
国際特許分類[G10L13/08]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声の合成;テキストを音声に変換するシステム (2,199) | テキストから音声を合成するための,テキストの分析,またはパラメータの生成,例.表記素から音素への変換,韻律の生成または強勢またはイントネーションの決定 (495)
国際特許分類[G10L13/08]に分類される特許
81 - 90 / 495
ロボット、ロボット制御方法およびプログラム
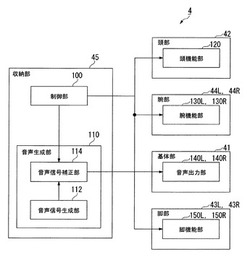
【課題】姿勢に応じて、違和感のない自然な音声を出力する。
【解決手段】ロボット4は、基体(基体41)に可動連結した可動部(例えば、頭部42)の駆動を制御する駆動制御手段(制御部100)と、音声を生成する音声生成手段(音声生成部110)と、前記音声生成手段において生成された音声を出力する音声出力手段(音声出力部140L、140R)とを有し、前記音声生成手段は、前記駆動制御手段によって制御される前記可動部の前記基体に対する姿勢に基づいて、生成する音声を補正する。
(もっと読む)
ユーザ挙動を学習する音声合成装置、音声合成方法およびそのためのプログラム

【課題】
ユーザの挙動に基づいて音声合成装置を自動修正することにより、ユーザに合わせて、ユーザに好まれる音声を合成できるようにする。
【解決手段】
音声合成装置において、音声を合成する音声合成部200と、合成音声を提示し、提示された合成音声に対するユーザの挙動情報を出力する音声判定部310と、ユーザ挙動情報からユーザ挙動特徴を抽出するユーザ挙動特徴抽出部410と、抽出したユーザ挙動特徴から、合成音声に対するユーザの音質評価値を推測する音質評価値推測部420と、前記音質評価値に基づいて、前記音声合成部200を修正する修正部500とを備える。
(もっと読む)
音声合成装置、音声合成方法およびカーナビゲーションシステム
【課題】録音音声と合成音声とが混在した音声を出力することに伴う了解性の低下を防止する。
【解決手段】本発明の音声合成装置は、種々の録音音声データを記憶する記憶手段28と、テキストを単語あるいは文節単位に分割する分割手段22と、分割された単語あるいは文節に対応する録音音声データが記憶手段28に存在するか否かを照合する照合手段26と、分割された単語あるいは文節の全てに対応する録音音声データが記憶手段28に存在するときに、テキスト全文を録音音声で音声合成し、そうでないときに、テキスト全文を規則合成で音声合成する音声合成手段とを備えたものである。
(もっと読む)
音声合成装置及び方法、並びに音声合成プログラム
【課題】発音が前後の音の影響を受ける英語等の言語を音声合成するに際して、前後の音変化を考慮した音声合成を行う。
【解決手段】本発明は、単語の音声記号を保持する音声記号辞書、及びこの音声記号辞書を参照し言語テキスト中の単語を音声記号へ変換する音声記号変換機能と、音が変化する条件と変化後の音声記号を保持する音変化規則辞書、及び音声記号変換機能により得られた音声記号と音変化規則辞書とを参照し、音変化規則辞書により保持される音変化が生じる条件に合致する音声記号が含まれていた場合、当該箇所を当該音変化規則辞書の変化後の音声記号へと置換する音声記号置換機能と、音声記号を音声出力するテキスト音声合成機能とから成る。
(もっと読む)
音声対話装置および方法
【課題】適切なタイミングで応答できる音声対話装置および方法を提供
【解決手段】まず、入力した音声から単語列を抽出する(S30)。また、入力した音声の話速を算出する(S40)。そして、現在の入力単語列に後続すると予測される単語列(以下、後続予測単語列という)とこの後続予測単語列に対応した出現確率とを記憶する出現確率リストと、抽出した単語列とを比較して、抽出した単語列に後続すると予測される後続予測単語列の中で最も出現確率の高い後続予測単語列を抽出する(S50)。更に、算出した話速を用い、後続予測単語列が入力されるのにかかる時間(以下、後続入力時間という)を算出する(S60)。その後、抽出した後続予測単語列の出現確率を確信度とし、抽出した後続予測単語列に付与する(S70)。その後、付与された確信度が応答判定値以上である場合に、この後続入力時間で、出力タイミング予測を確定させる(S80)。
