
Fターム[5B013DD01]の内容
Fターム[5B013DD01]に分類される特許
81 - 100 / 135
並列演算装置

【課題】単一命令・多重データ型演算装置において、多重命令・多重データ演算を高速かつ柔軟に実行する。
【解決手段】エントリそれぞれに対応して設けられるALUユニット(34)において、MIMD用命令に従って制御信号群を生成するMIMD用命令デコーダ(74)と、このMIMD命令を指定するデータを格納するMIMD用レジスタ(72)を設けるとともに、ALU間通信回路(71)を設ける。ALU間通信回路の移動量および移動方向を、移動データレジスタ(70)に格納されるデータビット(E0−E3)で設定する。ALUユニットごとに移動量および演算命令を設定してデータ移動および演算を実行することができる。
(もっと読む)
マルチスレッドプロセッサ

【課題】 プログラムの種類に係わらず並列実行及びシリアル実行を適応的に行い、並列度を高めても細粒度の並列実行を高効率で行うマルチスレッドプロセッサを実現する。
【解決手段】 スレッドユニット2a〜2hは、生成する実行命令に、演算ユニット5a〜5d中の任意の演算ユニットで実行される演算が他の演算ユニットで演算した演算結果を用いる依存性演算が含まれる場合は、被依存性実行命令を生成するスレッドユニットを特定してセマフォ情報を記憶領域21に記述する一方、生成する実行命令に被依存性実行命令が含まれる場合は、プログラム実行後にセマフォ情報をクリアさせる実行命令を付した実行命令を生成するプログラム生成部23と、セマフォ情報がクリアされた後に依存性演算の実行命令を、命令クロスバースイッチ4を介し演算ユニットに供給させる命令投入部24を備えて実現した。
(もっと読む)
VLIW型プロセッサおよび命令発行方法
【課題】簡単な構成でnop命令数を削減できるVLIW型プロセッサを提供する。
【解決手段】命令ディスパッチャ12とALU15の間にディレイ発生部13を設け、命令ディスパッチャ12とストアユニット17の間にディレイ発生部14を設ける。ディレイ発生部13は、命令ディスパッチャ12からALU15に向けて送出された小命令の、ALU15への供給タイミングを調整する。ディレイ発生部14は、命令ディスパッチャ12からストアユニット17に向けて送出された小命令の、ストアユニット17への供給タイミングを調整する。
(もっと読む)
データ処理装置及びプログラム実行方式
【課題】複数種のSIMD構成に対応し、かつ、プログラムの開発期間を短縮可能なデータ処理装置を得る。
【解決手段】プログラム制御部4Aはデコード段階において、低並列実行モード時に、デコード結果が並列度が“4”の高並列命令の場合は、プログラムカウンタPCをインクリメントすることなく、高並列命令の直後のサイクルでNOP命令を指示する命令コードOPを出力する。演算器選択信号出力部23は低並列実行モード時に、高並列命令を指示する場合は、当該高並列命令を、並列度が“2”で処理可能な第1及び第2の部分並列命令を分割し、次のサイクルから2サイクルかけて第1及び第2の部分並列命令を指示する演算命令選択信号OPSを並列演算器3に出力する。
(もっと読む)
ベクトルリネーミング方式およびベクトル型計算機
【課題】単純なハードウェアを用い、ベクトル型計算機においてマスク演算動作とレジスタリネーミングを同時に実現する。
【解決手段】相互にセットをなすとともに論理ベクトルレジスタに対応する複数のリネーミングレジスタを設ける。各リネーミングレジスタは、それぞれ1ビットのデータを保持するセルC0,C1と、セルC0,C1ごとに設けられたセレクタS0,S1とを有する。セレクタS0,S1は、ライトデータWDかセット内の相手側のセルC1,C2が保持する値かをマスク信号MASKに応じて対応するセルC0,C1に供給する。この構成により、マスクが設定されている場合にはセル間でセルの値がコピーされ、マスクが設定されていないときにはライトデータWDがいずれかのセルに書き込まれるようにする。
(もっと読む)
