
国際特許分類[G10L13/08]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声の合成;テキストを音声に変換するシステム (2,199) | テキストから音声を合成するための,テキストの分析,またはパラメータの生成,例.表記素から音素への変換,韻律の生成または強勢またはイントネーションの決定 (495)
国際特許分類[G10L13/08]に分類される特許
31 - 40 / 495
音声案内システム
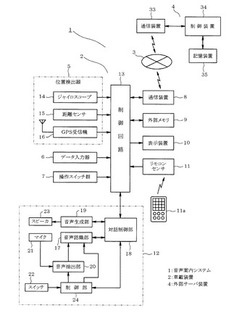
【課題】録音音声を極力使用して音声案内することができ、また、合成音声を使用する場合であっても、高品質の音声案内を実行可能にする。
【解決手段】車載装置2において、分割された単語あるいは文節に対応する録音音声データが記憶手段に存在するか否かを検索し、録音音声データがない単語あるいは文節については、外部サーバ装置4に送信して、録音音声データがサーバ側記憶手段に存在するか否かを検索し、検索された録音音声データを車載装置2へ送信し、検索手段により検索した録音音声データと外部サーバ装置4から受信した録音音声データとを接続し、接続した音声データを音声出力するように構成した。
(もっと読む)
テキスト音声変換装置、テキスト音声変換プログラム及びテキスト音声変換方法

【課題】 コミュニケーションの感情を十分に表現でき、趣向的に富んだテキスト音声変換再生をすることができるテキスト音声変換装置を提供する。
【解決手段】 再生される音声データの抑揚再生条件を設定する再生条件設定部54と、与えられたテキストデータ30を前記再生条件設定部54によって決定された抑揚再生条件を具備する読み上げ用の音声データに変換する音声変換部55とを備えるテキスト音声変換装置である。前記再生条件設定部54は、互いに交差する第1及び第2方向に広がりを有する描画領域22に描画された画像情報31を線形的な線状オブジェクトに変換し、前記音声変換部55は、前記線状オブジェクトの第1の方向に沿って前記テキストデータの文字列を割り付け、前記割り付けられたテキストデータの文字に前記線状オブジェクトの第2の方向の位置に応じた抑揚再生条件を与える。
(もっと読む)
テキスト音声変換装置、テキスト音声変換プログラム及びテキスト音声変換方法
【課題】 コミュニケーションの感情を十分に表現でき、趣向的に富んだテキスト音声変換再生をすることができるテキスト音声変換装置を提供する。
【解決手段】 再生される音声データの抑揚再生条件を設定する再生条件設定部54と、与えられたテキストデータ30を前記再生条件設定部54によって決定された抑揚再生条件を具備する読み上げ用の音声データに変換する音声変換部55とを備えるテキスト音声変換装置である。再生条件設定部54は、互いに交差する第1及び第2方向に広がりを有する描画領域22に描画された画像情報を前記第1方向に細分したセグメントの画像情報に基づいて音階を決定して線状オブジェクトに変換し、音声変換部55は、前記線状オブジェクトに沿って割り付けられたテキストデータの文字に前記線状オブジェクトの第2の方向の位置に応じた抑揚再生条件を与える。
(もっと読む)
読み記号列編集装置および読み記号列編集方法
【課題】読み記号列の編集に要する時間を短縮すると共に編集後の音声波形の品質を確保する読み記号列編集装置を実現する。
【解決手段】読み記号列編集装置は、読み記号列を生成する言語処理手段と、前記読み記号列を記憶する読み記号列記憶手段と、前記読み記号列記憶手段の読み記号列を第1の音声波形に変換する第1の音声合成手段と、前記読み記号列記憶手段の読み記号列を第2の音声波形に変換する第2の音声合成手段と、前記第2の音声合成手段を利用して、前記読み記号列記憶手段の読み記号列の少なくともアクセント型を編集する読み記号列編集手段とを備える。前記第2の音声合成手段の処理時間は、前記第1の音声合成手段の処理時間よりも短い、あるいは、前記第2の音声合成手段で変換された前記第2の音声波形の発話速度は、前記第1の音声合成手段で変換された前記第1の音声波形の発話速度とは異なる。
(もっと読む)
電子機器
【課題】より汎用な音声再生の速度を制御する技術を提供する。
【解決手段】外部から配信される書籍データを受信する通信部と、この書籍データを記憶する記憶部と、ユーザの操作を電気信号に変換する操作部と、前記操作に基づき前記記憶部から前記書籍データを音声で再生する音声出力制御部と、前記書籍データのうちユーザにとって重要な個所を決定する制御部とを備え、前記音声出力制御部は前記書籍データを音声で再生する際にこの音声の再生速度を制御しながら再生し、前記制御部は前記音声出力制御部が前記書籍データを音声再生した位置を前記記憶部に保存して音声再生した位置と前記書籍データ内の再生位置を同期させる電子機器。
