
Fターム[5B042JJ14]の内容
デバッグ、監視 (27,428) | 動作監視、異常又は誤りの検出 (3,508) | 監視内容 (773) | デッドロックの検出 (26)
Fターム[5B042JJ14]に分類される特許
1 - 20 / 26
異常情報保持システム
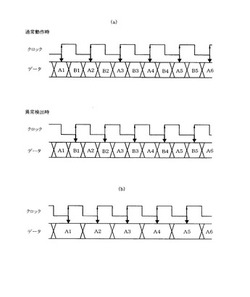
【課題】異常原因などを解析するための情報を的確に取得できるようにした異常情報保持システムを提供する。
【解決手段】通電切替器は、CPUが通常動作しているときには表示装置が表示画像データA1、A2、A3…に同期して受信するように切替えるものの、CPUの異常が検出されたときには表示装置が異常解析データB1、B2、B3…に同期して受信するように切替える。表示装置2はこの異常解析データBを受信し画素に記憶保持する。
(もっと読む)
多重化サービスプロセッサ、多重化サービスプロセッサの障害処理方法、およびプログラム

【課題】 現用系サービスプロセッサに異常がなく、両系間の経路上の障害が発生したときに、予備系サービスプロセッサへの切り替えを誤って行ってしまうことを防止する。
【解決手段】 多重化サービスプロセッサにおいて、サービスプロセッサ間で時刻を同期させる時刻同期処理部と、プロセッサ間通信を監視するプロセッサ間監視処理部と、同期した時刻をトリガにして、ユニット内の共有格納領域への診断データの書き込み処理、共有格納領域からの読み出し処理、およびプロセッサ間通信の監視処理の一連の自己診断処理を自律的に順次実行し、待機系のサービスプロセッサへの切り替え処理を行う診断処理部と、を備える。
(もっと読む)
情報処理装置、その制御方法、及びコンピュータプログラム
【課題】サブシステムで発生した障害を正確に検出できるようにする。
【解決手段】
本発明の情報処理装置は、第1のサブシステム及び第2のサブシステムを備え、第1のサブシステムは、第1のサブシステムが実行する所定の処理タスクよりも高い優先度で第1のカウンタを更新し、前記所定の処理タスクよりも低い優先度で第2のカウンタを更新する。また、第2のサブシステムは、第1のカウンタ及び前記第2のカウンタが更新されたか否かを確認し、第1のカウンタ及び第2のカウンタの少なくともいずれかが更新されていない場合に、第1のサブシステムにおいて障害が発生したと判定する。
(もっと読む)
データ処理装置の監視およびその監視データの集計
【課題】開始と終了イベントとの間に生じるデータ処理装置内の複数のアドレス指定可能場所へのアクセスを監視するための監視回路を提供する。
【解決手段】前記監視回路は、監視される前記複数のアドレス指定可能場所を識別するデータを保存するためのアドレス場所保存と、監視データ保存とを含み、前記監視回路は、前記開始イベントの検出に応答して、前記複数のアドレス指定可能場所へのアクセスを検出し、前記監視データ保存内に前記検出されたアクセスの集計に関連する監視データを保存し、前記監視回路は、前記終了イベントの検出に応答して、前記監視データの収集を停止し、前記監視回路は、消去イベントの検出に応答して、前記保存された監視データを出力し、前記監視データ保存を消去する、データ処理装置が開示される。
(もっと読む)
サービスフロー処理装置及びサービスフロー処理方法
【課題】 外部サービスの状態に応じて、該外部サービスを実行するか、装置内に生成した内部サービスを実行するを切り替える。
【解決手段】 サービスフロー記述文書に記述されたフロー処理を実行するサービスフロー処理装置において、外部サービスに関する情報を受信する。外部サービスにアクセスし、該外部サービスから応答が得られない場合、外部サービスに関する情報から外部サービス用のサービスインターフェース記述文書を取得し、サービスインターフェース記述文書に記述された外部サービスのエンドポイントを記憶する。そのエンドポイントをサービスフロー処理装置の内部に生成された内部サービスのエンドポイントに変換し、変換されたサービスインターフェース記述文書に基づいて、内部サービスを実行する。
(もっと読む)
