
Fターム[5B075QM02]の内容
Fターム[5B075QM02]の下位に属するFターム
Fターム[5B075QM02]に分類される特許
81 - 100 / 111
情報検索装置
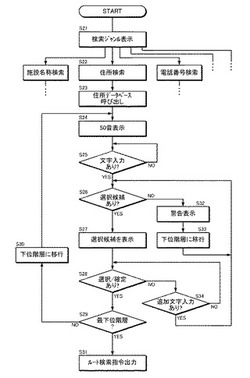
【課題】 カーナビゲーションシステムにおける目的地検索等を容易かつ短時間で行うことができる情報検索装置を提案する。
【解決手段】 検索装置本体11は、ステップS26で住所データベース31内の第2階層31bに選択候補があるか否かを判定し、この判定がNoの場合、ステップS32で警告表示を一瞬行った後、ステップS33で下位階層に移行する。次いで、検索装置本体11は、ステップS26に戻って住所データベース31内の第3階層31cに選択候補があるか否かを判定し、この判定がYESの場合には選択候補をディスプレイ2に表示する。乗員が第6階層31fまで選択/確定を終えると、ステップS29の判定がYESとなるため、検索装置本体11は、ステップS31でルート検索部にルート検索指令を出力して目的地検索処理を終了する。
(もっと読む)
映像閲覧システム、コンピュータ端末並びにプログラム

【課題】ネットワークを利用してストリーミング映像に含まれるシーン及び当該シーンに付されたアノテーション情報を検索・閲覧可能とする。
【解決手段】ストリーミングサーバに登録されたストリーミング映像について、各ストリーミング映像に含まれる任意のイベントに関し少なくとも映像IDと当該映像における開始時間・終了時間とイベント内容とを登録した検索テーブルを有する検索サーバを備える。この検索サーバはユーザ端末からの要求に応じて条件に合致する映像シーンを検索し、少なくとも当該シーンに係る映像IDと開始時間・終了時間とを含むシーン情報をユーザ端末に送信する。ユーザ端末がいずれかのシーン情報を指定して映像配信要求を行うと、その映像のその時間幅がストリーミング配信される。また、任意のシーンについて別途作成されたコーチング等の付加情報が関連づけられており、シーン閲覧に際しこの付加情報も享受できるようにする。
(もっと読む)
検索装置
【課題】文字列に対する訂正時の誤操作の恐れを解消する。
【解決手段】処理がスタートされ、ステップ〔1〕で入力文字列の検索が終了して該当索引語が無かった場合には、ステップ〔2〕で入力文字列中に、例えば「0」〜「4」「−」の声調を表す符号があるか否か判断される。そしてステップ〔2〕で符号があるとき(YES)は、ステップ〔3〕で表示される文字列中の「0」〜「4」「−」の符号を削除して、ステップ〔4〕で入力画面に戻り訂正が行われる。また、ステップ〔2〕で符号が無いとき(NO)は、そのままステップ〔4〕で入力画面に戻り訂正が行われる。
(もっと読む)
情報処理装置および情報処理のプログラム
【課題】 検索のたびに部分一致又は前方一致のいずれかをユーザが設定することなく情報の検索を可能にするとともに、1つの文字を入力するだけで情報の検索を可能にする。
【解決手段】 CPU11は、リモコン装置のスイッチ操作によって、入力された歌手名や曲名の文字が1つだけで構成されているか、又は、2つ以上の文字で構成されているかを判定し、1つだけの文字である場合には検索対象の情報をその文字に基づく前方一致で検索し、2つ以上の文字列である場合には検索対象の情報をその文字列に基づく部分一致で検索する。
(もっと読む)
車両用施設検索装置
【課題】ユーザーの検索目標となる可能性が高い順に、検索された施設名称を表示することが可能な車両用施設検索装置を提供すること。
【解決手段】ECU8は、検索された施設情報の各々における優先度をそれぞれ算出し、算出された優先度が大きい順に、当該施設情報に含まれる施設名称をリストアップして、ディスプレイ3に表示する。入力された文字列によっては、ECU8は当該文字列を施設名称の一部として含む施設情報を多く検索してしまう場合がある(例えば、「とうきょう」と入力した場合、施設名称に東京ディズニーランドや東京タワー等、「とうきょう」を含む施設情報が多く検索される)。このような場合には、検索された施設情報の各々に含まれる施設名称を、算出した優先度合いが大きい順にリストアップして表示することで、ユーザーの検索目標となる可能性が高い順に、検索された施設名称を表示することが可能となる。
(もっと読む)
番組データ処理装置、番組データ処理方法、制御プログラム、記録媒体、ならびに、番組データ処理装置を備えた録画装置、再生装置、および、情報表示装置
