
国際特許分類[G10L15/10]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声の識別または探索 (1,500) | 未知音声と標準パタンとの距離または歪みを用いるもの (838)
国際特許分類[G10L15/10]に分類される特許
21 - 30 / 838
通話データ管理装置及び通話データ管理システム
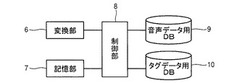
【課題】オペレータにかかる負担をなくし、音声データの分類の精度の低下を防止して、顧客のクレーム部分の精度高いデータ検索を可能にする。
【解決手段】顧客とオペレータとの電話での通話を音声データに変換して1処理毎の音声ファイルを音声データ用データベース9に蓄積し、蓄積した音声ファイル毎に音声データを読み出して、顧客の声のトーンから当該顧客によるクレームの有無を判断し、クレーム有りと判断した場合、その音声データにクレームであることを示すタグ種別データを付与すると共に、顧客の通話終了間際の声のトーンから当該顧客に対するオペレータの対応が適正か否かを判断して、オペレータの対応が適正、不適正に応じた対応タグデータを前記タグ種別データに付加してタグデータ用データベース10に格納する。
(もっと読む)
位置推定装置、位置推定方法、プログラムおよび位置推定システム

【課題】屋内にいる利用者の位置推定を精度よくかつ低コストで実現することを可能にする。
【解決手段】位置推定装置は、位置情報と音特性との対応関係を記憶する記憶部110と、集音器による集音結果から判定される音特性に対応する位置情報を前記記憶部から抽出する抽出部150と、固定電話端末に対して区画に設置された機器が発する区画識別音を制御する音制御部120と、利用者端末と通信を行う通信部130と、利用者端末の集音器による集音結果から区画識別音の音特性を判定する判定部140と、を備える。
(もっと読む)
言語モデル切替装置およびそのプログラム
【課題】少ない計算量で入力音声の話題を高精度に推定し、また話題の変化にも追従しながら、話題の推定結果に応じた最適な言語モデルを選択する。
【解決手段】話題特徴量記憶部は、言語表現の出現頻度の特徴を表わす話題特徴量データを話題毎に記憶する。フィードバック特徴量生成部は、音声認識結果データに基づいて言語表現の出現頻度の特徴を表わすフィードバック特徴量データを生成する。類似度計算部は、フィードバック特徴量データと話題特徴量記憶部から読み出した話題特徴量データとに基づく類似度を計算し、類似度に基づいて音声認識結果データの話題を推定する。言語モデル切替制御部は、類似度計算部によって推定された話題に対応する言語モデルを使用して入力音声を音声認識処理するよう言語モデルを切り替える。
(もっと読む)
発音複雑度算出装置、音声認識装置、発音複雑度算出方法、音声認識方法、及びプログラム
【課題】高い精度で発音の難しさを評価する。
【解決手段】発音複雑度推定装置100は、発音特徴抽出部110及び複雑度算出部120を有している。発音特徴抽出部110は、発音の仕方を示す記号を複数並べた記号列データから、2つ以上の前記記号の組み合わせである発音特徴データを抽出する。複雑度算出部120は、発音特徴データを用いて、記号列データに従った発音の複雑度を算出する。発音特徴抽出部110に入力される記号列データは、たとえば、言語の音声を表記する音声記号の列である。
(もっと読む)
音声制御システム、音声制御装置、音声制御方法および音声制御プログラム
【課題】ユーザの通話を監視して感情的な音声や危険語句をオペレータに伝達する前にマスキングなどにより一律に変換処理を行なうため、オペレータに判断を委ねることなく通話内容を制御すること。
【解決手段】ユーザ端末とオペレータ端末との通話を公衆電話網を介して確立させる電話交換手段と、電話交換手段により確立された通話をモニタしてユーザ端末とオペレータ端末との通話内容を音声情報として取得する通話モニタ手段と、通話モニタ手段により取得された音声情報中に認識されるユーザ端末の音声から、あらかじめ定められた特定の感情を表わす感情的音声または否定的な語彙を含む特定語彙の音声のうちいずれかの不穏当音声を検出する不穏当音声検出手段と、不穏当音声検出手段により検出された不穏当音声を制御した制御音声を生成する音声生成手段と、を備えることを特徴とする。
