
Fターム[5B013DD01]の内容
Fターム[5B013DD01]に分類される特許
21 - 40 / 135
マルチスレッド処理装置

【課題】スーパースカラ動作を行うマルチスレッド処理装置において、スレッドの作動割合を適切に調整すること。
【解決手段】複数のスレッドがハードウエアを部分的に共有して処理を行なうと共に、前記複数のスレッドの少なくとも一部がスーパースカラ動作を行うマルチスレッド処理装置であって、各スレッドの作動割合を設定する作動割合設定手段と、スレッド毎のスーパースカラ動作状況を監視する監視手段と、を備え、前記作動割合設定手段は、前記監視手段により把握されたスーパースカラ動作の時間あたりの発生回数が、設定されている作動割合に対して少ないスレッドの作動割合が増加するように、前記複数のスレッドのうち少なくとも一部の作動割合を修正することを特徴とする、マルチスレッド処理装置。
(もっと読む)
エネルギー効率のよいマルチコアプロセッサのための共用メモリ

本明細書では、プロセッサリソースを共用するように適合されたマルチコアプロセッサに関連した技術が説明される。一例示的マルチコアプロセッサは複数のプロセッサコアを含むことができる。マルチコアプロセッサはさらに、複数のプロセッサコアのうちの2つ以上に選択的に結合される共用レジスタファイルを含むことができ、共用レジスタファイルは、選択されるプロセッサコア間で共用リソースとして働くように適合される。 (もっと読む)
スーパースカラプロセッサ及びその命令処理方法
【課題】インオーダ処理の命令スケジューリングの簡潔さを損なうことなく、並列度を向上することができるスーパースカラプロセッサ及び命令処理方法を提供する。
【解決手段】命令メモリ101から読み出した命令を命令バッファ103に格納する前に事前にスケジューリングパターンを生成するプレスケジューラ110と、プレスケジューラ110で生成したスケジューリングパターンに基づき、命令バッファ103に格納された命令の依存関係をチェックし複数の命令デコーダ105、106に命令の発行を行うと共に、複数の実行ユニット107、108での命令の実行順序を決定するスケジューラ104とを備える。
(もっと読む)
アライメントまたはブロードキャスト命令を含むマルチメディア・コプロセッサの制御メカニズム
【課題】複数コプロセッサへの命令のビット空間をよりよい方法にする。
【解決手段】プロセッサに基づくシステム22はメイン・プロセッサ24および複数のコプロセッサ26を含む。コプロセッサ26によって実行されるデータ処理動作を指定するメイン・プロセッサ24のコプロセッサ命令は、ターゲット・コプロセッサを識別するためのコプロセッサ識別フィールドを含む。データ要素はソース・レジスタからデスティネーション・レジスタへブロードキャストされる。データ要素のサイズ指定は、2つのビットがバイト(8ビット),ハーフ・ワード(16ビット),ワード(32ビット)およびダブル・ワード(64ビット)を含む4つのデータ・サイズのうちの1つを示し、他の2ビットは飽和タイプを示す。
(もっと読む)
信号処理装置
【課題】専用ハードウェアや高性能なSIMD型処理装置を用いることなく、処理の高速化を実現することができる信号処理装置を得ることを目的とする。
【解決手段】処理命令を発行する全体制御部1に対して、部分制御部21〜2N、データ転送部31〜3N及びデータパス部41〜4Nが並列に接続されており、全体制御部1が相互に異なる処理命令を部分制御部21〜2Nに発行し、あるいは、同一の処理命令を少なくとも1個以上の部分制御部2に発行することで、処理の並列化を実現する。
(もっと読む)
分散型プロセッサシステムにおけるデータマルチキャスティング
一般に、分散型プロセッサアーキテクチャにおけるデータマルチキャスティングに関する方法、手順、装置、コンピュータプログラム、コンピュータアクセス可能媒体、処理構成、およびシステムが説明される。様々な実装形態は、ソースから第1のメッセージを受信するように構成された複数のターゲット命令を識別することと、ターゲット命令によって一般に共有される選択された情報を含めて、ターゲット命令のそれぞれに関して第1のメッセージにターゲットルーティング命令を提供することと、識別されたターゲット命令のうちの2つがルータに対して互いに異なる方向に配置されているとき、第1のメッセージを複製して、複製されたメッセージを、識別されたターゲット命令のそれぞれに対して異なる方向にルーティングすることを含むことが可能である。ターゲットルーティング命令を提供することは、ターゲット命令によって一般に共有され、左オペランド、右オペランド、またはプレディケートオペランドとして識別されているビットのサブセットを利用する、選択された情報をさらに含むことが可能であり、ターゲット命令の複数の複数命令サブセットのうちの1つの選択を含むことが可能である。 (もっと読む)
