
Fターム[5B064DA23]の内容
Fターム[5B064DA23]の下位に属するFターム
リジェクトした文字パターンを用いるもの (11)
記入見本を用いるもの (3)
基本パターンを変形する (11)
学習によるもの (63)
Fターム[5B064DA23]に分類される特許
1 - 20 / 39
パターン選択装置、パターン選択方法、およびプログラム
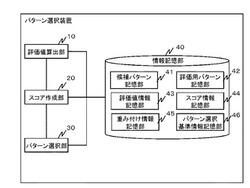
【課題】候補パターンの偏りを防ぎ、効率的でバランスの良い候補パターンの選択を可能とする
【解決方法】本実施形態のパターン選択装置は、第1のパターン群と第1のパターンの評価に用いられる第2のパターン群とを格納した記憶部と、第2のパターンを参照して、第1のパターンの複数の評価値として、第1のパターンが第2のパターンをパターン認識する際の貢献度である第1の評価値と、第1のパターンが、第1のパターンが所属するクラスにおける標準的なパターンであるかを評価する第2の評価値、および第1のパターンがクラスの境界付近のパターンであるかを評価する第3の評価値を算出する評価値算出部と、算出された評価値と評価値ごとの重み付け情報とを用いて、第1のパターンごとのスコアを算出するスコア算出部と、算出されたスコアに基づいて第1のパターンからパターンを選択するパターン選択部と、を備える。
(もっと読む)
画像処理装置及び画像処理プログラム

【課題】画素塊に関する情報を画像内の画素塊の画像に付与する場合にあって、その付与する情報はその画像内の画素塊の画像よりも高解像度である画素塊に関する情報とするようにした画像処理装置を提供する。
【解決手段】画像処理装置の情報生成手段は、複数の画素塊の画像と該画素塊の画像よりも高解像度である該画素塊に関する情報を生成し、記憶手段は、前記情報生成手段によって生成された画素塊の画像と該画素塊に関する情報を記憶し、照合手段は、受け付けた画像内の画素塊の画像と前記記憶手段によって記憶されている画素塊の画像を照合し、情報付与手段は、前記照合手段による照合結果に基づいて、前記記憶手段から画素塊に関する情報を抽出して、該画素塊に関する情報を前記受け付けた画像内の画素塊の画像に付与する。
(もっと読む)
車両ナンバー情報読取システム
【課題】今後も随時導入されるであろうご当地ナンバーへの対応を容易且つ迅速に対応することができるばかりでなく、導入のための作業コストや機器コスト等の高騰を抑制しつつ地域毎のフォントの違いに対する文字認識処理を独自で且つ適切に対応し得て、認識精度を大幅に向上することができる車両ナンバー情報読取システムを提供する。
【解決手段】入出場のレーンに設置した撮像装置によりナンバープレートを撮像し、撮像した画像を基にパターンマッチング処理とOCR処理とを行い、OCR処理結果を管理端末上で管理し、出場時のパターンマッチング処理の合致度が予め設定したレベルより高く、且つ、OCR処理結果の合致度が予め設定したレベルより低い場合、管理端末において当該ナンバーの個々のテンプレート文字データを合致度と共に低レベル合致度を収集するDBに保存し、テンプレートデータと比較閲覧可能で、データ再登録を容易に可能とする。
(もっと読む)
パターン認識辞書作成装置及びプログラム
【課題】 辞書を記憶する記憶容量が小さな装置であっても、画像パターンの認識精度を向上させることができるパターン認識辞書作成装置を提供する。
【解決手段】 入力画像の特徴量を求めて特徴ベクトルを生成する特徴ベクトル生成部111と、各画像の特徴ベクトル同士を比較して類似度の高い画像をグループとしてまとめるグループ化部114と、特徴ベクトル生成部で生成された特徴ベクトルに基づいて、画像の画素分布の情報を含む複数の特徴データを生成する主成分分析部113と、パターン認識用辞書を作成する場合に、グループに含まれない画像の特徴データのデータ量よりもグループに含まれる画像の特徴データのデータ量が多くなるように記憶装置23にデータを記憶させる辞書生成・登録部115とを有している。
(もっと読む)
文字認識装置
【課題】文字識別の精度を上げるために、サイズが異なる複数の入力画像を、同一文字間の形のばらつきが小さくなるように正規化を行う。
