンのセット(S1、S2、S3、...、Sn)を各アプリケーション(A1、A2、A3、...、An)に割り当てる。共通の対話管理システム(1)は、それぞれのアプリケーション(A1、A2、A3、...、An)のユニークな音響アイコン(S1、S2、S3、...、Sn)のセットから選択した必要な音響アイコン(I1、I2、I3、...、In)を対話フローの一時点において再生することにより、アプリケーション(A1、A2、A3、...、An)の状態をユーザに通知する。さらに、本発明は、対話管理システムを説明している。該システムは、前記システムにユーザ入力(5)を検出する入力検出機構(4)と、可聴音声(7)を出力する音声出力機構(6)と、ユーザ入力を解釈し可聴音声出力(7)を合成することにより対話フローを調整するコア対話エンジン(8)と、対話管理システム(1)とアプリケーション(A1、A2、A3、...、An)との間の通信をするアプリケーションインターフェイス(10)と、アプリケーション(A1、A2、A3、...、An)に割り当てられたユニークな音響アイコン(S1、S2、S3、...、Sn)のセットのソースと、アプリケーション(A1、A2、A3、...、An)に対応する音響アイコン(I1、I2、I3、...、In)を選択して対話フローの一時点で再生する音響アイコン管理部(11)とを有する。  (もっと読む)
(もっと読む)
テキスト音声変換システムを含む半導体チップおよびコミュニケーション可能な装置

【課題】本発明は、使用者が、TTS システムで構成されたコミュニケーション可能な装置を個人化し、入力テキストメッセージを出力オーデオメッセージに変換することを可能にすることにある。
【解決手段】本発明はコミュニケーション可能なデバイスに使用されるテキスト音声変換システム(TTS)と適用手段とを有する半導体チップおよびそれを保持するコミュニケーション可能な装置に関する。TTSシステムは入力テキストメッセージを出力オーデオメッセージに変換し、出力オーデオメッセージは音声パラメータセットで設定された特性を有する。当該半導体チップは、又、音声パラメータセットが記録された第1メモリをすくなくとも有する。音声パラメータセットの任意の1つはテキストメッセージが受信された際、使用のため能動音声パラメータとして選択することができる。
(もっと読む)
音声合成を用いた医療画像解析
医療画像を検査するシステム及び方法。上記方法を達成するために、医療画像を表すディジタル画像がアクセスされる。コンピュータ支援検出(CAD)を用いてディジタル画像を解析して候補異常を検出する。検出された候補異常に関連した少なくとも1つのレベルの情報を備えたCAD報告が生成される。少なくとも1つのレベルの情報によってCAD報告を処理して音声合成CAD報告を生成する。ディジタル画像が音声合成CAD報告の供給と同時に表示され、それによって、ユーザはCAD報告を聴くと同時にディジタル画像を検査することが可能である。
 (もっと読む)
(もっと読む)
マルチモーダル埋め込み型インタフェースの交換可能なカスタマイズ用の方法及び装置
本発明の一定の態様では、移動体音声通信デバイスは、聴覚的な情報及びデータを送受信するための無線トランシーバ回路と、プロセッサと、プロセッサ上で実行されると移動体音声通信デバイスに、ユーザインタフェースと関連付けられている選択可能な個性を移動体音声通信デバイスのユーザに対し提供させる実行可能な命令を記憶するメモリとを備える。実行可能な命令には、選択可能な個性を有する異なるユーザプロンプトを用いるユーザインタフェースを移動体音声通信デバイス上に実装することが含まれる。異なるユーザプロンプトの選択可能な個性の各々は移動体音声通信デバイスにおける1つ以上のデータベースに記憶されているデータに対し規定及びマッピングされる。この移動体音声通信デバイスは、発声されたユーザ入力を認識し、対応する認識された語を出力するデコーダと、認識された語に対応する語を合成する発声シンセサイザとを含み得る。このデバイスはデバイスに対し無線送信されるか、コンピュータインタフェースを通じて送信されるか、又はメモリカードとしてデバイスに対し提供されるユーザ選択可能な個性を含む。  (もっと読む)
(もっと読む)
ユーザ適応型装置およびその制御方法
インタフェース部(10)において、入力部(1)はユーザ(7)の発話などの入力信号を取得し、入力処理部(2)がこの入力信号を処理して、ユーザ(7)に関する情報を検出する。この検出結果を基にして、応答内容決定部(3)はユーザ(7)への応答内容を決定する。一方、応答方法調整部(4)は入力信号の処理状態や入力信号から検出されたユーザ(7)に関する情報などに基づいて、発話速度などユーザ(7)への応答方法を調整する。 (もっと読む)
音声学と音韻論の学習と理解による,言語習得を容易にするための方法,システム,プログラム,データの集合
この技術は,言語学習を容易にするということを目指しており,全般的に音韻論と音声学の習得を容易にするためであり,特には韻律の習得を容易にするためである.そのために,学習者は目標言語のリズムや韻律構造をよりよく受け取るために訓練される.その訓練は,学習者が目標言語の韻律特徴をよりよく特定させてくれ,その特定の実現能力を発達させてくれる,いくつかの簡単にする方法の助けを借りて,決まった聴覚再生を聞くことからなっている. (もっと読む)
音声対話システム用のユーザ適応対話支援
音声対話システムに直面する共通の課題は、それらのシステムが最適な方法でこのようなシステムについての様々なレベルの経験度を有するユーザに供給しなければならないことである。本発明は、経験の浅いユーザと経験豊かなユーザとを区別し、相応じて適応される音声プロンプトを生成する音声対話システムに関する。このシステムは、経験の浅いユーザと経験豊かなユーザとを区別し、前者には詳細な音声プロンプトを、後者には簡潔な音声プロンプトを発することができる。本発明によれば、音声対話システムは、簡潔な音声プロンプトを使用して音声対話ステップを開始する。システムユーザが、指定時間(認識タイムアウト)後にその簡潔な音声プロンプトに反応しなかった場合、詳細な音声プロンプトが発せられる。したがって、両方の種類の音声プロンプトが、対話ステップ毎に発せられ、システムユーザの選択に利用できる。そのユーザは常にユーザが必要とする種類及び方法の対話を選択できる。経験豊かなユーザは常に対話の過程に関する主導権をとる選択肢を有する。音声対話のある時点においてユーザが音声対話システムによって期待される音声応答の種類について確信がない場合、ユーザは単に認識タイムアウトを待ち、次に詳細な音声プロンプトを聞くことができる。 (もっと読む)
オーディオ対話システム及びボイスブラウズ方法
オーディオ対話システムとボイスブラウズ方法を記載している。オーディオ入力部(12)がオーディオ入力信号を取得する。スピーチ認識手段(20)がオーディオ入力信号をテキスト入力データ(21)に変換する。コンテントデータ(D1)は、テキストコンテントと少なくとも1つの参照(LN1)を有する。参照は、参照先と起動フレーズを有する。ブラウズ手段は、取得した入力テキストデータ821)を起動フレーズ(28)と比較する。入力テキストデータ(21)が起動フレーズ(28)と同一でなくても、入力テキストデータと起動フレーズが類似した意味を有する場合マッチしたとされる。マッチした場合、参照先に対応するコンテントデータにアクセスする。  (もっと読む)
(もっと読む)
891 - 900 / 925
[ Back to top ]