【課題】番組タイトルの表記の揺らぎに対応し、番組の同一性の判定における精度を向上させる。
【解決手段】本発明に係る番組データ処理装置は、番組に関する情報を示す番組情報から、番組の番組タイトルを抽出するタイトル抽出部30と、タイトル抽出部30によって抽出された、ユーザにより選択された番組の選択番組タイトルと、タイトル抽出部30によって抽出され、複数の番組情報からなる番組情報データベースにあらかじめ記録されている、番組の記録番組タイトルとを文字ごとに比較し、選択番組タイトルと記録番組タイトルとの間で文字が一致する部分と、一致する文字の配列とを評価することにより、両番組タイトル間の類似性を示す類似性距離を算出する類似性距離算出部40と、上記類似性距離が、所定の条件を満たす場合に、上記選択番組タイトルと上記記録番組タイトルとは同一番組のタイトルであると判定する同一番組判定部60とを備えている。
(もっと読む)
系列パターン抽出装置、系列パターン抽出方法、および系列パターン抽出プログラム
【課題】分析者あるいは利用者の要求に適した系列パターンのみを漏れなく短時間で抽出すること
【解決手段】抽出された系列パターンが含んでいなければならない系列データを表す制約系列データが予め指定される。入力された複数の系列データから、まずは系列長が1の系列パターン候補をもとめる。次に、この系列パターン候補の系列長を延長して複数の新たな系列パターン候補をもとめることにより、系列パターン候補の集合を生成する。この系列パターン候補集合において、制約系列データを含まない系列パターンしか生成し得ない系列パターン候補を削除したのち、制約系列データを含み、かつ頻出する系列データを新たな系列パターンとして抽出する。
(もっと読む)
距離の概念に基づく言語処理装置
【課題】 本発明は、基本的には,迅速かつ簡単に類似文字列を検索できる文字評価システムを提供することを目的とする。
【課題手段】 上記の課題は,基本的には,対比する二つの文字列の"距離"を求め,その距離に基づく評価値を類似度とし,その評価値を比較することにより類似度を評価するシステムにより解決される。具体的には,本発明は,文字列入力手段2と,文字数算出手段3と,入力文字列の各文字に対して,先頭と末尾との間の文字が等間隔となるように,n/Nの数値を割り当てるための数値割り当て手段4と,前記記憶文字列の第m番目の文字に対して,m/Mの数値を割り当て記憶するための記憶手段5と,文字一致性判断手段6と,差分手段7と,二乗手段8と,評価値算出手段9とを備えた入力文字列と記憶文字列の類似度を評価するための評価システムなどに関する。
(もっと読む)
情報指定システム、情報指定方法、サーバ装置、情報指定装置及び情報指定プログラム
【課題】 用紙等に印刷された文書中の単語情報を容易に指定することができ、特に部分的に入力される単語情報からの指定を容易かつ正確に行うことができるようにする。
【解決手段】 情報指定装置100として携帯端末、例えば携帯電話機が用いられる。この情報指定装置100は、基地局200を通じてインターネットなどの通信網300に接続され、さらにこの通信網300には、電子文書の収められた文書管理データベース401を有する外部サーバ400が接続されている。一方、ユーザーの手元には電子文書が用紙にプリントアウトされた紙文書500が配布されており、この紙文書500には、外部サーバ400に収められた電子文書をアクセスするための2次元コード情報501が印刷され、この2次元コード情報501を用いて情報指定装置100により文書管理データベース401に保存された電子文書が特定されて、単語情報の指定が行われる。
(もっと読む)
文字処理装置、文字処理方法及び記録媒体
【課題】 紙文書をスキャンし、オリジナルの電子文書を検索する原本検索において、精度高く応答性能の良い検索手段を実現する。
【解決手段】 OCRされたテキストから単語を抽出し、未知語に対しては屈折の影響を除去できるように単純化処理を行い、かつ、誤認識の観点から類似文字で構成される未知語を同一単語に統合しつつ未知語を登録し、統合された未知語をベースとして含有単語の統計情報に基づいて文書類似性を判定する処理を入れることにより、屈折方法の不明な単語に対する未知語の数を大幅に削減でき、高速の原本検索が実現できる。
(もっと読む)
文書検索装置及び方法と記憶媒体
