
国際特許分類[G10L15/10]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 音声認識 (6,879) | 音声の識別または探索 (1,500) | 未知音声と標準パタンとの距離または歪みを用いるもの (838)
国際特許分類[G10L15/10]に分類される特許
11 - 20 / 838
音声認識装置および音声認識方法
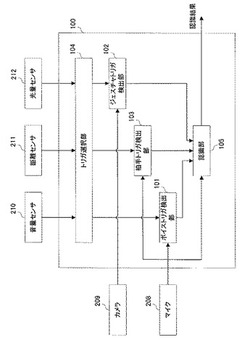
【課題】使用環境に適した開始トリガを選択する音声認識装置を実現することである。
【解決手段】本実施形態の音声認識装置は、複数のトリガ検出手段とトリガ選択手段と認
識手段とを備える。トリガ検出手段は、機器を操作するためのコマンド発声の認識開始を
指示する開始トリガを検出する。トリガ選択手段は、前記機器に設置された1又は複数の
センサからの信号に基づいて、前記複数のトリガ検出手段から前記機器の使用環境に適し
たトリガ検出手段を選択する。認識手段は、前記トリガ選択手段で動作を有効にされた前
記トリガ検出手段が、前記開始トリガを検出した場合、前記コマンド発声の認識処理を開
始する。
(もっと読む)
対話型情報発信装置、対話型情報発信方法、及びプログラム

【課題】できるだけ不快な印象を与えることなく、音声によって不特定多数の人間に効果的に情報を与える。
【解決手段】対話を行う複数の話者の発話内容を表す複数の発話情報を含む単数又は複数の対話情報から特定の対話情報を抽出し、複数の話者に対応する複数の音声出力部で、特定の対話情報に含まれる発話情報が表す発話内容の音声を出力する。話者に対応する前記音声出力部は、それぞれ、音声出力部に対応する前記話者の発話内容の音声を出力する。
(もっと読む)
音声認識装置、方法及びプログラム
【課題】音声認識精度を向上することにある。
【解決手段】一実施形態に係る音声認識装置は、業務推定部、音声認識部及び特徴量抽出部を含む。業務推定部は、利用者の業務に関連する非音声情報を用いて利用者が行っている業務を推定し、該業務の内容を示す業務情報を生成する。音声認識部は、前記業務情報に対応する音声認識手法に従って前記利用者が発した音声情報に対して音声認識を行い、音声認識結果を生成する。特徴量抽出部は、前記音声認識結果から、前記利用者が行っている業務に関連する特徴量を抽出する。前記業務推定部は、少なくとも前記特徴量を用いて前記利用者の業務を再推定し、前記音声認識部は、再推定の結果得られる業務情報に基づいて音声認識を行う。
(もっと読む)
音判定システム、音判定方法および音判定プログラム
【課題】音によるコンテキストの理解の妨げとなる類似音を認識対象音と区別して、正しいコンテキストの理解を可能とする。
【解決手段】1つ以上の集音手段によって収集された音のデータを用いて、集音手段が配された空間内の特性であって音源からの音に基づく音特性を計測する音特性計測手段101と、音特性計測手段101によって計測された音特性が認識対象音の音特性と合致するか否かを判定して、収集された音が認識対象音であるか類似音であるかを判別する類似音判別手段102とを備える。
(もっと読む)
音声解析システムおよび音声解析装置
【課題】音声取得手段にて音声を取得し、取得した音声の非言語情報に基づいて話者の心理状態を推定する。
【解決手段】使用者に装着される端末装置と、端末装置から情報を取得するホスト装置とを備える。端末装置は、マイクロフォンにより取得された音声を解析して発話者を識別すると共に、非言語情報である音声特徴量に基づいて発話者の精神活性度を推定し、推定結果を含む発話情報をホスト装置に送信する。ホスト装置は、複数の端末装置から取得した発話情報の中から特定の会話に係る発話情報を抽出して解析し、各発話者の精神活性度の組み合わせに基づいて、会話に参加している各発話者の感情を推定する。
(もっと読む)
音声認識装置とその方法とプログラム
【課題】話題境界を跨がない長距離文脈情報を用いて認識スコアを再計算する音声認識装置を提供する。
