
Fターム[5B013DD01]の内容
Fターム[5B013DD01]に分類される特許
101 - 120 / 135
SIMD方式プロセッサ、当該SIMD方式プロセッサを利用する画像処理方法、及び画像処理装置

【課題】 2つ以上の連続する画素データ範囲をビット分割されたレジスタに格納して処理ステップを減少させ、無効画素の割合を減少させて処理の更なる効率化を達成する。
【解決手段】 プロセッサエレメントに内蔵のレジスタのビット幅を、N個のグループにビット分割し、プロセッサエレメント数以下の画素数の第1の画像データ範囲を、第1端から順に、該プロセッサエレメントに内蔵のレジスタのM番目のグループに記憶させ、第1の画像データ範囲に続く前記プロセッサエレメント数以下の画素数の第2の画像データ範囲を、第1端の反対端である第2端のプロセッサエレメントから逆順に、該プロセッサエレメントに内蔵のレジスタのM番目グループ以外のグループに記憶させ、第1の画像データ範囲の画像処理と第2の画像データ範囲の画像処理を、第2端のプロセッサエレメントを境に連続する画素データを参照して行う。
(もっと読む)
SIMD並列処理の自動選択を備えたマイクロプロセッサ

【解決手段】1又は複数の処理要素の電力及びエネルギーの自動選択制御は、高度な並列プログラマブルデータプロセッサにおいてモニタされた条件に、並列処理の程度を一致させる。例えば、並列プロセッサのロジックは、(例えば、特定のタスクのため、又は、検出された温度によって)プログラム動作が、データパスの全幅未満を必要とするときを検出する。これを受けて、制御ロジックは、並列処理能力のサブセットを要求する動作モードを自動的に設定する。すなわち、必要とされない少なくとも1つの並列処理要素は、エネルギーの節約、及び/又は、熱(すなわち、電力消費)を下げるために停止される。後に、能力を追加する動作が適切な場合、ロジックは、処理条件の変化を検出し、動作モードを、一般には全幅のようなより広いデータパスのモードへ自動的に設定する。このモード変化は、以前に停止された処理要素を再起動する。 (もっと読む)
スーパースカラ処理装置内の指示送出制御
【課題】並行実行能力を完全に使用し、処理能力を縮小させることのないデータ処理システムを提供する。
【解決手段】多重実行段階E1,E2,E3をそれぞれ備え、もし古い指示のためのオペランド値の結果が、新しい指示の入力オペランド値として上記オペランド値の結果を必要とする実行段階に優先する実行段階において生成されることが検出された場合に、それらの間にデータ依存性があるにもかかわらず、並行して同時に指示が送出される可能性があり、従って、データ依存性を解決するために実行パイプライン間のオペランド値の交差転送(cross-forwarding)が可能となる多重実行パイプラインを備えるデータ処理システム。
(もっと読む)
プログラム可能回路網を含むデジタル信号プロセッサ
本発明は、複数のメモリユニット、複数のアクセラレータユニット、及びプロセッサコアを含むプログラム可能デジタル信号プロセッサに関する。デジタル信号プロセッサには、更に、メモリユニットと、アクセラレータユニットと、プロセッサコアとの間に選択的に接続性を提供するように構成し得るプログラム可能回路網が含まれる。各アクセラレータユニットは、1つ以上の専用機能を実施するように構成し得る。プロセッサコアには、データ経路フロー制御に関連する命令を実行するように構成し得る実行ユニットを含み得る。プログラム可能回路網は、特定の命令の実行に応じて、選択的に接続性を提供するように構成し得る。  (もっと読む)
(もっと読む)
ビジュアルメディアの統合処理のための統合アーキテクチャ
本発明は、複数の処理レイヤを通して、拡張可能な分散処理及びメモリ能力を有するシステムオンチップアーキテクチャに関する。本発明の1つの応用は、全てのビジュアルメディア用のシングル統合処理チップを利用したビデオとグラフィックの処理と通信を実現するために設計された、新規のメディア処理デバイスである。 (もっと読む)
モノリシック構成のシリコン・チップ上に多数のグラフィックス・コアを用いるグラフィック処理及び表示システム
