
Fターム[2C028AA06]の内容
電気的に作動する教習具 (9,365) | 教習科目 (1,518) | 語学 (650) | 会話 (47)
Fターム[2C028AA06]に分類される特許
1 - 20 / 47
受講管理システムおよび受講管理方法
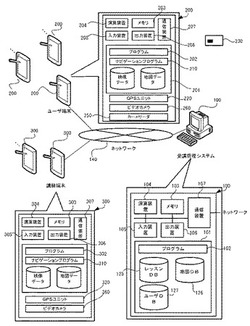
【課題】受講者が希望した臨場感ある状況での学習機会を提供し、受講者における学習効果や満足度を向上させる。
【解決手段】コンピュータが、入力装置105で受け付けるか、ユーザ端末200より受講要求を受けて記憶装置101に格納し、希望レッスンに対応する予習コンテンツを記憶装置101から読み出してユーザ端末200に配信する処理と、ユーザ端末200より送信された予習終了通知を受信し、希望レッスンの状況設定に対応する街路を記憶装置101にて特定し、希望レッスンの担当講師に関する情報を記憶装置101より特定し、前記特定した街路および担当講師に関する情報を含む開講通知をユーザ端末200に送信する処理と、開講通知の対象となった受講者の情報を記憶装置101から読み出し、この受講者の情報とレッスンを開講する街路の情報とを含む移動開始通知を講師端末300に送信する処理とを実行する。
(もっと読む)
異国語の学習補助システム

【課題】英語の単語を用いた文章に容易にアクセスできることで、英語の複数の和訳を理解しやすくする。
【解決手段】
英語の複数の単語群から選ばれた一つの単語の発音を発する英語発声部と、その英単語に対応した日本語の単語の発音を発する日本語の発声部とを備えると共に、その英単語が使われる単語を発声した後に、その複数の英単語の中から対応した英単語を用いた文章を発声するように構成した。また、得意な場合はその英単語に対応した和訳を早送り再生またはスキップするようにした。
(もっと読む)
和合トレーニング装置。
【課題】 利用者がステレオ音波出力器から出力される雰囲気音波を聴きながら、対象言語音声を雰囲気音波に和合させる発声語調のトレーニングを行なう和合トーニング装置の提供。
【解決手段】 トレーニング対象の歌の演奏メロディの雰囲気下で、各歌詞を和合する演奏メロディの複数の和合領域の開始時刻の△t前になると、和合する歌詞が個人通報器3から利用者1のみに通報され、利用者はステレオ音波出力器6からの演奏メロディの各和合領域の△t前に、和合発声すべき歌詞を直接聴くことができ、各和合領域B1、B2・・・では、直前に聴いて把握した正確な歌詞で、和合領域の演奏メロディに音程を狂わさずに和合して発声する発声語調のトレーニングを適確に且つ効果的に実行することが可能になる。
(もっと読む)
音声表示出力制御装置、画像表示制御装置、および音声表示出力制御処理プログラム、画像表示制御処理プログラム
【課題】音声,テキスト,画像などのデータを同期して出力するための音声表示出力制御装置であって、音声出力に同期した画像の表示において、アクセントのタイミングを明確に現すことを可能にする。
【解決手段】検索見出語「low」の発音音声出力に同期しウインドウW1にて見出語「low」およびその発音記号の識別表示HLが順次なされると共に、ウインドウW2では設定キャラクタ画像12d(No3)をベースとしその口画像エリアに対し各発音記号に対応した発音口型画像12e(No36→No9→No8)が順次切り替え合成表示される。しかもアクセント文字「o」に対する発音音声出力と同期した識別表示HLと口型画像12e(No9)の切り替え合成表示の際は、その合成先画像12d(No3)が例えば頭部発汗や口元動揺により強い発音を表現するアクセント対応顔画像12d(No3′)に変更表示される。
(もっと読む)
思考単位と連結質問を用いる言語教育方法
【課題】学習者の水準に応じて、聞き取り、発話、読み取り、書き込みの言語教育を効果的に学習し得るように、教育過程をインターネットとマルチメディアを用いて提供するシステム及び方法を提供する。