アプリケーションの応答不能時を推定するシステム、方法、およびプログラム
【課題】応答不能が発生した際の実行環境毎に、応答不能が発生する閾値を統計学的に求めることにより、適切な閾値を用いて応答不能時を推定することができるアプリケーションの応答不能時を推定するシステム、方法、およびプログラムを提供すること。
【解決手段】アプリケーションにおいて受け付けたユーザからの少なくともキーストローク数を含む操作イベント数をカウントする操作イベントカウント手段202と、アプリケーション応答不能状態の発生を検知した際に、割り込み処理によりアプリケーション起動時からの操作イベント数およびアプリケーションの実行環境情報を、応答不能ログ情報としてアプリケーションと関連付けて記憶する応答不能ログ情報DB130と、応答不能ログ情報DB130に記憶された情報に基づいて、応答不能となる推定操作イベント数を推定する応答不能推定手段110と、を備える。
(もっと読む)
計算機システム及びプログラム
【課題】ノードにおけるデッドロックの発生をイベントドリブンで検出し、障害発生から障害検出までの時間を短縮及び検出可能な障害範囲を拡大することを可能とする。
【解決手段】クラスタシステムは、資源を共有する複数のスレッドを実行するノード10を備える。ノード10は、APIフック部131、ロック状態テーブル133及びデッドロック検出部134を含む。APIフック部131は、複数のスレッドの各々からの、資源を占有するためのロックの取得を要求するロック取得要求をフックする。ロック状態テーブル133には、APIフック部131によってフックされたロック取得要求に基づいて、複数のスレッドによるロックの取得状態が登録される。デッドロック検出部134は、APIフック部131によってフックされたロック取得要求及びロック状態テーブル133に登録されているロックの取得状態に基づいて、デッドロックの発生を検出する。
(もっと読む)
情報機器管理方法
【課題】ユーザインタフェイスをもった情報機器において、待ち状態とフリーズ状態の判断を支援。
【解決手段】管理対象の情報機器ユーザの要求を受け、ユーザの通常操作が不能な状態が待ち状態かフリーズ状態の判断支援を行う。機器管理サーバにおいて、その状態に至るイベントシーケンス情報を検索条件とし過去の結果履歴より無応答状態からの復帰時間およびフリーズの可能性を予測し、この結果を通知することでユーザストレスを軽減する。また、結果履歴を解析しフリーズ状態を起こした可能性のあるイベントシーケンスについて、機器管理サーバの管理対象の情報機器に対し、より精緻な情報収集要求ブロードキャストし、多数の情報機器に分散して効率よく情報の収集を行い、フリーズ状態の解決につなげる。
(もっと読む)
システム診断装置、方法およびプログラム
【課題】 大規模ソフトウェアにおける、コンポーネントの状態遷移の不整合によるデッドロックを効率良く検出すること。特に実用可能な計算量で、メッセージ通信のイベント待ちに起因するデッドロックを検出することが可能な診断装置を提供すること。
【解決手段】 コンポーネント間のメッセージ送受信に関わる記述を用いて各コンポーネントの抽象化済状態遷移モデルを作成し、該抽象化済状態遷移モデルを結合し、メッセージログを用いてさらに検出範囲を限定したシステム状態遷移モデルを作成する。該システム状態遷移モデルに対してデッドロック検出を行う。
(もっと読む)
情報処理システム、情報処理方法、および情報処理プログラム
【課題】ソフトウェアの検査において、検査したい部分とそうでない部分との間でメッセージ送受信がある場合、必要となる外部環境を自動的に生成することでソフトウェアの検査を効果的に支援する情報処理システムを提供する。
【解決手段】外部環境生成手段110により、検査対象のソフトウェアの記述を元に検査対象の状態遷移を網羅するような外部環境を自動的に生成し、メッセージの送受信の動作に必要な通信相手を提供する。また、外部環境編集手段130により、自動的に生成された外部環境を雛形として利用者が外部環境を記述することを可能とする。
(もっと読む)
監視システム、監視サーバ、監視プログラム、および監視方法
