
Fターム[5B075QM07]の内容
Fターム[5B075QM07]に分類される特許
1 - 20 / 92
情報推薦システム、方法、及び、プログラム
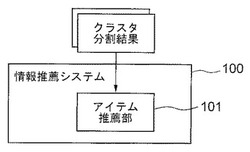
【課題】計算量の増大を招かずに、推薦結果の多様性や精度を調整可能な情報推薦システムを提供する。
【解決手段】情報推薦システム100は、アイテム推薦部101を有する。アイテム推薦部101は、複数のユーザ分類手法を用いてユーザの集合を複数のクラスタに分割することで得られる、各ユーザ分類手法に対応した複数のクラスタ分割結果を組み合わせて、ユーザにアイテムを推薦する。
(もっと読む)
ランドマーク推薦装置及び方法及びプログラム

【課題】 動作主が好む、位置座標以外のランドマークの特徴に基づいて、ランドマークを推薦する。
【解決手段】 本発明は、位置座標の近さ以外で複数のランドマークを潜在的に結びつける特徴(潜在トピック)の存在を仮定して、動作主が各潜在トピックに対して興味を持つ確率値θ(ユーザ固有トピック出現確率)と潜在トピックから各ランドマークが選択される確率値φ(トピック固有ランドマーク存在確率)を学習し、これらの確率値、動作主の移動履歴情報、ランドマーク情報とから算出される、動作主がランドマークを訪問する確率値に基づいて、動作主に対してランドマークを推薦する。
(もっと読む)
情報検索装置、情報検索方法及び情報検索プログラム
【課題】検索結果から分類された複数のクラスタ群から選択された特定のクラスタの内容をより詳細に表示しながらも検索結果の全体像を単一の画面内で表示する。
【解決手段】入力解析部2にてユーザからの入力情報が出力済み検索結果のクラスタ群からのクラスタの選択であると判断されると、出力内容選択部4は、当該選択されたクラスタの表示画面の面積を拡大させる一方で選択されなかったと判断されたクラスタの表示面積を縮小させる。そして、前記拡大された表示画面に出力させる内容として前記選択されたクラスタに加えてその下位階層のクラスタを選択すると共に、前記縮小された表示画面に出力させる内容として前記選択されなかったと判断されたクラスタに属する上位階層のクラスタを選択する。
(もっと読む)
ブログサービス提供システム
【課題】アバターも情報伝達機能を有するブログサービスを提供できるブログサービス提供システムを提供する。
【解決手段】ブログサービス提供システムは、アバターの表示に利用する画像データ組み合わせを変えることにより、外観の異なる複数種類のアバターを表示可能な画像データ群を記憶した記憶手段と、各ユーザが自身のブログに最も最近書き込んだ情報の内容を解析することにより、記憶手段に記憶されている画像データ群の中から、各ユーザのアバターの表示に用いる複数の画像データの組み合わせを決定する組み合わせ決定手段と、画像データ決定手段により各ユーザについて決定された組み合わせの画像データを用いて、各ユーザに、アバターが表示されるブログページを提供するブログページ提供手段とを備える。
(もっと読む)
文字列比較プログラム、文字列比較装置及び文字列比較方法
【課題】文字列同士の比較処理において、文字列の意味内容を考慮した比較を実現する。
【解決手段】比較対象とする名寄せ元データ2A及び名寄せ先データ2Aの夫々に含まれるレコードの比較対象となる項目の文字列を、概念構造生成部4が単語単位に分割する。さらに、概念構造生成部4は、各文字列に含まれる各単語を意味的に識別する概念記号を要素とし当該各要素が単語の有する意味的な性質を表す意味属性又は単語の配置に基づいて関連付けられた名寄せ元概念構造10A及び名寄せ先概念構造10Bを生成する。照合部5は、名寄せ元概念構造10A及び名寄せ先概念構造10Bで対応する各要素の概念記号同士を比較して項目ごとの比較結果を生成するとともに、各項目の比較結果を総合して総合評価値11を生成する。判定部6は、当該総合評価値11と名寄せ処理定義9の判定閾値とに基づいて両レコードが一致しているか否かを判定し、名寄せ結果3を出力する。
(もっと読む)