協働して、様々なアプリケーションのための写実的なグラフィックス能力をサポートする強力で高度にスケーラブルな視覚化解決法を提供するグラフィック処理ユニット(GPU)の多数のコアのクラスタをサポートする、モノリシック・シリコン・チップ上に実現された高性能のグラフィックス処理及び表示システム・アーキテクチャである。本発明は、種々の並列レンダリング技術を動的に管理し、主グラフィックス・アプリケーションの適応処理を可能にすることによって、グラフィックス・パイプラインに沿ったレンダリング・ボトルネックを排除する。 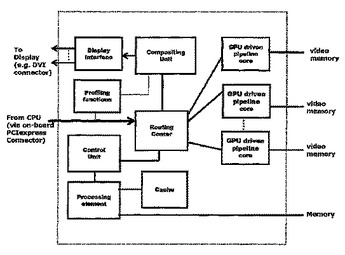 (もっと読む)
(もっと読む)
ILP及びTLPを利用する再構成可能なプロセッサアレイ
本発明による処理システムは複数の処理素子を有し、前記複数の処理素子が、処理素子の第1セットと少なくとも処理素子の第2セットとを有する。前記第1セットの各処理素子は、1つのレジスタファイル及び少なくとも1つの命令発行スロットを有し、前記命令発行スロットは、少なくとも1つの機能ユニットを有する。このタイプの処理素子は、命令レベル並列性を持たない又は非常に低い命令レベル並列性を持つスレッドの実行専用である。前記第2セットの各処理素子は、1つのレジスタファイル及び複数の命令発行スロットを有し、各命令発行スロットは少なくとも1つの機能ユニットを有する。このタイプの処理素子は、高い命令レベル並列性を持つスレッドの実行専用である。全ての処理素子は、共通の制御スレッドの下で命令を実行するように構成される。前記処理システムは、更に、前記処理素子全体で通信するように構成された通信手段を有する。このようにして、前記処理システムは、アプリケーションにおけるスレッドレベル並列性と命令レベル並列性との両方又は両方の組み合わせを利用することができる。  (もっと読む)
(もっと読む)
タイムステーショナリプロセッサにおける条件動作のためのサポート
タイムステーショナリ符号化の場合、プロセッサの命令セットの部分になる全ての命令は、単一のマシンサイクルで実行されなければならない完全な命令を制御する。これらの命令は、データパイプラインをトラバースするいくつかの異なるデータ項目を処理していてもよい。タイムステーショナリ符号化は、より大きなコードサイズの犠牲として、命令においてもたらされる制御情報を遅延させるために必要とされるハードウエアのオーバヘッドを節減するため、特定用途向けプロセッサにおいてしばしば使用される。タイムステーショナリプロセッサの不利点は、条件命令をサポートしていないことにある。本発明は、プログラムによって得られる制御情報を使用して、タイムステーショナリプロセッサのレジスタファイルへの結果データのライトバックを動的に制御することを提供する。実行時間における結果データのライトバックを制御することによって、条件命令はタイムステーショナリプロセッサによって実現され得る。  (もっと読む)
(もっと読む)
演算処理装置
【課題】回路規模の増大を抑制しつつ、1つの命令で実行可能な処理のバリエーションを増加させる。
【解決手段】デコード部40で解読される命令の所定位置に、その命令にモードを付与するためのビット値が設定し、モード判定部40aは、命令の所定位置に設定されたビット値に基づいて、その命令に付与されたモードを判定し、デコード部40は、命令に付与されたモードに基づいて、その命令で指定された処理を実行するベクトル演算器10c、10dを起動するとともに、その命令で指定された処理と異なる処理を実行するベクトル演算器10c、10dを起動するとともに、異なる読み出し先のベクトルレジスタ20bを各ベクトル演算器10c、10dに割り当てる。
(もっと読む)
情報処理システム,パイプライン処理装置,ビジー判定プログラム及び同プログラムを記録したコンピュータ読取可能な記録媒体
【課題】 パイプライン処理装置において、リクエストがパイプラインレジスタの中途に保持されている段階で、当該リクエストをパイプラインレジスタの最終段にそなえられたレジスタへ格納するための、かかるレジスタのビジー判定を、ハード資源を増大させることなく、確実に実行できるようにする。