【課題】 プロセスのストール検出の確実性を向上させる。
【解決手段】 本発明の一実施形態の監視サーバは、プロセスの処理を待ち合わせるトランザクションの停止通知を受信すると、前記プロセスに通信要求をして前記プロセスのストールを検知する監視APを備える。
(もっと読む)
ソフトウェアのシミュレーション方法、ソフトウェアのシミュレーションのためのプログラム、及びソフトウェアのシミュレーション装置
【課題】本発明は、LSIのソフトウェアモデル上でプログラムの実行をシミュレートする際に、プログラムにデバッグ用の細工をすることなく、データレース及びデッドロック等を抽出可能なシミュレーション方法を提供することを目的とする。
【解決手段】コンピュータによるソフトウェアのシミュレーション方法は、ソフトウェアによるシミュレータ上にソフトウェアとして実現したハードウェアのモデルにより複数のスレッドからなるプログラムを実行し、シミュレータのモニタ機能によりハードウェアのモデル内のリソースに対する複数のスレッドによるアクセスをモニタしてアクセスに関する情報を収集し、モニタ機能により、収集された情報から複数のスレッドによる同一のリソース領域に対する重複するアクセスを抽出し、モニタ機能により、重複するアクセスを警告するメッセージを生成する各段階を含むことを特徴とする。
(もっと読む)
並列計算機システム、並列計算方法および並列計算機用プログラム
【課題】進化的アルゴリズムを用いた設計最適化などのように1度の計算に長時間を要する環境において、並列計算機を用いた計算の際に生じるトラブルを自動的に検知し、それらのトラブルに自動的に対処することが可能な並列計算機を提供する。
【解決手段】本発明は、計算プログラムを実行する複数の計算ノードと、計算ノードにネットワークを介して接続されるマスターノードとを含み、進化的アルゴリズムを用いた設計最適化などのように1度の計算に長時間を要する環境において並列計算処理を行なうための並列計算機システムを提供する。このシステムは、計算プログラムのクラッシュまたはハングアップを定期的または処理単位ごとに監視し、異常が検知された計算ノードにおける計算プログラムの実行を中止し、この計算プログラムを他の計算ノードに実行させる一連の処理を自動的におこなう異常処理手段を有する。
(もっと読む)
プロセッサーシステム及び通信装置
【課題】マスタープロセッサーがスレーブプロセッサーの状態を知ることが可能なプロセッサーシステム及び通信装置を提供すること。
【解決手段】本発明にかかる通信装置は、スレーブプロセッサー11、積分回路12及びマスタープロセッサー13を備えた、いわゆるマスター/スレーブ構成の通信装置である。まず、スレーブプロセッサー11は、タスク起動状態信号を積分回路12に対して送信する。積分回路12は、受信したタスク起動状態信号を積分により変換し、これを積分結果信号としてマスタープロセッサー13に送信する。そして、マスタープロセッサー13が、この積分結果信号を受信し、タスク起動状態を判断する。
(もっと読む)
分散制御装置
【課題】システムの一部に局所的な異常が発生した場合に、その影響がシステム全体に及ばないよう適切な復旧処理を実行させる分散制御装置を提供すること。
【解決手段】電子制御装置1の分散制御装置11は、電子制御装置1の所定の機能を実現するために電子制御装置1、2に分散配置されたタスク100、200、101を所定の順序で実行させるタスク実行順序制御手段110と、電子制御装置1以外の装置である電子制御装置2にあり、タスク実行順序制御手段110により実行が指示されたタスクB200の処理時間を監視しタスクB200がデッドラインオーバーとなったか否かを判定するデッドラインオーバー判定手段111と、タスクB200がデッドラインオーバーになったと判定された場合、所定の復旧処理を実行させる復旧処理実行手段112と、を備えることを特徴とする。
(もっと読む)
アプリケーションの異常監視方法
【課題】WDT機能をもたないコンピュータシステムにおけるアプリケーションの異常監視を確実、容易にする。