文書検索キーワード提示装置、文書検索キーワード提示方法および文書検索キーワード提示プログラム
【課題】利用者の移動状態に応じた適切な検索語を提示することができる文書検索キーワード提示装置を提供する。
【解決手段】文書DB101内の文書中から地名と特徴表現との対応およびその基本スコアを抽出する地名-特徴表現対応抽出部102と、前記基本スコアを改善した地名-特徴表現スコアを算出して地名-特徴表現対応DB104に格納する地名-特徴表現スコア改善部103と、利用者端末200の軌跡に基づいて、今後の移動範囲を推定する端末位置範囲推定部105と、前記推定された地理範囲に対応する地名表現を求める位置範囲地名表現変換部106と、地名とその地名の重みを格納した地名重みDB108と前記地名-特徴表現対応DB104を参照して、前記位置範囲地名表現変換部106によって変換された地名表現に対応した特徴表現を選出する特徴表現選出部107と、を備える。
(もっと読む)
文書分類装置およびプログラム
【課題】ユーザによる移動操作の対象外の文書であっても、精度よく再分類することを可能とする。
【解決手段】文書移動処理部321は、文書を移動元カテゴリから移動先カテゴリに移動する。再分類候補決定部322は、階層構造における移動元カテゴリおよび移動先カテゴリの位置に基づいて再分類先カテゴリを決定する。再分類候補決定部322は、再分類先カテゴリに属する文書を再分類対象文書として決定する。半教師文書決定部323は、移動された文書の特徴を表す第1のベクトル、再分類先カテゴリの特徴を表す第2のベクトルおよび再分類対象文書の特徴を表す第3のベクトルに基づいて再分類対象文書の中から再分類先カテゴリの半教師文書を決定する。再分類部324は、移動された文書および再分類先カテゴリの半教師文書に基づいて再分類対象文書を再分類先カテゴリに分類する。
(もっと読む)
文書分類システムおよび文書分類プログラムならびに文書分類方法
【課題】各カテゴリに対してキーワード等の指定を要さず、機械学習により分類ルールを学習することでテキスト文書を各カテゴリに分類し、分類結果が得られた理由がユーザに容易に理解可能である文書分類システムを提供する。
【解決手段】各テキスト文書に対して言語処理を行って単語に分解する言語処理部10と、ユーザからの指示に基づいて教師データとするテキスト文書を指定する手動分類部30と、教師データに基づいて機械学習により単語毎に学習モデルを算出する学習部40と、学習モデルと分類対象のテキスト文書に含まれる各単語に基づいて、分類対象のテキスト文書について、カテゴリ毎に分類スコアを算出し、分類スコアが最大となるカテゴリに分類対象のテキスト文書を分類する自動分類部50と、各テキスト文書の各カテゴリへの分類結果、および各テキスト文書についてのカテゴリ毎の分類スコアをユーザに提示するインタフェース部60とを有する。
(もっと読む)
評判分析装置、評判分析方法及び評判分析プログラム
【課題】評判分析の精度と計算処理速度の向上を図ること。
【解決手段】評判分析装置1は、分析対象が所属するカテゴリが概念的な上下関係に基づく木構造の階層の各層に配されこの各層のカテゴリに評判情報を示す仮説がその評価情報を伴って付与されてなる仮説群を予め格納した階層型仮説オントロジ2と、入力された分析対象所属カテゴリに合致したカテゴリとその仮説及び評価情報を階層型仮説オントロジ2から抽出する評判仮説作成部3と、前記抽出されたカテゴリとその仮説及び評価情報を格納する仮説テーブル4と、入力された分析対象記事に対し、仮説テーブル4に格納された仮説が含意しているか否かの判定を行い、前記含意していると判定された仮説とその評価情報を仮説テーブル4から引き出し、この仮説と評価情報に基づく評価分析結果に入力された分析対象キーワードを付したものを評判分析結果として出力する記事合意認識部5を備える。
(もっと読む)
投稿文章分析装置、投稿文章分析方法、および、投稿文章分析装置用プログラム
【課題】ユーザから投稿される文章を高速に分析できる投稿文章分析装置、投稿文章分析方法、および、投稿文章分析装置用プログラムを提供する。