【解決手段】前記システムは、文章を思考単位に格納し、思考単位に対応する連結質問をテキストデータとして格納し、学習順に従って、格納された思考単位及び連結質問のテキストデータを伝送させる情報提供者装置と、情報提供者装置から出力された思考単位及び連結質問のテキストデータを受信して出力し、入力されたテキストデータを情報提供者装置に伝送する加入者装置とを含み、前記方法は、文章を思考単位と思考単位に対応する連結質問に分けて格納し、加入者の学習段階情報と学習プログラム進行方法を入力し、学習資料を抽出し、抽出された学習資料が加入者のターミナルに出力されるように制御することからなる。
(もっと読む)
思考単位と連結質問を用いる言語教育方法
【課題】学習者の水準に応じて、聞き取り、発話、読み取り、書き込みの言語教育を効果的に学習し得るように、教育過程をインターネットとマルチメディアを用いて提供するシステム及び方法を提供する。
【解決手段】前記システムは、文章を思考単位に格納し、思考単位に対応する連結質問をテキストデータとして格納し、学習順に従って、格納された思考単位及び連結質問のテキストデータを伝送させる情報提供者装置と、情報提供者装置から出力された思考単位及び連結質問のテキストデータを受信して出力し、入力されたテキストデータを情報提供者装置に伝送する加入者装置とを含み、前記方法は、文章を思考単位と思考単位に対応する連結質問に分けて格納し、加入者の学習段階情報と学習プログラム進行方法を入力し、学習資料を抽出し、抽出された学習資料が加入者のターミナルに出力されるように制御することからなる。
(もっと読む)
英会話超速メソッド英語教具
【課題】やみくもに英語を聞き流しているだけでは、日本語にはない英語特有の音を聞き逃してしまう。リスニング力をつけるために、それらを意識できる教具を提供する。
【解決手段】具体的内容:
(1) 英語を聞きながら日本語を読む(2) 日本語を聞きながら英語を読むこの2つの作業を、CD教具使用し、低速から高速へと速度を3段階に変えながら交互に行う。英文を目で追いながら日本語を聞く、和文を目で追いながら英語を聞く、という動作を、速度を徐々に上げながら行う。このような単純な作業で、リスニング力、英語理解力を飛躍的に向上させることが期待できる。トレーニングを続けることで、英文一つ一つが意味を持った言葉として自然と頭に入ってくるようになる。さらに、リスニングのみならず、リーディング力、スピーキング力も同時に向上し、総合的な英会話力が身に付く。
(もっと読む)
データ処理装置
【課題】データベース構築のために必要な種々のコストを低減する。
【解決手段】任意の記録媒体に記録された会話文からなるデータを表示する表示手段と、上記表示手段によって表示されたデータのうち、ユーザが任意に指定した全部又は一部のデータを取り込み、前記取り込まれた会話文からなるデータの会話の類型を示す属性情報を上記表示手段に表示するとともに、当該表示手段に表示された会話の類型を示す属性情報の中から少なくとも1つの属性情報をユーザが指定して上記取り込まれた会話文からなるデータに付加する付加手段と、上記付加手段によって属性情報が付加されたデータを、当該データに付加された会話の類型を示す属性情報とともに記憶する記憶手段と、上記記憶手段に記憶された会話の類型を示す属性情報に基づいて、一連の会話を成立させる会話出力手段とを有する。
(もっと読む)
バイリンガル二重字幕
【課題】従来の字幕では、音声を完全に翻訳した字幕が表示されるだけであるので、音声で、どういう単語や言葉を話しているのかを聞き取ることは困難であった。
さらに、異なる二つの言語においては、文章を構成する要素である主語、述語、目的語、修飾語等の語順が異なることがある。そのため、文章を完全に翻訳した従来の字幕では、原語と語順が異なるために、音声を聞き取りながら、意味を理解することは困難であった。
そのため、従来の字幕は、映画等を語学学習に利用したい人にとって、利用し難いものであった。
この発明は、これらの課題を解決するためになされたものである。
【解決手段】画面1において、音声2を原語で表記した字幕4を意味のまとまりごとに分割し、意味のまとまりごとに翻訳した字幕5を原語の順番に従って表示することにより、音声の聞き取りと同時に意味の理解を行うことを容易にした。
さらに、音声2を完全に翻訳した字幕3を併記することにより、音声2を完全な日本語として理解しやすくした。
(もっと読む)
通信監視システムおよびその監視方法