【解決手段】正規化処理では、画像から文字ストロークの方向の情報を保持する特徴を抽出し、抽出した方向成分特徴のモーメントから画像中の文字の重心と境界を定め、文字のアスペクト比を保存する形で、固定サイズの正規化画像に変換する。まず、方向成分抽出61では、画像から文字ストロークの方向の情報を保持する特徴を抽出する。縦横別々に抽出する方法もある。重心の算出62と境界の算出63では、抽出した特徴のモーメントから文字の重心、境界を定める。アスペクト比算出35では、正規化画像中の文字のアスペクト比を、原画像の文字のアスペクト比から定める。正規化画像生成36では、定めたアスペクト比に従って、文字画像を予め定めた固定サイズの画像に変換する。
(もっと読む)
辞書作成装置、認識装置、認識方法及び認識プログラム
【課題】確率分布を用いた場合の文字認識と同等の文字認識能力を発揮させつつ、辞書容量を削減することを課題とする。
【解決手段】辞書作成装置10は、平均ベクトル及び共分散行列を含んで構成される確率分布を辞書登録するが、全ての文字カテゴリに各々の固有値及び固有ベクトルを対応付けて辞書登録させずに、文字カテゴリ間で特徴ベクトルが類似する分布形状については複数の分布形状を1つの分布形状に纏めて代表させるとともに、代表させる分布形状と纏めようとする文字カテゴリとを対応付けて辞書登録する。
(もっと読む)
文字認識装置、文字認識方法、文字認識プログラムおよびコンピュータ読取り可能な記録媒体
【課題】辞書パターンとして存在しない合成文字を認識することのできる文字認識装置、文字認識方法、文字認識プログラムおよびコンピュータ読取り可能な記録媒体を提供すること。
【解決手段】入力パターンを構成する文字の合成方式が、複数の合成方式のうちのいずれであるかを判定するための合成方式判定部1007と、合成方法対応テーブル1032において、判定された合成方式に対応付けられた辞書パターンの組合せに基づいて、2以上の辞書パターンを合成させるための辞書合成部1008と、合成辞書パターンごとに、入力パターンと照合するための第2マッチング部1009と、入力パターンとの類似度が高い合成辞書パターンに基づく合成文字情報を出力する制御を行なうための出力制御部1011とを含む。
(もっと読む)
基板実装部品の管理システム
【課題】部品の実装を終えた完成形の基板から実装された部品の識別文字情報を採取し、実時間性が求められないことを利用した精度の高い文字認識処理手法を提供し、基板に実装された部品のロット番号を含む識別文字情報の管理を行わせることで基板のトレーサビリティーを安易に可能とする安価なシステムを提供する。
【解決手段】部品情報に基づいて文字列画像を取得し、当該文字列画像を当該基板情報および部品情報と関連付けて、基板認識結果データベースに登録し、基板認識結果データベースに登録済みの文字列画像を、文字辞書に基づいて、文字列画像採取タイミングとは異なる任意の非実時間タイミングで文字認識処理を実施し、認識結果情報を出力し、認識結果情報を前記基板認識結果データベースに登録し、基板認識結果データベースに登録された認識結果情報を検索可能に構成した基板実装部品の管理システムである。
(もっと読む)
字形特徴辞書作成装置、これを備えた画像文書処理装置、字形特徴辞書作成プログラム、字形特徴辞書作成プログラムを記録した記録媒体、画像文書処理プログラムおよび画像文書処理プログラムを記録した記録媒体
【課題】 文字の特徴抽出方法を改良して、より検索精度が高くなるような字形特徴辞書作成装置およびこれを備えた画像文書処理装置を提供する。
【解決手段】 画像文書中の文字数がMである文字列の画像を切り出し、これを1文字ごとに分割して各文字画像の画像特徴を抽出し、その画像特徴に基づき、文字画像の画像特徴を1文字単位で格納している字形特徴辞書より、適合度が高い順にN個(N>1の整数)の文字画像を候補文字として選択し、切り出した文字列の文字数M×N次の第1インデックス行列を作成する。この第1インデックス行列の第1列を構成する複数の候補文字からなる候補文字列に対して、予め定める言語モデルによる語彙解析を適用することにより、候補文字列を意味を成す文字列に調整した第2インデックス行列を作成し、検索に利用する。
(もっと読む)
手書き文字認識のための方法及びシステム