【課題】 従来の検索技術では、依然として無関係なヒットが発生してしまう。
【解決手段】 検索クエリと当該検索クエリの展開クエリとを基に、検索対象の文書データを検索して前記検索クエリ及び前記展開クエリに一致する文字列を抽出し(S13)、その抽出された文字列が、未知語領域を含むか否かを判定し、未知語領域を含まないと判定された場合に、抽出された文字列の類似度を低下させるように調整し(S14)、その調整された類似度に応じた順番で文字列を検索結果として出力する(S16)。
(もっと読む)
データ処理方法、電子機器およびプログラム
【課題】 異なる複数の属性の各々について名前データが割り当てられたコンテンツデータの検索処理を行う場合に、指定された属性の名前データの検索を効率的に行うことができるデータ処理方法を提供する。
【解決手段】 アルファベットと数字の画像を操作してイニシャルが入力される。それに続いて、検索の属性(アーティスト名、アルバム名、トラック名)が選択される。属性の選択をトリガーとして、イニシャル検索が開始される。
(もっと読む)
病名特定装置
【課題】 ICDコード等に対応する主病名の候補が記憶された主病名DBに基づいて,医師等による入力文字列に含まれる主病名を高速に(効率的に)特定すること。
【解決手段】 入力文字列について,その後尾側における接尾語最大文字数から順次文字数を減らしながら抽出した部分文字列を接尾語DBから検索することによる接尾語の特定(S5),及びその先頭側における接頭語最小文字数から順次文字数を増やしながら抽出した部分文字列を接頭語DBから検索することによる接頭語の特定(S9)とを個別に行い,その特定がなされるごとに,特定された接尾語や接頭語を除去した残りの文字列について主病名DBを検索(S3,S12)することにより主病名を特定する。また,前記主病名を特定できなかった場合,その特定できなかった文字列を表示させ,さらにこれに近似するものを主病名DBの中から選択して表示させる(S20)。
(もっと読む)
データレコードの検索方法とそのためのプログラム
【課題】 データの一部にワイルドカードの使用が許容されているデータレコードの集合を記憶したファイルから、照合データに対応したデータレコード群を、利用者が利用しやすい順に並べ替える検索方法とそのためのプログラムを提供する。
【解決手段】 S102でまずワイルドカードの使用が許容されているデータレコードの集合を記憶したファイルから、照合データに対応したデータレコード群を抽出する。抽出されたデータレコード群は、その内容に無関係の順で出力される。そこでS104で抽出したデータレコードに対して、照合データと照合対象の部分データに含まれるワイルドカードの数を計数する。S106では、抽出されたデータレコード群を計数したワイルドカードの少ない順に並べ替える。これにより、照合データと一致度の高いデータレコード順に並べ替えられたデータレコード群を得ることができる。
(もっと読む)
データの検索方法
【課題】 祖先・子孫包含関係を含むクエリーを効率良く処理する。
【解決手段】 親ノードのラベルの後に兄弟関係を示すコードを付加することで子ノードのラベルが決定されるラベルを用い、XML文書の各項目に前記ラベルを付して格納したデータベースにおける祖先・子孫の包含関係の検索条件を含むデータの検索方法を提供する。
このデータの検索方法は、祖先候補のラベルの長さを示したラベル長リストを作成するA1段階と、前記ラベル長リスト中のラベル長分だけ子孫候補の各ラベルから先頭部分を各種1つずつ取得し先頭部分リストを作成するA2段階と、前記祖先候補の各ラベルと、前記先頭部分リストとを比較して、一致するラベルのみを取得するA3段階と、を有してなる。
(もっと読む)
通信端末装置
【課題】通信ネットワーク上のデータベースを対象とするキーワード検索を行う場合、通信ネットワークやデータベースサーバの負荷を軽減し、かつ迅速に検索結果が得られる通信端末装置を提供する。
【解決手段】通信ネットワークL上のデータベース22をアクセスして、キーワード検索する機能を備えた通信端末装置10であって、データベース22にアクセスした後、検索キー入力部1にキーワードを入力し検索した検索データ5aを記憶部5に一時的にダウンロードし、その後は、検索キー入力部1に入力したキーワードに文字が加えられる毎に、記憶部5にダウンロードされた検索データのうちから、その文字が付加されたキーワードを含んだ検索データを自動的に抽出するようにしている。
