
Fターム[5B075KK03]の内容
Fターム[5B075KK03]の下位に属するFターム
Fターム[5B075KK03]に分類される特許
121 - 140 / 291
構造化された地理的なデータの検索
データは1つまたは複数のデータ・ソースから特定され、前記データは少なくとも1つの構造化されたドキュメントと対応付けされる。前記少なくとも1つの構造化されたドキュメント内に含まれるデータ集合が抽出され、1つまたは複数のレコード項目が検索可能なデータベースに追加され、ここで、前記1つまたは複数のレコード項目は前記抽出されたデータ集合に対応する。 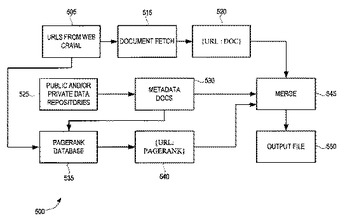 (もっと読む)
(もっと読む)
メタデータ収集システム、コンテンツ管理サーバ、メタデータ収集装置、メタデータ収集方法およびプログラム

【課題】コンテンツを管理する複数のサーバからメタデータを重複なく収集することが可能な、メタデータ収集システム、コンテンツ管理サーバ、メタデータ収集装置、メタデータ収集方法およびプログラムを提供する。
【解決手段】コンテンツならびにコンテンツのメタデータをローカルコンテンツとして管理すると共に、他のコンテンツ管理サーバが格納するコンテンツのメタデータを参照コンテンツとして管理可能な複数のコンテンツ管理サーバと、複数のコンテンツ管理サーバに接続され、複数のコンテンツ管理サーバからメタデータを収集するメタデータ収集装置とを含むメタデータ収集システムにおいて、メタデータ収集装置は、複数のコンテンツ管理サーバそれぞれを参照して、各コンテンツ管理サーバが有するサーバ情報と、各コンテンツ管理サーバが生成した木構造に付加された種別区分識別子に基づいて、各コンテンツ管理サーバからメタデータを収集する。
(もっと読む)
検索システム及び検索方法

【課題】使用者の検索意図に最大限に応じた検索サービスを提供する。
【解決手段】本発明の検索システムは、使用者端末機200から入力された検索語に対応するウェブサイト300に検索語に関する検索を要請する第1検索部114と、ウェブサイト300から提供される第1検索結果を含むウェブページを生成して使用者端末機200に提供する検索結果提供部118とを含む。
(もっと読む)
健康関連情報提供システム
【課題】複数の専門分野の健康関連情報を横断的にその効果と共に提供する。
【解決手段】通信ネットワーク上に存在する膨大な数の健康関連情報に関する臨床学術研究論文をデジタルデータとして取り込んだデータサーバが取り込んだ各論文についてタグの主要情報及びタグのサンプル情報を抽出してタグ情報として記憶し、分析サーバがタグのサンプル情報に基づいて当該論文の信頼性および論文に記載された有用性に対する効果確率を計算してタグ情報に付加してランク分け情報とし、当該ランク分け情報を研究対象及び有用性毎に一覧表として作成し記憶することで、ユーザが利用者端末から照合サーバを通じて健康関連情報に関する論文から抽出され、加工、分析された情報を検索可能としている。
(もっと読む)
情報管理システム、情報管理装置およびプログラム
【課題】
情報の高い安全性を確保するとともに情報参照における機能性を考慮した保存を可能にした情報管理システム、情報管理装置およびプログラムを提供する。
【解決手段】
ディジタルコンテンツを設定した重要度に応じて分割し、分割後のコンテンツ断片にハッシュ関数を適用することで算出したハッシュ値であるコンテンツ断片IDを、クライアントPCの識別情報に前記ハッシュ関数を適用して算出したピアIDによって構成されるハッシュ空間上に写像することでそのコンテンツ断片を分散管理するクライアントPCを決定する。
(もっと読む)
検索プログラム、方法及び装置
【課題】問い合わせ型データベース統合を行う際に異なる値域又は形式のデータ項目間を関連付けできるようにする。
【解決手段】問い合わせ結果の出力構造を規定する構造データ、当該構造データ中の要素とDBの要素との対応関係、DB間の要素の関連付け、及びDB間の要素の関連付け又はDBの特定の要素に適用する双方向変換関数が規定された統合用メタデータを新たに採用する。そして本検索方法は、複数のDBに対する統合的なデータ参照の問い合わせを受け付ける工程と、統合用メタデータから特定される構造体を問い合わせに基づき上方に探索して、構造体中の最上位要素に対応するDBの要素の値を抽出する工程と、上記構造体を構造体中の最上位要素に対応するDBの要素の値に基づき下方に探索して、各DBの各要素の値を抽出する工程と、抽出された各DBの各要素の値を統合用メタデータに従って出力する工程とを含む。
(もっと読む)
対話型のコンテンツ及び広告へアクセスしそれらを表示するためのシステムと方法
個人情報にアクセスし、個人情報を、広告、ソフトウェアアプリケーション、又は同種のものと共に表示するためのシステムと方法である。本システムと方法は、メモリ装置から固有識別子とポインタを検索することと、検索された固有識別子とポインタに対応して、ポインタ表からリダイレクトポインタを検索することと、検索されたリダイレクトポインタを実行して、ソフトウェアアプリケーションを立ち上げ、第1コンテンツを表示することと、第2コンテンツ及び/又は広告を第1コンテンツと共に表示すること、を含んでいる。 (もっと読む)