(もっと読む)
音声認識装置および音声認識プログラム
【課題】話題に応じて、高精度な音声認識結果を得る。
【解決手段】音声データに基づいて音響特徴量を算出する音響分析部50と、音響特徴量と発音ネットワークに対応する音響モデルとに基づき言語表現ごとの音響スコアを求め、また言語スコアを求め、音響スコアと言語スコアとに基づいて正解候補単語列を探索して認識結果テキスト情報を生成する正解単語探索部60と、話題情報から認識結果テキスト情報に対応する発話対応テキストを抽出する話題トラッキング部80と、話題情報から、発話対応テキストを含む発話相当付近テキストを抽出し、発話相当付近テキストに関連する関連テキスト情報をテキスト情報源2から取得し、言語モデルを関連テキスト情報に基づき適応化して更新する言語モデル適応化部90と、更新した際に適応化言語モデルに基づいて発音ネットワークおよび言語スコアメモリを更新する更新部62とを備える。
(もっと読む)
情報処理システム、情報処理装置、情報処理方法、端末装置及びプログラム
【課題】端末装置の所持者に手間をかけさせることを必須とすることなく、端末装置の現在位置を正確に特定する。
【解決手段】自装置の位置情報を取得し、当該位置情報を通話の際に送信する端末装置300と、端末装置300と通話を行う通話手段400と、端末装置300と通話手段400との通話にて取得される音声を解析し、当該音声から端末装置300の位置を特定可能な情報を抽出する情報抽出部100と、通話の際に端末装置300から送信されてきた端末装置300の位置情報と、情報抽出部100にて抽出された情報とに基づいて、端末装置300の現在位置を特定する位置特定部200とを有する。
(もっと読む)
音声データ書き起こし用WEBサイトシステム
【課題】ライブストリーミングのように一時停止ができない動画コンテンツまたは音声コンテンツ中の音声を、不特定多数のユーザが協調してリアルタイムに書き起こすことが可能な音声データ書き起こし用WEBサイトシステムを提供する。
【解決手段】判定部22は、断片テキストデータの入力時刻から所定の時間間隔T遡った所定の時間期間T内に配信された期間音声データPADを音声データ記憶部14から取得して、期間音声データPADの中に断片音声パターンPAPと音響的に適合する音声パターンとなる音声データ部分があるか否かを判定する。データ置換部23は、判定部22が音響的に適合すると判定した音声パターンとなる部分に対応する音声認識結果記憶部15に記憶されているテキストデータの該当テキストデータ部分を断片テキストデータまたは単語断片テキストデータで置き換える。
(もっと読む)
情報処理装置、ダイジェスト生成方法、及びダイジェスト生成プログラム
【課題】より適切なダイジェストを生成する。
【解決手段】情報処理装置において、所定時間撮影された1又は複数の被写体を含む映像情報及び音声情報を蓄積する蓄積部と、前記蓄積部に蓄積された映像情報及び音声情報を用いて、予め設定された1又は複数の要素に基づき、前記所定時間の時系列における所定の単位時間毎の変化量を評価し、評価された結果に基づいて1又は複数のダイジェスト候補を抽出するダイジェスト生成部と、を有し、前記ダイジェスト生成部は、前記ダイジェスト候補に対応する映像情報及び音声情報に含まれる被写体の状況又は特徴をパターン認識し、認識された結果に基づいて前記ダイジェスト候補からダイジェストを生成するパターン認識部を有する。
(もっと読む)
対話選別プログラム、対話選別装置、および対話選別方法
【課題】問題対話の選別を効率的かつ高精度におこなうことにより、モニタリングの作業効率の向上を図ること。
【解決手段】録音音声データを取得し、抽出部401により韻律情報抽出処理を実行する。つぎに、検出部402により発話区間検出処理を実行する。取得部405により音声認識結果情報を取得する。このあと、基本対話分析部403による基本対話分析処理、対話構造分析部404による対話構造分析処理、発話内容分析部406による発話内容分析処理を実行する。このあと、決定部407により決定処理を実行し、出力部408により出力処理を実行する。
(もっと読む)
21 - 30 / 838
[ Back to top ]