(もっと読む)
URL検索方法及び検索装置
【課題】 URLを表す文字列データを検索キーとして、簡単な処理でデータベースの検索を高速化し、検索装置を構成するハードウェア回路等の構成を簡易にする。
【解決手段】 URL文字列を、ホスト及びドメインからなる第1の文字列と、パス及びデータネームからなる第2の文字列とに分離する分離部100と、第1の文字列又は第2の文字列のいずれか一方の文字列の順序を入れ替える文字列順変換部200と、文字列の順序を入れ替えた第1の文字列又は第2の文字列と、文字列の順序を入れ替えなかった第1の文字列又は第2の文字列について、単一の最長一致検索を行う最長一致検索部300とを備えるURL検索装置であって、URLをキーにデータベース400を検索する。検索キーを、後方一致又は前方一致に統一することで、検索機能を1種類にし、検索機能を備えた回路の規模を小さく構成することが容易になる。
(もっと読む)
文字列検索の方法および設備
本発明は、多数の長い文字列を有する、あるいは単一の長い文字列を有するデータベース(80)中における、問い合わせ文字列(34)と部分一致または完全一致する内容をもつある最終的な個数の結果文字列(30〜33)を検索する方法に関するものである。該方法は、問い合わせ文字列をある第一の個数の入力問い合わせ文字列(35、36、37)に分割し、前記第一の個数の入力問い合わせ文字列のそれぞれの文字列に対してある第二の個数の近傍文字列(38〜41、42〜45、44〜49)を決定し、ここで、前記第二の個数の近傍文字列のそれぞれの文字列は所定の第一の誤り個数の誤りを有するものとし、前記第二の個数の近傍文字列のそれぞれの文字列に対する完全一致文字列(50〜61、70〜74)を、ある検索方法に基づいて、ある第三の個数、データベースから検索し、前記データベースから検索された完全一致文字列をつなげてある第四の個数の中間文字列(29、30、32、33、34)にし、ここで、前記中間文字列のそれぞれに含まれている検索された完全一致文字列(50〜61、70〜74)は前記データベース中で相続いているものとし、前記第四の個数の中間文字列に基づいて最終的な個数の結果文字列(30〜33)を決定し、ここで、前記最終的な個数の結果文字列のそれぞれの文字列は、前記問い合わせ文字列(34)に比較して高々ある所定の第二の誤り個数の誤りを有するようにするステップを有している。これにより、前記問い合わせ文字列と比較しての完全一致または軽微な誤差のみを含む部分一致、そしてより大きなデータベースにおいても比較的控えめな計算機パワーの使用での高速検索が可能となる。  (もっと読む)
(もっと読む)
車載情報端末
【課題】HDDに記録されている数多くの楽曲の中から、曲名やアーティスト名が一文字である楽曲を適切に検索できる車載情報端末を提供する。
【解決手段】キーワードを入力し(ステップS1)、そのキーワードに基づいてHDDから楽曲を検索する。このとき、キーワードが一文字だけ入力された場合には、入力されたキーワードに完全一致するアーティスト名、トラック名またはアルバム名のいずれか少なくとも一つを有する楽曲を検索する(ステップS3)。キーワードが二文字以上入力された場合には、入力されたキーワードを含むアーティスト名、トラック名またはアルバム名のいずれか少なくとも一つを有する楽曲を検索する(ステップS4)。
(もっと読む)
辞書登録装置、辞書登録方法および辞書登録プログラム
【課題】複数の文字種が含まれる単語を辞書に登録する辞書登録装置を提供すること。
【解決手段】単語を保持する辞書121を記憶する辞書記憶手段と、入力文書を形態素解析し未知語を抽出する形態素解析部102と、前記未知語の前方と後方の少なくとも一方の単語を結合した拡張未知語を生成する未知語範囲拡張部103と、前記未知語を拡張した部分の表記が一致する単語であって前記辞書に登録されている既登録単語を検索する部分一致検索部104と、前記既登録単語のうち前記未知語に相当する部分の表記の文字属性と前記未知語の表記の文字属性とに基づき、表記の類似性を判定する表記類似性判定部105と、前記表記類似性判定部105が前記既登録単語のうち前記未知語に相当する部分の表記と前記未知語の表記とが類似すると判定した場合に、前記拡張未知語を前記辞書に登録する辞書登録部106とを備えた。
(もっと読む)
81 - 100 / 111
[ Back to top ]