同報検索システム及び同報検索プログラム
【課題】複数のセグメントに分割されたネットワークにおいて、各セグメントに属するノードに対してデータ検索が可能な同報検索システム及び同報検索プログラムを提供する。
【解決手段】検索対象の各ノードN1〜N10とユニキャスト通信を行う仮想ハブH1を設けたので、複数のセグメントS1〜S6のいずれに属するノードに対しても、データの検索依頼パケットをユニキャストパケットとして送信することで、データを検索できる。これにより、複数のルータR1,R2をマルチキャストに対応したものに取り替えることなく仮想ハブH1を追加するだけで、複数のノードに分散して記憶させたデータを容易に検索できる。
(もっと読む)
データ検索システム及びプログラム
【課題】煩雑な作業を必要とすることなく、特定のキーワードに対する文中での構文・意味上の役割は分かっていても、言葉自体が分からない語を用例から効率良く検索することである。
【解決手段】ユーザから検索対象となる文字列中における第1、第2の検索対象語の指定を受け付けると、検索文字列用言語解析部25は文字列を構成する各語の構文・意味上の役割情報を解析する。検索式生成部26は第1の検索対象語と、第2の検索対象語に対応する構文及び意味上の役割情報とを含む検索式を生成する。データベース検索部27は、この検索式を用いて用例データベース28に登録された文を構成する語と文中における各語の構文・意味上の役割情報とを含む用例データを検索する。
(もっと読む)
画像保存装置
【課題】 或る原稿を複数の保存先へそれぞれ保存する作業における、ユーザ負担の軽減、及び、作業時間の短縮を図る。
【解決手段】 CSVファイルが各記憶装置3毎に用意され、各CSVファイルには画像を保存するための定義情報が行単位で設定されて、共通の原稿画像に係る定義情報が各CSVファイル間で同じ並び順で設定されている。これらのうちユーザにより処理対象として選択された複数のCSVファイルをCSVファイル管理部13が保持し、各CSVファイル内の未処理の行を先頭から順に選択状態として原稿の提供をユーザに要求する。スキャン読み取り部15によりユーザから提供された原稿が読み取られると、画像保存処理部16が、読み取った原稿画像をCSVファイル管理部13にて選択状態とされた各CSVファイルの定義情報に基づく処理をそれぞれ施して、該当する記憶装置3に保存する。
(もっと読む)
データ管理サーバ、データ管理システム、データ管理方法およびプログラム
【課題】データ管理サーバ、データ管理システム、データ管理方法およびプログラムを提供すること。
【解決手段】コンテンツデータおよび該コンテンツデータの属性情報を含むメタデータを記憶するコンテンツサーバと、メタデータに基づいてコンテンツデータを取得するクライアント機器30と、に接続可能なデータ管理サーバであって、複数のコンテンツサーバの各々からメタデータを収集するデータ収集部224と、データ収集部が収集したメタデータを、該メタデータに含まれる属性情報に基づいて階層構造化するデータ処理部232と、クライアント機器からの要求に応じて、データ処理部により階層構造化されたメタデータをクライアント機器に送信する送信部とを備えることを特徴とする。
(もっと読む)
情報交換装置、情報交換システム及びそれらに用いる情報交換方法並びにそのプログラム
【課題】 情報送信側の状況に合わせて送信する情報を選別することが可能な情報交換装置を提供する。
【解決手段】 情報交換装置1は状況検出手段4が外部環境12から検出した状況によって公開プロファイル選別手段5が公開するプロファイルを選別し、通信装置8が選別されたプロファイルを情報交換相手の候補に送信する。通信装置8が情報交換相手の候補から公開プロファイルを受信すると、プロファイルマッチング手段6は公開プロファイル選別手段5が選別した自身の公開プロファイルのマッチングを行い、送信情報選別手段7はマッチングしたプロファイルに関連するジャンルに関する情報のみを選別して通信装置8から送信する。
(もっと読む)
電子機器およびデータ生成方法
【課題】識別名称の定義付けがされたコンテンツを検索可能なデータであって、かつ、より柔軟に階層構造化されたデータを生成することが可能な電子機器等を提供すること。
【解決手段】プリンタ100が、コンテンツごとに少なくとも1つの識別名称の定義付けがされたコンテンツデータ124を入力する入力部110と、前記識別名称と階層名との対応付けを示し、かつ、前記階層名ごとに当該階層の上位階層および下位階層を示す階層構築用辞書データ122等を記憶する記憶部120と、コンテンツデータ124と、階層構築用辞書データ122とに基づき、前記識別名称が前記階層名として定義付けられ、かつ、当該階層名の階層の上位階層および下位階層を示す階層化データ126を生成するデータ生成部130とを含んで構成される。