【解決手段】 パイプラインレジスタ12に介装された、リクエストが有効リクエストであるか否かの判定を行なう判定部23からリクエストキュー13までの間のレジスタ12aにおける、有効リクエストの数をカウントする第1カウンタ25と、この第1カウンタ25によってカウントされる有効リクエスト数に基づいて、リクエストキュー13がビジー状態であるか否かを判定するビジー判定部22とをそなえ、判定部23が、ビジー判定部22によるビジー状態判定結果に基づいて判定を行なうようにする。
(もっと読む)
マルチスレッドのコンピュータ処理を提供する装置および方法
簡潔に述べると、本発明の実施例に従うと、マルチスレッドされたコンピュータ処理を提供する装置および方法が提供される。本装置は、マルチバンク・キャッシュ・メモリ、命令プリデコード・ユニット、乗加算ユニット、コプロセッサおよび/または変換索引バッファ(TLB)を共有するために適合した第1および第2演算処理ユニットを含む。本方法は、少なくとも2つのトランザクション開始者間でマルチバンク・キャッシュ・メモリの共有使用を含む。  (もっと読む)
(もっと読む)
プロセッサ中の再構成可能論理
処理構成要素のアレイを具備するデータプロセッサにおいて、アレイ中の各処理構成要素はそれぞれ構成可能論理ユニットを備え、それによって、各処理構成要素の論理能力を、意のままに再構成することができる。メモリに構成命令が予めロードされていてもよく、それによって、各処理構成要素の構成状態は、予めロードされたメモリから自動的に順に取り出すことができる。メモリはグローバルであってもよく、このケースでは、同じ関数を実行するようにCLUを並列に再構成してもよい。代わりに、異なるCLUが異なる関数を実現するように、メモリは各処理構成要素に対してローカルであってもよい。スレッド切り替えにおいて、プログラムの制御のもと構成を実行してもよい。それぞれの処理構成要素は、マイクロコード記憶中の多数の構成から特定の構成を実行時において選択してもよい。プロセッサは好ましくはSIMDプロセッサである。 (もっと読む)
演算処理装置
【課題】複数の演算リソースを共有し、複数の命令ストリームを同時に実行することが可能なDSPにおいて、複数の命令ストリームをより高速に処理できるようにする。
【解決手段】同一の命令ストリームStream1−1,1−2,1−3を連続して実行する場合、最初の命令ストリームStream1−1を実行することにより得られる、命令ストリームStream1−1,1−2,1−3が必要とする演算リソース数を管理テーブル上に格納する。後続の命令ストリームStream1−2,1−3を実行する際には、管理テーブル上に格納されている演算リソース数を参照することにより、後続の命令ストリーム1−2,1−3の並列実行が可能か否かを判断する。
(もっと読む)
マイクロプロセッサアーキテクチャ
マイクロプロセッサアーキテクチャは、単一命令多重データSIMDアレイ中に配置され、特定の命令タイプの命令を処理するようにそれぞれ動作可能な複数の処理素子と、複数の実行装置を含み特定の命令タイプの命令を処理するようにそれぞれ動作可能な逐次プロセッサと、複数の命令を受信し、受信された命令の命令タイプにしたがって、受信された命令を実行装置へ分配するように動作可能な命令制御装置とを具備している。逐次プロセッサの実行装置は並列にそれぞれの命令を処理するように動作可能である。 (もっと読む)
マルチプロセッサシステムにおいて命令を処理するための方法と装置
【課題】従来の処理アーキテクチャに起因して処理能力が失われてしまう不利益を最小化する、処理パイプラインの改良された実装技術を提供する。
【解決手段】方法は、共有メモリ106と各々がローカルメモリ104を含む複数の並列プロセッサ102との間の一つ以上のデータのブロックを転送するステップと、プロセッサ102内でデータキャッシングに依存ないように一つ以上のプログラムがコードされるよう、一つ以上のプロセッサ102のローカルメモリ104内で一つ以上のプログラムを実行するステップと、プロセッサ102の命令バッファのローカルメモリ104から約3つより多くないの命令をバッファに保留するステップと、を備え、各々のプロセッサ102の命令バッファは、プロセッサ102内でデータキャッシングに依存しないように一つ以上プログラムがコードされるときに、実質的に最大限の効率を持って命令が処理できるよう適合される。
(もっと読む)
プロセッサ