(もっと読む)
音声合成装置および音声合成プログラム
【課題】 音声合成の際に,アクセント修正または韻律修正を高精度に行える技術を提供することを目的とする。
【解決手段】 音声合成装置1は,テキスト情報5のモーラ数に対応するリズム情報を生成するタイミング制御部11,リズム情報をスピーカ,画面に出力するリズム情報出力部12,リズム情報に同期した第1入力音声を取得する音声入力部13,第1入力音声から音声のピッチ周波数情報を抽出するピッチ抽出部14,リズム情報とピッチ周波数情報から,第1入力音声のモーラ境界を修正したモーラ境界情報を生成するモーラ境界修正部15,および,テキスト情報5と第1入力音声のモーラ境界情報とピッチ周波数情報から,アクセント情報6を抽出するアクセント抽出部16を備える。
(もっと読む)
音声合成方法、音声合成装置及び音声合成プログラム
【課題】少ない量の目標話者の音声データから得られる類似話者音声データベースを用いて、対象テキストに対応し、目標話者の特徴を持つ音声を合成する音声合成方法、音声合成装置及び音声合成プログラムを提供する。
【解決手段】目標話者の音声データとの話者類似度が高い複数の部分音声データと、部分音声データを発した話者を示す類似話者識別子と部分音声データの発声音素を示す音素情報とを少なくとも示す音声素片とからなる類似話者音声データベースが予め記憶される。音素情報に基づいて、対象テキストの音素コンテキストに合成単位で適合する音声素片候補を類似話者音声データベースから探索する。各音声素片候補の類似話者識別子に対応する話者類似度を少なくとも用いて、合成単位の対象テキストと音声素片候補との適合度を総合コストとして算出する。
(もっと読む)
音声データ通信システム
【課題】サーバとの間の音声データの送受信によるネットワーク負荷を低減するための技術を提供すること。
【解決手段】音声データ通信システム1を、音声合成サーバ10と、メールサーバ20と、第1〜第nの情報処理装置30_1〜30_nとを含む構成とし、情報処理装置30において、テキストメールを音声変換対象情報と共に音声合成サーバ10に送信し、音声合成サーバ10において、受信したメールの文章を複数の文に分割し、各分割文データを音声合成処理によって音声データに変換し、これを圧縮等した分割音声ファイルを情報処理装置30に送信する。情報処理装置30は、最初の分割音声ファイルを受信すると、予め設定した送信タイミングで送信依頼情報を音声合成サーバ10に送信し、音声合成サーバ10は、送信依頼情報を受信するごとに、未処理の分割文データを1つずつ音声合成処理によって分割音声ファイルに変換し情報処理装置30に送信する。
(もっと読む)
音声合成方法、装置、及びプログラム
【課題】有声音同士が無声音を介して接続されているようなターゲットに対しても、合成音声のイントネーションの連続性を保ち、合成音声が高品質となるよう候補素片を選択することができる。
【解決手段】i番目のターゲット(iは3以上の自然数)が有声音であって、(i-1)番目のターゲットが無声音であった場合に、kが2以上であってkが最小となる(i-k)番目の有声音となるターゲットに適した候補素片として選択されている候補素片(以下、(i-k)番目の候補素片という)を探索する先行有声候補素片探索サブステップと、(i-k)番目の候補素片の終端位置のF0値とi番目の候補素片群の各候補素片の先頭位置のF0値群から接続F0サブコストを計算する接続F0サブコスト計算サブステップと、接続F0サブコストに基づいてi番目の候補素片群から、i番目のターゲットに適した1の候補素片を選択する選択サブステップとを備える。
(もっと読む)
音声合成情報編集装置
【課題】自然な音声を合成し得る音声合成情報を生成する。
【解決手段】記憶装置12は、音素列情報SAと特徴量情報SBと含む音声合成情報Sを記憶する。音素列情報SAは、合成対象音の音素毎に発音長a3を指定する。特徴量情報SBは、合成対象音の特音高の時間変化を指定する。表示制御部22は、音素の時系列を示す音素列画像32と特徴量の時間変化を示す特徴量画像34とを表示装置16に表示させる。編集処理部24は、音素列情報SAが指定する各音素σ[n]の発音長a3を、特徴量情報SBが当該音素σ[n]について指定する音高P[n]に応じた伸縮度K[n]で変更する。
(もっと読む)
31 - 40 / 495
[ Back to top ]