(もっと読む)
デジタルコンテンツ検索プログラム、デジタルコンテンツ検索装置およびデジタルコンテンツ検索方法
【課題】DLANにおいて、情報検索機能を有さないDMSおよび必要な検索属性を有していないDMSであっても、十分な情報検索機能を有するDMSとともにデジタルコンテンツを一括検索可能とする。
【解決手段】本発明では、DMCまたはDMPの一括検索機能は、“十分な検索機能”を持つDMSに対しては、当該DMSの検索機能を利用した検索を要求する検索要求を行うこととし、“十分な検索機能”を持たないDMSに対しては、“インデックス検索”を使用して当該DMSを代理して検索を行うこととした。このようにして、一括検索時に、一括検索対象のDMSが“十分な検索機能”を持つか否かに応じて、検索要求または“インデックス検索”を動的に切り替えることによって、一括検索対象のDMSが“十分な検索機能”を持つか否かに関わらず、一括検索可能とした。
(もっと読む)
ピアツーピア・オーバーレイ・ネットワークにおける負荷分散のための方法
複数のピアからなるピアツーピア・オーバーレイ・ネットワークにおける負荷分散のための方法において
各ピアは、該ピア自身に属するキーワード範囲を有しており、
保存したいデータリソースは、該保存したいデータリソースのキーワードがピアのキーワード範囲に存在し、該ピアに保存されているデータリソースの数がリソース限界値に達していない場合にのみ、前記ピアに保存される、
ことを特徴とする方法。  (もっと読む)
(もっと読む)
ピア−ツ−ピア・ネットワークでの振る舞いを増強するシステム及び方法
複数のノードを含んだピア-ツ-ピア(P2P)ネットワークにおいて実行するためのシステム及び方法であって、これらノードの大半が、P2P接続のしきい値よりも少ない他のノードへの接続を有している。P2Pネットワーク接続は、前記大半のノードの内の1つの第1ノードと、機能増強されたエンハンスメント接続ノードとの間に設定され、エンハンスメント接続ノードは、P2PネットワークにおけるP2P接続のしきい値よりも多い他のノードへの接続を有している。サーチ要求を第1ノードからエンハンスメント接続ノードへ送信することによって、第1ノードからサーチ要求が発生され、該サーチ要求がエンハンスメント接続ノードからP2Pネットワークの他のノードに転送される。エンハンスメント接続ノードにおいて、サーチ要求に対するサーチ結果を収集し、サーチ結果のフィルタリング、ランク付け、又は追加コンテンツの付加を実行して、その結果を第1ノードに返送する。  (もっと読む)
(もっと読む)
画像処理システム、情報処理装置、画像処理装置、画像処理方法及びプログラム
【課題】 画像データの転送先となる画像処理装置を選択するにあたって、入室管理システムにおける入室管理情報を考慮した転送先を選択させる。
【解決手段】 画像処理装置は、ユーザを識別するための識別情報を入力する入力手段と、前記識別情報によって識別されるユーザが入室可能なエリアを示す入室管理情報を取得する取得手段と、前記画像処理装置において入力されたデータの送信先となる画像処理装置を一覧表示する際に、前記入室管理情報に基づいて、各画像処理装置が前記ユーザが入室可能なエリアに存在するか否かを識別可能に表示する表示手段とを有する。
(もっと読む)
特定用途向けの文書収集方法及びプログラム
【課題】ネットワークから特定用途向けの文書を迅速に収集することを可能とする。
【解決手段】ある分野に関する文書群である正例文書群と、前記分野と関連が少ない分野に関する文書群である負例文書群とを与え、前記正例文書群及び前記負例文書群の参照関係に基づいて、前記分野に関する収集すべき文書を決定し、前記ネットワークから前記収集すべき文書を収集する。
(もっと読む)
音声対話装置および音声対話方法
【課題】本発明の目的は、複数のエージェント(外部装置)とやり取りを行う際に、ユーザが行うインタラクションを軽減し、ユーザの利便性の良好な音声対話装置を提供することである。
【解決手段】ユーザからの音声情報を入力する手段(201)と、音声言語解析用辞書を記憶する手段(205)と、前記音声言語解析用辞書を用いて前記ユーザからの音声情報を解析することによって、前記ユーザの要求を抽出する手段(203)と、抽出した前記ユーザの要求を満たす外部装置との間で、前記ユーザの要求およびその応答結果の授受を制御する制御手段(207)と、前記応答結果をユーザに出力する出力手段(202)と、を備える音声対話装置。
(もっと読む)
ブックマークおよびランク付け
システムは、1つ以上の文書またはサイトに関連するブックマークを受付ける。このシステムは、文書のコーパスを検索して検索結果を得るとともに、受付けたブックマークを用いて検索結果をランク付けする。 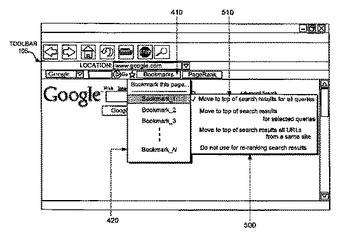 (もっと読む)
(もっと読む)
121 - 140 / 291
[ Back to top ]