手書き文字認識方法及び装置を提供する。方法が、認識対象のスクリプトを入力するステップと、入力したスクリプトのワイルドカード及び要素を認識するステップと、認識された要素及びワイルドカード情報を、文字ライブラリに事前に記憶された文字と照合するステップと、照合結果を表示するステップとを含む。本発明は、ワイルドカードを使用した手書き文字認識方法を提供し、これにより手書き文字の入力画数が減り、入力効率が向上する。 (もっと読む)
情報処理システムおよび情報処理プログラム
【課題】入力した紙文書の画像から文字認識して得た文字認識結果と同等の紙文書内の文字の操作者からの入力結果とを用いて、その紙文書の画像から文字コードへ変換するにあたって、正確な変換および修正の操作性、利便性を向上させるようにした情報処理システムを提供する。
【解決手段】情報処理システムの比較手段は、同等項目に対する操作者の操作による第1の入力値と文字認識処理による第2の入力値とを比較し、記憶手段は、過去の第1の入力値、該第1の入力値に対応する同等項目に対する過去の第2の入力値、および同等項目に対する修正後の値を対応づけて記憶し、修正手段は、前記比較手段による比較によって、第1の入力値と第2の入力値とが異なる場合は、前記記憶手段に基づいて修正する。
(もっと読む)
文字切出方法及び文字認識装置
【課題】他の文字矩形と結合しない文字矩形パターンを辞書データとして登録し、該辞書データとマッチングした文字矩形を他の文字矩形と結合させずに文字切出を行うようにして、文字切出の困難な文字画像からでも正確でかつ高速に文字パターンを切り出すことができ、誤読文字を低減させることができるようにする。
【解決手段】全角文字又は幅の広い文字及び半角文字又は幅の細い文字を含む文字パターンから成る文字列の画像から各文字パターンを1文字単位で切り出す文字切出方法であって、誤って結合する半角文字又は幅の細い文字、及び、1文字で他の文字とは結合しない文字の文字パターンを辞書データとして登録し、射影によって検出された文字矩形とパターンマッチングを行い、マッチングした文字矩形を他の文字矩形とは結合させずに文字パターンを切り出す。
(もっと読む)
画像認識による計測方法および記録媒体
【課題】 画像認識において、背景による各種外乱の影響を取り除き安定したパターン検出を可能とし、パターンマッチングの処理負荷を削減し処理時間を短縮させる。
【解決手段】 対象物と背景とを分離しそれらの濃度として各原画像の平均濃度を指定する。予めパターン画像の自己相関係数の計算を行う。パターン画像によるスキャン過程で、入力画像の自己相関係数とパターン画像・入力画像間の相互相関係数を計算する。パターン画像から背景部分を除外して対象部分のみでパターンマッチングを行うことにより、背景の外乱の影響が取り除け、計算時間も短縮する。
(もっと読む)
文字認識辞書作成方法及びその装置及び文字認識方法及びその装置及びプログラムを格納した記憶媒体
【課題】原特徴の中から識別に貢献している少数の特徴を選択して少ない計算量で類似文字識別を行う文字認識辞書作成方法とその装置、文字認識方法とその装置および文字認識辞書作成プログラムと文字認識プログラムとを格納した記憶媒体を提供する。
【解決手段】
特徴選択に遺伝的アルゴリズムを適用し、一定値以上の認識率を有する遺伝子に対し特徴数減少比の適合度で以って世代交代を行うことにより、識別能力の高い少数の特徴を得ることができる。また、詳細識別においては詳細識別辞書に格納された特徴番号により識別辞書の特徴を得る構成となっているので、高精度、小辞書容量の文字認識系が実現できる。
(もっと読む)
文字列判定装置、文字列判定方法、文字列判定プログラムおよびコンピュータ読み取り可能な記録媒体
【課題】対象文字列が、予め定められた種類のどれに相当するものかを少ない処理量で判定することができる文字列判定装置を提供する。
【解決手段】文字列の項目と対応付けられた、特定の形状を示す情報である文字列パターンが文字列情報に含まれているかどうかを検出する文字列パターン検出部22aと、文字列パターン検出部22aによって、文字列パターンが文字列情報内に検出された場合に、当該文字列パターンに対応する文字列の項目を、当該対象文字列の項目とする項目判定部22bとを備えている。
(もっと読む)
パターン識別方法、パターン識別装置及びプログラム