【解決手段】本発明は、ユーザ端末30からユーザが投稿してくる文章データを受信し(S1)、文書データを記憶し(S2)、文章データに関する時間情報に基づき、文章データを順序付けし(S3)、順序で隣接する文章データの文書間の文書間距離を算出して、文書間距離に基づき、文書データをクラスタリングする(S4)。
(もっと読む)
類似語検索サーバ及び方法
【課題】検索範囲の拡大の幅をより大きくして洩れなく類似語を検索する類似語検索サーバ及び方法を提供する。
【解決手段】類似語検索サーバ1は、検索クエリとして指定された文字列のキー入力情報を受信したことに応じて、辞書DB21を用いて受信したキー入力情報の比較に基づく候補語の検索を実行する読み下し検索手段12と、読み下し検索手段12による実行結果として複数の第1の候補語を出力する第1結果出力手段13と、第1結果出力手段13により出力された複数の第1の候補語の各々に対して辞書DB21を用いて第1の候補語に対応する文字の文字情報の比較に基づく候補語の検索を実行する文字ベース検索手段14と、文字ベース検索手段14による実行結果として複数の第2の候補語を出力する第2結果出力手段15とを備える。
(もっと読む)
辞書生成処理方法、プログラム及び装置
【課題】ランキングなどに用いられる適切なキーワード・セットの生成を省力化する。
【解決手段】本方法は、関連語格納部から、シード語と当該シード語に対するユーザ支持の有無を表すフラグとを格納するシード語格納部に格納されている各シード語に対応する関連語を抽出し、シード語毎に、各抽出関連語について、当該シード語に対する近さ度合いを表し且つフラグ状態から算出されるユーザ支持率に応じて調整される近さスコアを算出し、各抽出関連語について、各シード語に対する近さスコアと当該シード語のフラグに応じて特定される係数との積の総和である関連度を算出し、算出関連度に応じて関連語を抽出して候補語としてユーザに提示し、各候補語についてユーザ支持の有無を表すデータを受信し、候補語の全てにユーザ支持がある場合候補語を辞書に登録し、1つでも候補語にユーザ支持がない場合、それら候補語をシード語としてシード語格納部に格納する。
(もっと読む)
ヘッドマウントディスプレイ装置、及びヘッドマウントディスプレイ装置を用いた画像共有システム
【課題】HMDを装着したユーザが所定の作業を行っている際に、HMDに供給または記憶された複数の画像情報から、ユーザが行っている作業に関連したユーザにとって必要な情報のみを選定でき、該情報に基づいた画像のみをユーザにより視認されるように構成されたヘッドマウントディスプレイ装置、及びヘッドマウントディスプレイ装置を用いた画像共有システムを提供する。
【解決手段】撮像された外景画像BGの撮像画像から撮像画像内の全ての特徴点が抽出される(SA2)。特徴点が抽出されると、マニュアル画像MNが表示される(SA3)。マニュアル画像MNが表示されると、複数の付属画像ACの特徴点データがDBサーバ200から取得される(SA4)。複数の付属画像ACの特徴点の特徴点データが取得されると、複数の付属画像ACの中にユーザが行っている作業と関連のある少なくとも1つの付属画像ACがあるか否かが判断される(SA5)。
(もっと読む)
情報処理システム、サーバ装置、情報処理方法、およびプログラム
【課題】情報処理システム、サーバ装置、情報処理方法、およびプログラムを提供する。
【解決手段】複数のファセット項目、および、前記ファセット項目の各々の下位に階層的に配されたファセット値、からなり、前記複数のファセット項目に優先度が付されたファセット型データをコンテンツごとに記憶する記憶部と、クライアント端末から一のコンテンツを特定するコンテンツ特定情報を受信する受信部と、前記一のコンテンツの1または2以上のファセット項目、および前記1または2以上のファセット項目の各々に属するいずれかのファセット値を選択する選択部と、前記選択部により選択された選択ファセット項目および選択ファセット値に基づいて前記一のコンテンツの関連情報を取得する取得部と、前記取得部により取得された前記関連情報を前記クライアント端末に送信する送信部とを備えるサーバ装置。