(もっと読む)
音声合成装置、音声合成方法、及び音声合成プログラム
【課題】音声合成用のテキストの修正をエンドユーザが理解しやすい入力テキストのレベルで、簡便に行えるようにする。
【解決手段】音声合成の対象となるテキストを編集するテキスト編集部と、合成音声の読み、又はアクセントを修正するために実施したテキスト編集であるか否かを判定するテキスト編集判定部と、合成音声の読み、又はアクセントを修正するために実施したテキスト編集であると判定した場合に、当該テキスト編集の編集内容を示す編集履歴データを作成する編集履歴データ作成部と、作成した編集履歴データの登録があったときに、当該編集履歴データを格納する編集履歴データ格納部とを備える。
(もっと読む)
情報出力装置及び情報出力プログラム
【課題】音声出力の速度を設定するための手間を省く。
【解決手段】電子辞書装置1において、図(c)の内容が表示されている状態から、ユーザ操作により反転表示で文字列「assemble」がジャンプ対象単語として指定されると(図(d))、ジャンプ先の辞書データベースとして「ロ○グマン現代アメリカ英語辞典」等の辞書データベース82a〜82gの選択画面が表示部12のディスプレイ10に表示される(図(e))。この選択画面から「ロ○グマン現代アメリカ英語辞典」が指定されると、その格付け「4」が読み出され、当該格付け「4」に対応する変化量「+1ポイント」だけ設定速度ポイントが変更されて更新される。そして、変更後の設定速度ポイントに基づいて音声出力速度が制御される。
(もっと読む)
音声合成装置、ロボット装置、音声合成方法、及び、プログラム
【課題】ロボット装置の実際の動作と同期した音声を合成することが可能な音声合成装置を提供すること。
【解決手段】音声合成装置100は、予め定められた動作を行うロボット装置に適用され、且つ、処理対象となる文字列である処理対象文字列に基づいて当該処理対象文字列を表す音声である処理対象音声を合成する音声合成処理を行うように構成される。音声合成装置100は、上記処理対象文字列の少なくとも一部である動作付随文字列と対応付けられた動作を上記ロボット装置が実行するために要する時間である動作実行時間を取得する動作実行時間取得部101と、上記取得された動作実行時間に亘って発せられる音声であって、上記動作付随文字列を表す音声である、動作付随音声を含む上記処理対象音声を合成する上記音声合成処理を行う音声合成処理実行部102と、を備える。
(もっと読む)
素片情報生成装置、音声合成システム、音声合成方法、及び、プログラム
【課題】合成される音声の品質が低下することを防止しながら、当該合成される音声の基となる素片情報のデータ量を低減することが可能な素片情報生成装置を提供すること。
【解決手段】素片情報生成装置300は、時間間隔を表すフレーム周期を、音声の韻律に関する情報である韻律関連情報に基づいて決定するフレーム周期決定部301と、連続する2つの時間フレームの開始位置が上記決定されたフレーム周期だけ離れるように配置された複数の時間フレームのそれぞれに対して、音声を合成する音声合成処理の基となる基礎音声の一部である音声素片のうちの当該時間フレーム内の部分の特徴を表す特徴パラメータを抽出し、当該抽出された特徴パラメータの時系列データを含む素片情報を生成する素片情報生成部302と、を備える。
(もっと読む)
音声合成装置及び方法
本発明は、音声合成装置及び方法を提供する。本発明の一態様によれば、テキスト文を入力するように構成される入力部と、言語情報を抽出するために前記テキスト文を解析するように構成されるテキスト解析部と、前記言語情報及び予めトレーニングされた統計パラメータモデルを使用することによって音声パラメータを生成するように構成されるパラメータ生成部と、前記音声パラメータに情報を埋め込むように構成される埋込部と、前記埋込部によって前記情報を埋め込まれた前記音声パラメータを、前記情報を備えた音声に合成するように構成される音声合成部と、を具備する音声合成装置が提供される。 (もっと読む)
81 - 90 / 495
[ Back to top ]