
国際特許分類[G10L13/08]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声の合成;テキストを音声に変換するシステム (2,199) | テキストから音声を合成するための,テキストの分析,またはパラメータの生成,例.表記素から音素への変換,韻律の生成または強勢またはイントネーションの決定 (495)
国際特許分類[G10L13/08]に分類される特許
11 - 20 / 495
ゲームプログラムおよびゲーム装置
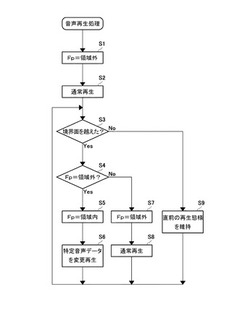
【課題】 音声データのデータ量を増大させることなく、ゲーム音による多彩な演出を行うことができるゲームプログラムおよびゲーム装置を提供する。
【解決手段】 コンピュータを、プレイヤキャラクタCが行動する仮想空間Sを生成する仮想空間生成手段30a、予め記憶され、所定の波形で構成される音声データを有し、当該音声データを再生する音声再生手段30c、仮想空間内の状態が所定の条件を満たすか否かを判定する条件判定手段30e、および条件判定手段30eが条件を満たすと判定した場合に、再生される音声データのうち少なくとも1つの音声データ(特定音声データ)の波形を加工した音声データを音声再生手段30cによって再生させる音声変更手段30f、として機能させる。
(もっと読む)
電子機器、再生方法、プログラム、及び、記録媒体

【課題】電子書籍等に含まれる文章データの音声再生を行う際に、ユーザが当該文章データの内容を十分に楽しむことができる電子機器を提供する。
【解決手段】本発明に係る電子機器1は、文章データの音声再生を行う音声解析部24及び音声変換部31は、文章データに含まれる属性情報を読み取る属性情報読取部10によって読み取られた属性情報に対応付けられた設定情報に応じて文章データの音声再生を行う。
(もっと読む)
音声発生及び認識装置
【課題】MP3などの音声圧縮方法等により予め作成した種々の会話のデータを、好きな音声に置換し、センサにより簡便に会話モードを適選設定して、当該モードでの対話型の会話を行うことができる音声発生及び認識装置を提供する。
【解決手段】
音声発生及び認識装置に、書き換え可能な記憶手段と、音声入力手段と、MP3などの音声圧縮方法等により予め作成した種々の会話データの入力手段と、音声認識手段と、声紋分析置換手段と、筐体の状態を検出する少なくとも1つのセンサとを設けた構成とした
(もっと読む)
音声合成装置、音質修正方法およびプログラム
【課題】利用者の主観に合うように合成音声を修正することが可能な音声合成装置、音質修正方法およびプログラムを提供する。
【解決手段】音声合成装置は、合成音声取得部、範囲取得部と、劣化コスト算出部、劣化種別判定部、劣化種別取得部、修正情報生成部、および音声合成部を有する。音声合成部は、合成音声を取得する。範囲取得部は、音声における修正を行う第1の範囲を取得する。劣化コスト算出部は、第1の範囲における音質劣化に応じた劣化コストを算出する。劣化種別判別部は、修正候補劣化種別を、劣化コストに基づき判定する。劣化種別取得部は、判定された修正候補劣化種別の中から修正劣化種別を取得する。修正情報生成部は、修正劣化種別に基づき音声を修正するための修正情報を生成する。音声合成部は、修正情報に基づき音声の再合成を行うことにより、上記課題の解決を図る。
(もっと読む)
非言語依存韻律マークアップを用いてテキストからスピーチに処理する方法および装置
【課題】所望の韻律特徴を有するスピーチをモデリングするための技術を提供する。
【解決手段】韻律特徴を定義するタグのセットを作成し、選択したタグをテキスト本文の適切な場所に配置する。各タグは、テキストを処理することで生成されるスピーチの韻律特徴に制約を課す。スピーチ本文およびタグの処理により、解くことで語句の範囲にわたる韻律特徴を定義する曲線を生成する方程式のセットと、解くことで語句内の個々の単語の韻律特徴を定義する曲線を生成するさらなる方程式のセットを生成する。曲線によって定義されるデータは、テキストと併せて用いられ、タグによって定義される韻律特徴を有するスピーチを生成する。タグのセットは、ターゲット話者が読むトレーニングテキストのリーディングにより生成し、ターゲット話者の韻律特徴を反映するトレーニングコーパスを生成してから、トレーニングコーパスを解析し、トレーニングコーパスの韻律特徴をモデリングするタグを生成することができる。