【解決手段】コンピュータシステムは、アプリケーションのうち、異常監視対象とする複数のアプリケーション11〜1Nに対応つけた複数のカウンタ21〜2Nと、この各カウンタのカウント値を読み書き可能な監視タスク3を設ける。
各アプリケーションは、その正常処理中に一定周期または予め設定された処理の終了で対応つけられたカウンタをインクリメントする。監視タスクは、各カウンタのカウント値を一定周期で読み取り、各カウント値の全てが定義された範囲内にあるときに各カウンタの全てを「0」にセットし、各カウント値の1つでも範囲外にあるときにアプリケーションの異常警報あるいはシステムリセットを行う。
(もっと読む)
分散型プログラムのトレース装置
【課題】CORBA等を使用した複数ノードに跨る分散型プログラムにおいて、他のノードを経由して同一処理上で同一ロックを捕捉しようとした場合に発生するデッドロックを検出する。
【解決手段】トレース実行中に各ノード上でロックを捕捉する処理の起動元ノード名と、起動元スレッド番号とを含むロックに関する実行状態を書き込むためのロック情報格納領域と、各ノード上でロックに関する実行状態を周期的に監視し、デッドロックが発生したことを検出する手段とを備える分散型プログラムのトレース装置。ロック情報を保存する際に起動元ノード名と起動元スレッド番号とを設定することにより、複数ノードに跨る分散型のプログラムであっても、同一処理上で同一ロックを捕捉しようとしていることが検出することができるため、デッドロックを検出することができる。
(もっと読む)
電子制御装置および電子制御方法
【課題】ノイズ等の一過性のCPU異常現象があっても安定したCPU動作を継続可能な電子制御装置および電子制御方法を提供する。
【解決手段】システム全体の動作を制御するCPU20からあらかじめ定めた周期とデューティのパルスとして定期的に出力される動作信号が、許容範囲としてあらかじめ定めた規定閾値の範囲内にあるか否かにより、前記CPUが正常であるかあるいは異常が発生しているかをCPU監視手段となるウォッチドッグ回路1にて判定し、異常が発生していると判定された場合に、ウォッチドッグ回路1から出力される異常信号の発生回数をカウンタ2にてカウントし、カウント値が、あらかじめ定めた異常検出閾値に達した場合に、CPU20をリセットするリセット信号を出力する。また、カウント値が前記異常検出閾値に達した場合、カウンタ2をラッチして、CPU20に対するリセット信号の出力を継続させ、CPU20の動作を停止させる。
(もっと読む)
ワイヤレスデバイスに適用するシステムフリーズ診断と復旧手法
【課題】ワイヤレスデバイスにおいて、デッドロックの回避を図り、デッドロックの回避ができない場合には、発生したデッドロックを検出してシステムの復旧を行ってシステム全体のフリーズを回避する。
【解決手段】ワイヤレスデバイスに診断エンジンを常駐して、常にプロセスの動作状態とシステムリソースの利用状態を観察し、プロセスが起動するときとシステムリソースを要求するときにデッドロックの回避を図り、プロセス間にデッドロックが起きたときに直ちに診断してデットロックの場所(プロセス)と原因を特定して、即時に直せるのであれば、対応処置を取り、システムを復旧する。ソフトウェア上のバグであれば、詳細な診断データを記録した診断報告書を診断サーバに送る。
(もっと読む)
デバッグシステム、デバッグ方法およびプログラム
【課題】複数の実行ユニットが連携して動作するシステムにおいて、任意の実行ユニット上に任意のタイミングでデバッグ用プログラムを起動して、デバッグ作業を行うことを可能にする。
【解決手段】デバッグ用プログラム起動指示振り分け手段61、71は、通信ポート1より送られてくるデバッグ用プログラムの起動指示を受信すると、この起動指示により指定されている実行ユニットに対して受信したデバッグ用プログラムを振り分ける。デバッグ用プログラム起動手段62、72は、実行ユニットA、B毎に設けられ、起動指示振り分け手段61、71により振り分けられた起動指示に基づいて、指定された実行ユニット上にデバッグ用プログラム63、73を起動する。
(もっと読む)
1 - 20 / 26
[ Back to top ]