【課題】設備投資のコストを抑制しても、サービス品質の維持やサービス品質の向上を容易にすることができる通信監視システムおよびその監視方法を提供。
【解決手段】レッスン監視システム10は、WEBアクセッサコンポーネントのプレゼンス管理部、シグナリング管理部および監視管理部で扱う各情報を管理し、連携管理部でWEBシステム12との通信を連携させ、SIPアクセッサコンポーネント40のプレゼンス管理部104、シグナリング管理部106、監視管理部108で扱う各情報を管理し、連携管理部110でSIPシステムとの通信を連携させ、WEBシステム12のマッチングAP 100でSIPシステムとWEBシステム12のクライアントが有する情報を取得し、マッチングさせ、マッチングに対応する情報をクライアントに回答し、回答の情報を基にSIPシステムの監視APで両システム間の通話を監視する。
(もっと読む)
音声データ処理システム、音声データ処理方法、及びプログラム
【課題】言語学習用の会話文等を録音してなる音声データにおいて、話者の切り替え位置を検出すること。
【解決手段】音声データ処理システム1において、複数人の音声を一人分ずつ録音してなる音声データを取得する音声データ取得部12と、上記音声データに所定のパターン認識処理を施し、該パターン認識処理の結果に基づいて、上記音声データを音声を発した人ごとの部分に分類する分類部13と、分類部13の分類結果に基づき、上記音声データ中の話者の切り替え位置を決定する位置決定部14と、を含むことを特徴とする。
(もっと読む)
音声データ再生装置、音声データ再生プログラム及び発話練習装置
【課題】電話応対の練習を効率よく一人で行うのは困難である。
【解決手段】装置に蓄積される音声データを相手側(応答パート)と自分側(練習パート)に分類して管理する。そして、応答パートと練習パートのいずれから開始するかを示すフラグを備え、このフラグで開始順を制御する。
(もっと読む)
発話試験および療法のための乱されない発話生成
人の乱されない発話生成のためのシステムをもつ発話解析システムおよび人の発話生成を解析するための方法。発話解析システムは人による乱されない発話生成を許容する。システムはまず試験文を書き出し、それをクリアし、その後、その人に正しい表現を思い出させるために一連の視覚的手がかりをその人に対して示す。その人は前記文を思い出し、それを正確に繰り返すが、その際、文字を通じた影響は全く受けない。方法は、その人の発音に影響することなく、その人に正確な文を思い出させる視覚的手がかりを提供する。
 (もっと読む)
(もっと読む)
外国語学習通信システム
【課題】集中力が未発達な乳幼児の日常生活の中で、母国語で行われる母親や保護者の語りかけや家族の会話をリアルタイムに外国語に翻訳し母国語と外国語を同時に聴かせることで両方の言語の運用能力開発を支援することができる外国語学習通信システムを提供する。
【解決手段】外国語を学習する利用者側に設置する利用者用パソコン102と、外国語を学習させるため通訳を行なう通訳者側に設置する通訳者用パソコン103とが、センターに設置されるセンターコンピュータ101にネットワーク104を介して通信自在に接続される外国語学習通信システムであって、前記利用者用パソコン102は、利用者側の会話を集音する集音手段と、集音手段によって、集音した音声信号を前記センターコンピュータ101に送信する送信手段と、センターコンピュータ101から音声信号を受信する受信手段と、受信した音声信号を再生する音声再生手段とを備えている。
(もっと読む)
音声再生装置
【課題】聞き取りにくい単語を含む音声のヒアリング学習に貢献する。
【解決手段】複数のテキストデータから再生すべき文章が指定され(ステップS1)、テキストデータ中から音声加工の対象となる対象単語が抽出される(ステップS2)。次に、実際に音声加工を行う処理単語の語数が決定され(ステップS3)、抽出された対象単語から処理単語が決定される(ステップS4)。決定された処理単語の位置に、音声合成プログラムに対応したコマンドが挿入される(ステップS5)。例えば、コマンド[!mute]をテキストデータに挿入することにより、その直後の単語を消音させることができる。次に、コマンドが挿入された後のテキストデータが音声データに変換され(ステップS6)、音声データに基づいて音声が出力される(ステップS7)。