データ要素に対するデータ処理操作を並列に実行するためのデータ処理装置及び方法
【課題】SIMD処理に係るデータ処理装置及び方法を提供する。
【解決手段】データ処理装置及び方法は、データ要素に対するデータ処理操作を並列に実行するために提供される。データ処理装置は、データ要素を記憶することができる複数のレジスタを有するレジスタデータ記憶装置と、データ要素に対するデータ処理操作を実行することができる処理ロジックとを備えている。デコーダは、データ要素サイズの倍数であるレーンサイズとデータ要素サイズとを識別するデータ処理命令を復号することができる。更に、デコーダは、前記レジスタの少なくとも1つにおいて、並列処理の多数のレーンをレーンサイズに基づいて定義するように処理ロジックを制御することができると共に、処理ロジックは、並列処理の各前記レーン内部のデータ要素に対するデータ処理操作を並列に実行することができる。
(もっと読む)
SIMD処理における定数の生成
【課題】SIMD処理に係るデータ処理装置及び方法を提供する。
【解決手段】データ処理装置(2)は、データ要素を記憶することができるレジスタデータ記憶装置と、生成された定数を伴いそれに引き続き関連付けられたデータ数値を有する命令を復号することができる命令デコーダ(14,16)と、命令デコーダ(16)により復号されたデータ処理命令に応答して並列処理レーン内部で少なくとも1つのソースオペランドに対してデータ処理を実行することができるデータプロセッサ(18)とを備え、データプロセッサは、生成された定数及び関連付けられたデータ数値を伴う復号された命令に応答して関連付けられたデータ数値の少なくともデータ部分(1210)を拡張することができ、拡張は、少なくとも1つのソースオペランドの内の1つを形成する生成された定数(1240)を伴う命令に応答すると共に選択された機能に基づいて定数(1240)を生成するように実行される。
(もっと読む)
プロセッサ及び情報処理システム
【課題】比較的小さな回路規模で且つレジスタファイルの遅延を増大させることなく、SIMD演算の前処理としてのデータ並び替えを実行可能なプロセッサを提供する。
【解決手段】プロセッサは、SIMD演算を実行可能な演算器と、演算器に供給する演算対象のデータを格納するレジスタファイルと、レジスタファイルとは別個に設けられ、各データ列が複数個のデータ要素を含む整数n個のデータ列を列毎に書き込み、n個のデータ列の各々から同一位置のデータ要素を選択してn個のデータ要素として読み出し可能なバッファとを含み、バッファから読み出したn個のデータ要素を演算器にSIMD演算の対象として供給する。
(もっと読む)
演算処理装置、処理ユニット、演算処理システム及び演算処理方法
【課題】複数の処理ユニットによる並列処理において、トランザクション管理を実行しなくても済むようにする。
【解決手段】複数の画像処理ユニット10〜12が、直列にバス接続されてなる。各画像処理ユニット10〜12は、制限時間が設定される制限情報設定部32を有している。各画像処理ユニット10〜12は、CELL24によって複数の画像処理ユニット10〜12間において同一のプログラムに従って演算処理単位ごとのデータに対する演算処理としての画像処理を実行する。各画像処理ユニット10〜12は、制限時間に従って、各演算処理単位ごとのデータに対する画像処理を実行する。各画像処理ユニット10〜12は、画像処理された処理データをメモリ25に格納する。各画像処理ユニット10〜12は、複数の画像処理ユニット10〜12間の入力端子及び出力端子が連結されることにより、相互にバス接続されるようにする。
(もっと読む)
コンパクトな演算処理要素を用いたプロセッシング