プロセッサ
【課題】性能の大幅な劣化を招くことなく、動的命令スケジューリング機構の構成をより簡易な構成とし、以て、消費電力をより低減させることが可能なプロセッサを提案する。
【解決手段】依存情報を用いた命令グループ化による手法を採用する。 マスターキュー(120)とスレーブキュー(122)を備えたプロセッサにおいて、マスターキュー内の命令が選択され、発行のためにアクセスされる際、スレーブキューに命令が格納されていることを示すフラグ(124)が立っていた場合、ラッチ(126)を介して次のサイクルでスレーブキュー内の命令が発行される。ウェイクアップ時に連想マッチを行うためのCAMはマスターキュー側にのみ備えられている。
(もっと読む)
マルチスレッド計算機システム、マルチスレッド実行制御方法
【課題】複数のプロセッサエレメント(PE)における実質的な稼働率を向上させるマルチスレッド計算機システムを提供する。
【解決手段】本発明のマルチスレッド計算機システムは、複数のPE101〜103と、各PEのスレッドを切り換える並列プロセッサ制御部200とを備え、並列プロセッサ制御部200は、PE毎に実行すべきスレッドの実行順序を保持する複数の実行順序レジスタと、各PEにより実行中のスレッドの実行時間をカウントトし、カウントされた時間がスレッドの割り当て時間に達したときタイムアウト信号を発生する複数のカウンタ230と、前記実行順序レジスタに保持された実行順序および前記タイムアウト信号に基づいて、各プロセッサエレメントで実行すべきスレッドを切り換えるスレッド実行スケジューラ部210とを備える。
(もっと読む)
多機能マイクロコントローラーシステム、そのコマンド、及びコマンド実行方法
【課題】平行させて処理を高速化させることができる多機能マイクロコントローラーシステム、それに用いられるコマンド、及びコマンド実行方法を提供する。
【解決手段】簡単で明確なエンコーダー方法によりコマンド内にある多機能マイクロコントローラーのコアロジック選択オペランドを書き出し、且つ、前記多機能マイクロコントローラーシステム内の任意或いは特定のマイクロコントローラーのコアロジックをメイン演算コントローラーユニットとし、前記コマンドに対し読み出し、デコードの動作を行い、さらに、前記多機能マイクロコントローラーのコアロジック選択オペランドに基づいて指定されているマイクロコントローラーのコアロジック及びそのサブオペランドの情報を探し出すことにより、オペレーションコードの演算動作を実行する。
(もっと読む)
汎用アレイ処理
処理方法および装置を含む汎用アレイ処理技術。プロセッサは、乗算器、マルチプレクサおよびALUなどの再使用可能な計算コンポーネントによって設計されている並列処理経路を含むことがある。該経路を介するデータの流れおよび実行される演算はオペコードに基づいてコントロール可能である。プロセッサは共有され、スケーラブルであり、かつ行列演算を実行するように構成されてもよい。とりわけ、このような演算は、MIMO−OFDM通信システムの物理セクションに有用である。  (もっと読む)
(もっと読む)
VLIWプロセッサのための分岐および行動分割
ある側面では、本発明は、合成可能タスクのシミュレーションを加速する多くの並列プロセッサ要素を有するVLIWシミュレーションプロセッサを使用するだけでなく、また、合成不可能タスクおよび/または分岐もサポートする論理シミュレーションシステムを提供することによって、従来技術の制限を克服する。あるアプローチでは、VLIWシミュレーションプロセッサは、オンチップ命令キャッシュを有さないアーキテクチャに基づく。代わりに、VLIW命令ワードは、プログラムメモリから直接ストリームし、個々のプロセッサ要素は、命令ワードに基づいて、連続的にプログラムされる。これは、また、割り込みジャンプの効率的実装を可能にし、コード領域は、常に最初からの侵入を必要とせず、領域の中間に侵入可能である。別の側面では、合成不可能タスクは、例外ハンドラによって効率的に処理可能である。  (もっと読む)