【解決手段】話題境界検出部が、Nベスト候補列を入力として、当該Nベスト候補列中の現在発話区間を中心として当該現在発話区間から音声文書の冒頭方向にある順位1位の認識結果候補を過去発話単語集合として抽出すると共に、当該現在発話区間を中心として当該現在発話区間から音声文書の末尾方向にある順位1位の認識結果候補を未来発話単語集合として抽出し、過去・未来間関連度平均値と所定の閾値とを比較して音声文書の話題境界を判定する。Nベスト候補スコア再計算部は、話題境界検出部において話題境界と判定されなかった現在発話区間の認識スコアを、過去・現在間関連度合計値と現在・未来間関連度合計値の平均値を用いた値に再計算し、現在発話区間のNベスト候補を並べ替える処理を行う。
(もっと読む)
対話支援装置、方法及びプログラム
【課題】話者が異なる言語で又は同じ言語で対話をする場合に、対話に応じて知識を補うための情報を提示して対話を支援することを可能にする。
【解決手段】実施形態によれば、入力部、音声認識部、対話履歴データベース、推定部、判定部、生成部、選択部、提示部を含む。入力部は、話者間の対話の音声を入力する。音声認識部は、入力音声を音声認識して、対応するテキスト情報に変換する。対話履歴データベースは、テキスト情報の全部又は一部を対話履歴として記憶する。推定部は、テキスト情報に基づいて、発話行為を推定する。判定部は、推定された発話行為に基づいて、補足情報を提示するかどうか判定する。生成部は、補足情報を提示すると判定された場合に、補足情報の候補を生成する。選択部は、対話履歴を利用して、補足情報の候補のうちから、提示すべきものを選択する。提示部は、選択された補足情報を提示する。
(もっと読む)
車両用路面判定装置及び運転支援装置
【課題】簡単な構成で路面状態を早期に判定できる車両用路面判定装置及び運転支援装置を提供することを課題とする。
【解決手段】路面状態毎に走行音の特徴量を学習しておき、車両の走行音を集音し、集音した走行音から特徴量を抽出し、学習データに基づいて抽出した走行音の特徴量に応じた路面状態(例えば、低摩擦係数の路面状態、自車両の車輪が車線の区画線上か否か)を判定し、判定した路面状態に応じて運転支援を実施することを特徴とし、ビームフォーミングを利用して自車両の各車輪の走行音や自車両周辺の他車両の走行音を取得し、自車両の車輪毎や自車両周辺の他車両の路面状態を判定するようにしてもよい。
(もっと読む)
音声言語評価装置、方法、及びプログラム
【課題】テキストレベルの言語表現への変換を行うことなく、また事前知識を要することなく、入力された音声信号が示す言語の種類を評価する。
【解決手段】音素表現計算部13で、学習用音声信号から抽出されたメルスペクトルをNMFにより分解して言語の種類毎に音素表現Hと配合比率Uとを求め、音素表現Hを音素表現記憶部14に言語の種類毎に記憶する。評価用音声信号が入力されると、特徴情報抽出部12で、メルスペクトルを抽出し、音素配合比率計算部15で、抽出されたメルスペクトルと、音素表現記憶部14に記憶された音素表現Hとに基づいて、言語の種類毎に配合比率Uを計算する。言語類似性評価部16で、計算された配合比率Uと音素表現記憶部14に記憶された音素表現Hとの積を言語の種類毎に各々計算し、評価用音声信号から抽出されたメルスペクトルとの類似度に基づいて、評価用音声信号が示す言語の種類を評価する。
(もっと読む)
音声出力装置、音声出力方法および音声出力プログラム
【課題】
多言語の音声を出力する音声出力装置において、聞き手集団の使用言語を理解していないことに起因する、情報提供の無駄を軽減する。
【解決手段】
音声出力内容を入力する音声出力内容入力部と、前記音声出力内容に基づいて複数の言語から成る出力音声を生成する出力音声生成部と、周囲環境の音声を入力する環境音声入力部と、前記入力した音声の言語を認識し、言語の構成比を算出する言語構成比算出部と、前記言語構成比算出部で算出した言語構成比に応じて、出力する音声の構成を変更する音声出力構成変更部と、変更された音声を出力する音声出力部と、を有する。
(もっと読む)
11 - 20 / 838
[ Back to top ]