【課題】クラス毎のプロトタイプの分布が線形分離不可能、かつ、分散が互いに異なるスパースな分布のプロトタイプにおいても、入力パターンの高精度な識別を行う。
【解決手段】入力したパターンのデータを識別する場合において、予め用意されたプロトタイプのデータを使用して、入力パターンデータのクラス毎の最近傍プロトタイプを決定し、その決定した最近傍プロトタイプと所定範囲の近傍のプロトタイプの集合を決定し、クラス毎の最近傍プロトタイプと所定範囲の近傍のプロトタイプにおける平均を算出し、入力したパターンとクラス毎の最近傍プロトタイプとの平均により重み付けした距離を算出し、算出した距離に基づいて入力パターンデータのプロトタイプを決定するようにした。
(もっと読む)
文字認識装置及び文字認識プログラム
【課題】認識率が十分に向上するまでに筆者が手書きで入力しなければならない文字数の削減を図ることが可能な文字認識装置及び文字認識プログラムを提供する。
【解決手段】手書き入力文字を認識する文字認識装置10が、文字カテゴリと特徴量とを対応付けて記憶する複数の筆者適応辞書15と、複数の筆者適応辞書15のそれぞれに記憶された特徴量と手書き入力文字の特徴量とを比較して、手書き入力文字に対応する文字カテゴリの候補を複数の筆者適応辞書15毎に取得する筆者適応処理部16と、筆者適応処理部16によって取得された文字カテゴリの候補に基づいて、手書き入力文字に対応する文字カテゴリを認識結果として取得する最終認識結果取得部174とを備え、複数の筆者適応辞書15のそれぞれが、一の文字カテゴリに対して、互いに異なる特徴量を対応付けて予め記憶している。
(もっと読む)
パターン認識装置、パターン認識方法、パターン認識プログラム、および記録媒体
【課題】類似度によるパターン認識を高速に行うための技術を提供する。
【解決手段】マッチング部107は、入力特徴ベクトルの成分と辞書特徴ベクトルの成分の積和演算を繰り返し行う。ベクトル成分並べ替え部106は、入力特徴ベクトルの成分のうち、値の大きな成分を優先的に演算の対象として取り出せるように設定する。具体的には、入力特徴ベクトルの成分を降順に並べ替え、並べ替え処理に関する情報を並べ替え情報114として記憶する。これによりマッチング部107は、特徴ベクトルの成分のうち、類似度の値に大きな影響を持つ成分を優先的に演算の対象とする。そのため、すべての成分を類似度算出の演算対象とする必要がなくなる。したがって、予め上記演算の対象とする成分の数を設定したり、閾値を設定し上記演算を途中で打ち切ったりすることができるようになるため、類似度によるパターン認識を高速に行うことができる。
(もっと読む)
パターン認識装置、パターン認識方法、および特徴抽出パラメータの生成方法
【課題】入力画像の認識にとって重要な部分に対して着目を強めた特徴抽出を行うことで、類似文字の認識精度の向上を図る。
【解決手段】入力されたパターン画像に対して、画像全体の領域にて数的に不均一に設定された複数の部分領域それぞれの特徴量を計算する部分領域特徴量計算部と、部分領域特徴量計算部により計算された複数の部分領域それぞれの特徴量から入力されたパターンの特徴ベクトルを生成する特徴ベクトル生成部と、特徴ベクトル生成部より出力された特徴ベクトルを用いて入力されたパターンの識別を行うパターン識別部とを具備する。また、複数の部分領域は、画像全体の領域の一部において他の部分に比べて数的に密に配置されるように設定されている。
(もっと読む)
ベクトル量子化装置
【課題】特徴ベクトルとの間の距離を計算する符号ベクトルを限定することで高速のベクトル量子化を可能にし、かつ良好な量子化結果を得ることを可能にすること。
【解決手段】比較符号ベクトル格納器17は、特徴ベクトル空間を複数に分割した各部分領域内に位置する特徴ベクトルとの間で距離計算および比較すべき符号ベクトルの部分集合を記憶する。部分領域判定部16は、入力された特徴ベクトルが特徴ベクトル空間上のどの部分領域に属するかを判定する。距離計算部12は、入力された特徴ベクトルとそれと距離計算および比較すべきとされている符号ベクトルの部分集合の間の距離計算および比較を行う。比較手段14は、距離計算部12により算出された距離が最小値を示す符号ベクトルのコードを量子化ベクトルとして出力する。
(もっと読む)
1 - 20 / 39
[ Back to top ]