(もっと読む)
プロセッサ、コンパイル装置及びコンパイルプログラムを記録している記録媒体
【課題】複数の命令を1のサイクルにおいて実行するプロセッサにおいて、並列処理を行う場合に、実行サイクル数を削減することができるプロセッサ及びコンパイル装置を提供する。
【解決手段】レジスタR0〜R31は、それぞれ上位32ビットの領域と下位32ビットの領域に分かれている。レジスタ書込制御部431は、1のサイクルで発行された各命令における書き込むレジスタと書き込み位置(上位又は下位のいずれか)を示す情報をセレクタ4321、4322へ出力する。セレクタ4321、4322は、それぞれ、第1演算部44、第2演算部45又は第3演算部46から出力される各データのうちいずれか1のデータを選択し、選択したデータをいずれか1のレジスタの上位及び下位へそれぞれ書き込む。
(もっと読む)
非同期電力節約コンピュータ
コンピュータアレイ(10)が、複数のコンピュータ(12)を有する。コンピュータ(12)は、互いと非同期に通信し、コンピュータ(12)自体は、内部的に全般的に非同期の形で動作する。あるコンピュータ(12)は、別のコンピュータとの通信を試みるときに、他方のコンピュータ(12)がそのトランザクションを完了する準備ができるまで眠り、これによって、電力を節約し、熱発生量を減らす。コンピュータのそれぞれ内のスロットシーケンサ(42)が、タイミングパルスを作って、コンピュータ(12)に次の命令を実行させる。しかし、現在の命令が、読取タイプ命令または書込タイプ命令であるときに、スロットシーケンサは、肯定応答信号(86)がそのスロットシーケンサを始動するまで、パルスを作らない。肯定応答信号(86)は、通信が他方のコンピュータによって完了されたことが認められるときに作られる。  (もっと読む)
(もっと読む)
コンピュータのアレイ間でのリソースの割り当て
コンピュータアレイ(10)は、複数のコンピュータ(12)を有する。コンピュータ(12)は、隣接するコンピュータと直接通信し、アレイ内の他のコンピュータと間接的に通信する。コンピュータは、データおよび/または命令を含むデータ語を渡す。4つもの命令を、18ビットのデータ語1つに含むことができる。4つの命令は一度に伝達されるため、4つもの命令で構成されるマイクロループ全体を通信することができる。本発明のコンピュータは、その入力レジスタから直接命令を実行できる。  (もっと読む)
(もっと読む)
データ・キャッシュ・ミス予測およびスケジューリング
【課題】Dキャッシュ・ミス予測およびスケジューリングのための方法および装置を提供すること。
【解決手段】一実施形態では、プロセッサでの命令の実行がスケジューリングされる。プロセッサは、共通発行グループ内の命令を互いに対して遅延式に実行する2つ以上の実行パイプラインを有する少なくとも1つのカスケード式遅延実行パイプライン・ユニットを有することができる。この方法は、命令の発行グループを受け取ること、発行グループ内の第1命令が第1命令の以前の実行中にキャッシュ・ミスとなったかどうかを判定すること、および、そうである場合、カスケード式遅延実行パイプライン・ユニット内の別のパイプラインに対して実行が遅延されるパイプラインで実行するように第1命令をスケジューリングすることを含む。
(もっと読む)
処理装置
【課題】 所期の回路の高速なマッピングを実現することが可能なリコンフィギュラブル回路を備えた処理装置を提供する。
【解決手段】 サイクル毎に、異なる回路の分割回路をリコンフィギュラブル回路12の各段に順番に処理の流れに従ってそれぞれ割りつける。本方式の如く、リコンフィギュラブル回路12の各段で、それぞれ別の回路をマッピングし、複数の演算処理を並列して実行することにより、高速なマッピングに伴う高速な所期の回路の構成すなわち高速な論理動作を実現することができる。
(もっと読む)
暗号化装置及び暗号化方法及び復号装置及び復号方法及びプログラムを記録したコンピュータ読み取り可能な記録媒体