プログラマブル及び/又は大規模並列プロセッサーあるいはその他のデバイスのような、プロセッサーまたはその他のデバイスであって、低精度ハイ・ダイナミック・レンジ(LPHDR演算)の数値に対して演算処理(例えば、必須ではないが、加算、乗算、減算、そして除算の内の1つまたはそれ以上を含む処理)を実行するために設計された処理要素を備える。 かかるプロセッサーやその他のデバイスは、例えば、単一のチップ上で実現することができる。 単一のチップ上で実現できるかどうかにかかわらず、本発明のある実施例におけるプロセッサーあるいはその他のデバイスの中にあるLPHDR演算要素の数は、もし
演算要素が存在するならば、演算要素の数をはるかに超える(例えば、少なくとも20+3倍の数だけ超える)ものである。ここでいう演算要素は、プロセッサーやその他のデバイスの中に在って、従来の精度(32ビットあるいは64ビットの浮動小数点演算のような精度)で、ハイ・ダイナミック・レンジの演算を行うように設計された演算要素をいう。
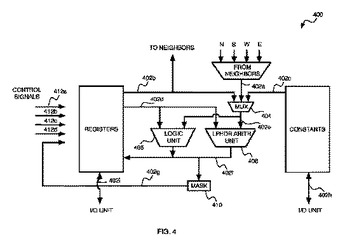 (もっと読む)
(もっと読む)
ヘテロジニアスマルチコアプロセッサ
【課題】プロセッサコアとプロセッサエレメント間におけるデータ授受のためのオーバーヘッドを短縮するとともに、演算能力の向上させる。
【解決手段】プロセッサエレメント13は、各プロセッサコア2−A,2−B,2−Cからキャッシュ禁止に設定され、プロセッサコアおよび入出力インタフェース回路11から直接アクセス可能に設定され、入出力インタフェース回路11からメインメモリ17を介さずに直接転送された入力データおよびプロセッサエレメントの演算結果である出力データを格納するローカルメモリ14と、ローカルメモリ14とメインメモリ17との間でDMA転送するDMAC15とを備え、プロセッサエレメントは出力データをメインメモリ17へDMA転送後に転送完了の割り込みをプロセッサコアに通知し、プロセッサコアはこの通知に基づき次の処理を実行する。
(もっと読む)
プロセッサ及びプロセッサにおける命令発行の制御方法
【課題】並列発行可否判定の必要な命令と不要な命令をプロセッサにおいて効率よく連続的に処理可能とする。
【解決手段】プロセッサ1は、実行ユニット121〜124と、命令ユニット10を含む。命令ユニット10は、命令間の依存関係に基づいた並列発行可否判定を行うべき対象命令であるか否かを、命令ストリームに含まれる命令単位で識別する。そして、命令ユニット10は、命令ストリームに含まれる第1の命令が対象命令である場合に、第1の命令とこれに引き続く少なくとも1つの命令との間での依存関係の検出結果に基づいて、命令ユニット121〜124に並列発行する命令数を調整する。さらに、命令ユニット10は、第1の命令が対象命令でない場合に、第1の命令を含む予め定められた固定数の命令からなる命令グループを、命令グループ内での依存関係の検出結果に拘わらず無条件に実行ユニット121〜124に並列発行する。
(もっと読む)
情報処理装置、演算処理方法及び電子機器
【課題】命令セットのコード効率を向上させる情報処理装置、演算処理方法及び電子機器等を提供する。
【解決手段】情報処理装置が、設定データの読み出し及び書き込み可能に構成される第1及び第2の入力レジスターを有する複数の入力レジスターと、設定データの読み出し及び書き込み可能に構成される被加算値レジスターと、前記第1及び第2の入力レジスターの設定データの加算処理を行う第1の加算ユニットと、前記第1の加算ユニットと並列動作可能に構成され、前記第1及び前記第2の入力レジスターの設定データを連結した連結データと、前記被加算値レジスターの設定データとの加算処理を行う第2の加算ユニットと、前記第1及び第2の加算ユニットのいずれかの処理結果が格納される複数の出力レジスターとを含む。
(もっと読む)
情報処理装置および情報処理プログラム
【課題】動的再構成可能な演算手段によって複数の情報処理を行うにあたり、再構成時間の短い粗粒度の再構成可能回路は、帰還回路のレイテンシが大きいため性能低下が発生する。このため、時間を考慮した回路構成を行うこと。
【解決手段】本発明は、動的に回路が再構成される第1演算部を複数備える第1回路構成部10と、固定の回路から成る第2演算部を複数備える第2回路構成部20と、情報を処理するにあたり、第1回路構成部10ではレイテンシによる性能低下が発生する回路において、第2回路構成部20で補間する回路構成を制御する回路構成制御部30とを有する情報処理装置である。
(もっと読む)
マイクロプロセッサ
【課題】面積オーバヘッドや消費電力を低く抑えたマイクロプロセッサを提供する。