(もっと読む)
音評価システム
【課題】音評価システムにおいて、ユーザを含む複数の評価者による客観的評価に近い評価結果を得る。
【解決手段】ユーザ端末14(1)では、実歌唱信号と基準歌唱信号とで音響特徴を分析・比較してピッチずれ等の比較結果を得る。実歌唱信号についてユーザ等の評価者に採点を行なわせる。比較結果、採点結果等のデータを通信ネットワーク10を介してサーバ18に送る。14(2)等の端末についても同様とする。サーバ18は、曲毎に複数のユーザ端末からのデータを記憶する記憶部を有する。サーバ18では、あるユーザ端末における比較結果に基づいて評価処理により第1の採点結果を求め、ユーザ端末に表示させる。この際に、ユーザ端末の歌と同一の曲に関する複数の採点結果に基づいて目標採点結果を求め、この目標採点結果に近づくように評価処理を修正して第2の採点結果を求め、ユーザ端末に表示させる。
(もっと読む)
語学学習システム
【課題】学習者に授業の単調さを感じさせないようにして、学習意欲が低下するのを防止する。
【解決手段】学習者に語学学習の授業を提供する学習サーバ装置200は、PC100から送信される学習者の語学学習の音声を解析して学習者の発音を採点するとともに、学習者の声紋を記憶する。また、学習サーバ装置200は、PC100から送信される学習者の音声中における発話時間を計時して記憶する。学習サーバ装置200は記憶した発話時間を参照し、発話時間の合計時間に応じて、学習者の学習意欲を向上させるメッセージを学習者に送信する。
(もっと読む)
学習支援装置
【課題】コンピュータ装置を利用して語学学習を行う学習者に、そのユーザの習得レベルに応じた学習コンテンツを提供することを可能にするとともに、提供するコンテンツの画一化を回避すること。
【解決手段】語学学習用の複数の学習コンテンツを記憶し学習者からの要求に応じて何れかの学習コンテンツを返信する学習支援装置に、返信するべき学習コンテンツを指定することなく送信要求が為された場合には、その学習者が直近に学習した学習コンテンツの難易度および他の学習者による利用頻度に応じて絞り込まれた1つの学習コンテンツを返信させる。
(もっと読む)
評価装置、評価方法及びプログラム
【課題】模範音に対して臨場感を与えるような効果を付与して再生しつつ、その模範音と学習者の発音や演奏音とをより正確に比較する。
【解決手段】予め決められた模範音を示す模範音データと、当該模範音に付与する効果の内容を表した効果付与データとを対応付けて記憶しておく。このようにすれば、模範音データに対して効果付与データが表す効果を付与して再生させることが可能であるとともに、模範音データと効果付与データとを分離させることも容易である。よって、模範音声と学習者の発音とを従来よりも正確に比較することが可能となる。また、学習者の発音に効果を付与して再生することにより、例えば自動車のクラクションや走行音或いは人々の話し声といった効果音(雑音)の中で自らの発音がどの程度聞きやすいかといったことを確認することも可能となる。
(もっと読む)
英会話学習装置
【課題】効率よく英会話を学習することを可能とする装置を提供する。
【解決手段】通常日本文、英語語順日本文、時制イメージ、英文を順次表示し、その後該表示と共に英文のネイティブ発音を発生させ、これを真似て発音することにより学習する個人対応型英会話学習装置において、前記学習者の発音内容を音声認識して採点し、該採点により次に表示するセンテンスのレベルを自動的に変動させると共に、複数のセンテンスからなる教材の消化率が100%に達するまで前記学習課程は自動的に進行する。前記レベルが、通常日本文、英語語順日本文、時制イメージを順次表示する間の時間及びその後該表示と共に英文のネイティブ発音を発生させるまでの時間を制御することによって行われる。また、1つの教材に前記センテンスを数十〜数百用意し、各センテンスは順にレベルを上げていって最低でも5回繰り返す。前記センテンスはランダムに選択されて表示される。
(もっと読む)
1 - 20 / 47
[ Back to top ]