【課題】暗号化の最中に他のデータの暗号化を行うために、暗号鍵Kを用いた暗号化モジュール51からセレクタ54にフィードバックするフィードバックライン65に対して並列に設けられたメモリ55を配置する。
【解決手段】平文ブロックデータMi を処理中に他のデータの平文ブロックデータNi を処理する割り込みITが発生した場合には、割り込みITが発生したときの暗号文ブロックデータCiをレジスタ56に記憶させ、平文ブロックデータNi の処理が終了した時点でメモリ55に記憶した暗号文ブロックデータCiをセレクタ54に選択させることにより平文ブロックデータMi+1 の処理を開始する。
(もっと読む)
並列プロセッサ
【課題】 拡張命令によって複数のプロセッサを並列動作させることができる並列プロセッサの命令メモリの利用効率の向上を図る。
【解決手段】 分岐命令で動作モードと命令長を指定するようにして、この動作モード情報と命令長情報に基づき命令フェッチ・命令データ供給ユニット500を制御することで、コアプロセッサ200の動作時において、動作させないコプロセッサ#1(300)および又は#2(400)に無操作(NOP)命令を命令メモリ100に埋め込むことを不要とするとともに、プロセッサ1の並列動作モード時にも、並列動作させないコプロセッサ#1(300)および又は#2(400)に対するNOP命令の命令メモリ100への埋め込みを不要とし、更に拡張命令で処理に必要な範囲のコプロセッサ#1(300)および又は#2(400)の並列動作を指定可能な命令長の命令を選択出来るようにすることで命令メモリ100の利用効率を向上させる。
(もっと読む)
SIMDアーキテクチャ内でスレッドグループを処理するためのシステムおよび方法
【課題】そのハードウェアリソースを効率的に用いてより高いデータ処理スループットを達成するSMIDプロセッサを提供すること。
【解決手段】SIMDプロセッサの有効幅は、データ処理側の速度の何分の1かの速度でSIMD処理装置の命令処理側をクロッキングし、各々が複数のデータ経路を有する複数の実行パイプラインを提供することにより、拡張される。そのため、より高いデータ処理スループットが達成されると同時に、命令はフェッチされ、クロックごとに一度発行される。この構成はまた、1つの大きなスレッドグループがSIMDプロセッサを介してクラスタされ、一緒に実行されることも可能にし、その結果、グラフィックス処理に関して実行されるテクスチャメモリアクセスのようなあるタイプの動作に関してより大きなメモリ効率が達成されることが可能である。
(もっと読む)
高可用性モードを有するハードウェア設定可能CPU
【課題】高可用性モードを有するハードウェア設定可能CPUを提供する。
【解決手段】マイクロプロセッサ16はモードレジスタ38を含み、モードレジスタ38は、それに値を設定することにより、マイクロプロセッサ16内のフォールトトレランス機能を選択的にオン及びオフにするために使用される。モードレジスタ38によって、マイクロプロセッサ16は、プログラムがフォールトトレランスを必要とする場合はフォールトトレラントモードで動作し、プログラムがフォールトトレランスを必要としない場合はパフォーマンスモードで動作することができる。その結果、マイクロプロセッサ16は、コンピュータシステムを不必要に低速化することなくコンピュータシステムのフォールトトレランスを向上させることができる。
(もっと読む)
VLIWアーキテクチャを有する他のDSPのための高速DCTアルゴリズム
離散コサイン変換オペレーションを実行する単一ステージの計算方法が、提供される。離散コサイン変換オペレーションは、デジタル信号プロセッサを使用して複数の超長命令語(VLIW)を実行することにより、実行される。複数の超長命令語は、第1の数の乗算と第2の数の加算とを含んでおり、ここで乗算の第1の数は、加算の第2の数よりも大きい。 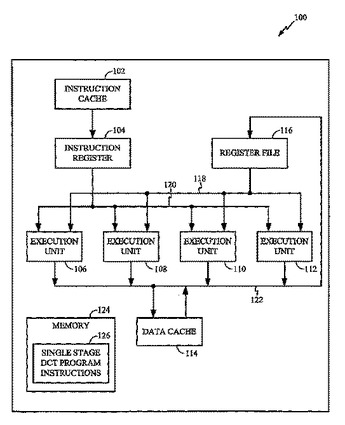 (もっと読む)
(もっと読む)
81 - 100 / 135
[ Back to top ]