【解決手段】本発明は、データ配列単位での順次処理が可能なマイクロプロセッサであって、フェッチされた命令がデータのロード命令である場合に、指定されたデータを含んだデータ列をメモリ幅単位でデータメモリ16からロードし、また、命令の解析結果に基づいて、ロードしたデータ列のうち、次回のロード命令で指定される予定のデータを特定するロードストアユニット14と、ロードストアユニット14により特定されたデータを記憶するデータ一時記憶部17と、を備える。
(もっと読む)
情報処理装置、演算処理方法及び電子機器
【課題】命令セットのコード効率を向上させる情報処理装置、演算処理方法及び電子機器等を提供する。
【解決手段】情報処理装置10は、並列動作可能に構成された第1及び第2の演算処理ユニットEXU1、EXU2と、各入力レジスターの設定データが読み出し及び書き込み可能に構成される複数の入力レジスターと、第1及び第2の演算処理ユニットEXU1、EXU2の処理結果が格納される複数の出力レジスターとを含む。複数の入力レジスターは、第1の演算処理ユニットEXU1に割り当てられる第1の入力レジスターと、第2の演算処理ユニットEXU2に割り当てられる第2の入力レジスターとを有し、複数の出力レジスターは、第1の演算処理ユニットEXU1に割り当てられる第1の出力レジスターと、第2の演算処理ユニットEXU2に割り当てられる第2の出力レジスターとを有する。
(もっと読む)
大命令幅プロセッサにおける処理効率の向上
1つ以上の処理ユニット(40)と、実行パイプライン(32)と、制御回路(28)とからなるプロセッサ(20)。実行パイプラインは、少なくとも段階を成す第1と第2のパイプラインステージを有し、パイプラインの連続するサイクルの中で処理ユニットにより遂行される動作を特定するプログラム命令が、第1のパイプラインステージによりメモリから取得され、そして前記第2のパイプラインステージに運ばれ、第2のパイプラインステージは処理ユニットに対し特定の動作を遂行するようにさせる。制御回路は、パイプラインの第1のサイクルにおいて第2のパイプラインステージ内に存在するプログラム命令が、パイプラインの次のサイクルにおいて再び実行されると判定した時に、前記実行パイプラインに対し、前記メモリから前記プログラム命令を再取得することなく、前記パイプラインステージの1つの中の前記プログラム命令を再使用させるように接続される。 (もっと読む)
ハードウェアフィールドにロッシーなメタデータを保持するためのメタフィジカルアドレス空間
ロッシーなメタデータを保持するためもメタフィジカルアドレス空間のための方法及び装置について記載する。データ項目のデータアドレスを参照する明示的又は非明示的メタデータアクセスオペレーションが発生する。ハードウェアは、データアドレスを、メタフィジカル拡張を含むメタデータアドレスに修正する。メタフィジカル拡張は、1以上のメタフィジカルアドレス空間を、メータアドレス空間に、重複させる。メタフィジカル拡張を含むメタデータアドレスの一部は、データ項目を保持するキャッシュメモリのタグアレイを検索するのに使用される。その結果、メタデータアクセスオペレーションは、メタデータアドレス拡張に基づいて、キャッシュのメタデータエントリのみをヒットする。メタデータは、キャッシュ内に保持されることから、メタデータは、データと、キャッシュ内のスペースについて競合する場合がある。 (もっと読む)
命令ブロック・シーケンサ・ロジックを有するマルチ実行ユニットによる命令実行のための回路構成、集積回路デバイス、プログラム、及び方法
【課題】マルチ実行ユニット・プロセッサにおけるフィルタリング処理のような長レイテンシ処理の性能を改善する。
【解決手段】処理ユニットは、複数の実行ユニットと、命令バッファ・ロジックの下流に配設され、命令ストリーム内に所在するシーケンサ命令に応答するシーケンサ・ロジックと、を含む。シーケンサ・ロジックは、長レイテンシ処理に関連する複数の命令を1つの実行ユニットに対して発行するとともに、命令バッファ・ロジックからの命令が当該実行ユニットに対して発行されるのをブロックする。また、実行ユニットに対する命令の発行をこのようにブロックしても他の実行ユニットに対する命令の発行には影響が及ばず、したがって、シーケンサ・ロジックが長レイテンシ処理に関連する複数の命令を発行している間もなお、命令バッファ・ロジックからの他の命令を他の実行ユニットに発行し、それらの実行ユニットによって実行することが可能である。
(もっと読む)
21 - 40 / 135
[ Back to top ]