【課題】 比較的高速に動作する場合にあっても適正なタイミングで命令列を読み出すことによって高い処理能力が得られるプロセッサを提供する。
【解決手段】 メモリ101から命令をフェッチするフェッチ部107a〜107dの各々が、転送された命令を蓄積するフェッチ・バッファ109a〜109dの1つ、フェッチ・バッファ109a〜109dのうち対応するものの命令データの蓄積状態に基づいて命令データ転送の緊急度を設定すると共に、命令データ転送を要求する命令データ転送要求信号と緊急度を示す信号を出力して命令データ転送を要求するプログラム制御部105a〜105dの1つを備える。また、緊急度に基づいて命令データ転送の優先順位を設定し、設定された優先順位にしたがってフェッチ部107a〜107dのフェッチ要求にかかる命令を前記メモリから読み出すメモリ制御部103によってプロセッサを構成する。
(もっと読む)
単一命令複数データ実行エンジンのフラグレジスタのための評価ユニット
ある実施例によれば、評価ユニットが、単一命令複数データ(SIMD)実行エンジンのフラグレジスタのために提供され得る。例えば、水平評価ユニットは、前記SIMD実行エンジンによって複数のベクトルに渡って処理される評価オペレーションを実行し得る。ある実施例によれば、垂直評価ユニットは、複数のフラグレジスタに渡って評価オペレーションを実行し得る。 (もっと読む)
プロセッサおよび演算処理方法
【課題】 パイプライン処理を行うプロセッサにおいて、レジスタのゲート数を低減しつつ、複数のタスクあるいはスレッドを効率的に処理すること。
【解決手段】 パイプライン処理装置1は、レジスタファイルに代えて、メモリによって構成されたレジスタ用メモリ100を備えていると共に、PCを構成するレジスタに代えて、メモリによって構成されたプログラムカウンタ用メモリ30を備えている。したがって、これらをレジスタによって構成する場合に比べ、レジスタのゲート数が低減すると共に、コンテキストの入れ替えを行うことなく、アドレスの指定によってコンテキストスイッチを行うことができるため、複数のタスクあるいはスレッドを効率的に処理することが可能となる。
(もっと読む)
スーパースケーラマイクロプロセサに於て命令をリタイアさせるシステム及び方法
【課題】 高速でコンパクトなスーパースケーラマイクロプロセッサを実現する。
【解決手段】 1つ以上の各命令に同時にアドレスを付与するスーパースカラーレジスタリネーミング回路と、命令をプログラム順序外で実行する複数の機能ユニットと、命令の実行結果をストアするバッファであって、各命令に付与されたアドレスが、実行結果をストアするバッファ内の位置を示すバッファと、リタイアされた命令の実行結果を提供するように参照される複数のアレイ位置を含むレジスタアレイと、実行された命令がリタイア可能か否かを決定するリタイアメント制御ブロックと、リタイア可能な命令群の各命令の実行結果をレジスタアレイ内のアレイ位置に同時に関連付けてリタイア可能な命令群を同時にリタイアさせる命令リタイアメントユニットを備えた1つ以上の命令をプログラム順序外で実行するように構成したものである。
(もっと読む)
SIMD命令をサポートするプログラマブルデータ処理回路
データ処理回路は、SIMD命令を有する命令セットを有する命令実行回路を有する。命令実行回路は、SIMD命令に応答して、N個の各自の同一の処理を実行するよう構成される複数の算術回路を有する。SIMD命令は、第1レジスタと第2レジスタとの選択を規定する。SIMD命令は、アドレス指定されたレジスタからのSIMD命令のN個の各自のSIMD命令オペランドの第1及び第2系列を規定する。各算術回路は、SIMD命令の実行時、第1及び第2系列からそれぞれ各自の第1オペランドと各自の第2オペランドとを受け付ける。命令実行回路は、部分的に重複するように、第1及び第2系列を選択するよう構成される。好ましくは、少なくとも1つの系列のオペランドのポジションは、好ましくは、オペランドデータの制御の下、プログラム制御下にある。好ましくは、プログラムコントロールは、第1レジスタのスタートに関して系列のスタートを選択し、当該系列は、第1レジスタのスタートにおいてスタートしない場合、第2レジスタにおいて実行される。
 (もっと読む)
(もっと読む)
101 - 120 / 135
[ Back to top ]