(もっと読む)
音声処理装置、音声処理方法および音声処理方法により作成されたフィルタ
【課題】
音声を強調する際のフィルタ特性を適切に制御できる音声処理装置を実現することである。
【解決手段】
実施形態の音声処理装置は、音声データから抽出された第1の音声特徴量から第1のヒストグラムを計算し、前記第1の音声特徴量とは異なる第2の音声特徴量から第2のヒストグラムを計算するヒストグラム計算手段と、前記第1のヒストグラムの度数を累積した第1の累積度数と、前記第2のヒストグラムの度数を累積した第2の累積度数とを計算する累積度数計算手段と、前記第1および第2の累積度数に基づいて、前記第2の累積度数を前記第1の累積度数に近づける特性をもつフィルタを作成するフィルタ作成手段とを備える音声処理装置である。
(もっと読む)
音素ラベリングデータ音素継続時間長変換方法とその装置とプログラム
【課題】少量の音素ラベリングデータから新音素体系の大量の音素ラベリングデータを精度良く生成する音素ラベリングデータ音素継続時間長変換装置を提供する。
【解決手段】音素継続時間長分布推定部は、変換対象話者の新音素体系における少数の音素ラベリングデータである参照ラベリングデータと、複数話者のある音素体系における音素種別の音素継続時間長の平均値・分散値を、統計的に信頼できる値として得ることが可能な数の複数話者ラベリングデータを入力として、参照ラベリングデータを複数話者ラベリングデータで直線回帰し、複数話者ラベリングデータの全ての音素種別に対応する変換対象話者の音素継続時間長の平均値と分散値である音素継続時間長分布を求め、1個の音素継続時間長に対して複数の音素情報を持つ音素ラベリングデータを、音素情報毎に時間長を分割して新音素ラベリングデータとして出力する。
(もっと読む)
音声合成装置、その方法及びプログラム
【課題】非テキスト情報を考慮して抑揚を変更することで、より自然性の高い合成音声を生成する技術を提供する。
【解決手段】返信情報を用いて、テキスト情報を会話テキストまたは非会話テキストに分類し、一つの被返信テキスト情報に起因する一連の会話テキストを一つの会話テキスト集合としてまとめ、会話テキスト集合に含まれる会話テキストに対応する投稿者情報に基づき、その会話テキスト集合の投稿者間の友好度を求め、会話テキストに含まれる単語に基づき、その会話テキストに対する評価を算出し、1つ以上の会話テキスト集合または非会話テキストを、その投稿順に並び替え、友好度が高いほど抑揚が大きくなるように、評価がポジティブであるほど抑揚が大きくなるように、テキスト統合ステップで並び替えられた投稿順に従ってテキスト情報に対する合成音声を生成する。
(もっと読む)
電子楽器
【課題】文字列が示す複数の音声を所望の複数のタイミングでそれぞれ発音させること。
【解決手段】文字列に基づいて複数の順序に複数の発音単位文字列を対応づける歌詞テーブルを作成する歌詞テーブル作成部と、入力装置が操作される複数の発音タイミングをその複数の順序に対応づける発音タイミング作成部と、その複数の発音単位文字列のうちの任意の順序に対応する発音単位文字列を示す音声がその複数の発音タイミングのうちのその任意の順序に対応する発音タイミングにスピーカから発音されるように、そのスピーカを制御する発音部とを備えている。このような電子楽器は、その文字列が示す複数の音声を入力装置への操作ごとに順番に発音させることができる。
(もっと読む)
音声合成装置及びその合成音声修正方法
【課題】 利用者により入力される音声入力を用いて、利用者の修正意図を適切に反映した合成音声の修正を行う。
【解決手段】 合成音声韻律抽出処理112によりテキスト情報に基づき音声合成処理107で生成された合成音声から合成音声韻律情報を抽出するとともに、入力音声分析処理111によって入力音声から入力音声韻律情報を抽出する。修正情報決定処理113は抽出された合成音声韻律情報と入力音声韻律情報から合成音声の韻律情報の修正値を決定する。音声修正処理114は、決定された修正値を用いて修正された合成音声を生成する。
(もっと読む)
11 - 20 / 495
[ Back to top ]