(もっと読む)
情報処理装置、情報処理方法、及びプログラム
【課題】人物の年齢や性別等に応じて、しかるべき適切な情報を提示させる。
【解決手段】記憶部42は、人物に提示するための提示データを予め保持し、被写体情報取得部41は、被写体を撮像して得られる撮像画像から、被写体を検出し、表示制御部43は、予め保持されている提示データのうち、被写体の検出結果に対応する提示データを読み出し、読み出した提示データを出力する。本発明は、例えば、被写体を撮像して得られる撮像画像から、被写体を検出し、その検出結果に基づいて、ディスプレイの表示を制御するコンピュータに適用できる。
(もっと読む)
複合イベント処理向けクエリ自動生成装置
【課題】複合イベント処理向けのクエリをイベントログから自動的に生成する。
【解決手段】イベントログに頻出する属性値の組み合わせのパターンを求め、当該パターンに基づいて頻出イベントを自動的に生成する。この後、ラベルを付した頻出イベントをイベントの発生順に配列した頻出イベント列を生成する。この頻出イベント列に基づいて、インシデントの発生検出に必要なクエリを生成する。
(もっと読む)
商品推薦装置
【課題】 購買履歴、閲覧履歴がなくても、商品の推薦を行うことが可能であるとともに、利用者に対して的確な商品を推薦することが可能な商品推薦装置を提供する。
【解決手段】 各クイズ問題、商品情報についてキーワードを設定しておくとともに、商品情報についてキーワードに関連する商品文書ベクトルを求めておく。そして、クイズ問題に対して解答がなされた場合に、正解・不正解を判定し、正解問題について、キーワードと誤答率に基づいて正解文書ベクトルを作成するとともに(a)、不正解問題について、キーワードと正答率に基づいて不正解文書ベクトルを作成する(b)。正解文書ベクトル、不正解文書ベクトルそれぞれについて、商品文書ベクトルとの類似度を求め、類似度の高い商品情報を抽出して利用者に提示する。
(もっと読む)
フレーズ自動挿入装置およびプログラム
【課題】基本文に詳細文の文字列を挿入する場合、係り受け構造に変化が生じない要約文を生成するフレーズ自動挿入装置を提供する。
【解決手段】係り受け整合度記憶部は、表現同士の係り受けの整合度を記憶する。フレーズ挿入位置候補検出部は、挿入先の文のフレーズ間および文先頭等を、挿入位置候補として検出する。フレーズ挿入位置決定部は、係り受け構造データと係り受け整合度記憶部から取得する係りやすさの整合度とに基づき、フレーズ挿入位置候補に挿入フレーズを挿入したときに第1の文データの係り受け構造を壊すか否かを判定し、係り受け構造を壊さないフレーズ挿入位置候補を検出した場合に当該フレーズ挿入位置候補に挿入フレーズを挿入する。
(もっと読む)
情報処理装置、情報処理方法、及び、プログラム
【課題】モデル化対象に対して適切な規模の学習モデルを得る。
【解決手段】対象モジュール決定部22は、時系列パターン記憶モデルを、最小の構成要素であるモジュールとして有する学習モデルのうちの、尤度が最大のモジュールである最大尤度モジュール、又は、新規のモジュールを、時系列パターン記憶モデルのモデルパラメータを更新する対象の対象モジュールに決定し、更新部23は、学習データを用いて、対象モジュールのモデルパラメータを更新する。この場合に、対象モジュール決定部22は、学習データを用いて、最大尤度モジュールの学習を行った場合と、新規のモジュールの学習を行った場合とのそれぞれの場合の学習モデルの事後確率に基づいて、対象モジュールを決定する。本発明は、例えば、時系列のデータの学習等に適用できる。
(もっと読む)
感性情報抽出装置、感性検索装置、その方法およびプログラム
【課題】検索対象のイメージを表す感性表現を用いて情報検索を行う際に、品質、外見的特長、性格等の検索対象が有する様々な側面について考慮した検索を可能とすること。
【解決手段】検索対象情報抽出部31により、入力されたテキストの集合から感性表現を抽出し、抽出した感性表現を検索対象に結び付け、感性情報生成部32により、結び付けられた検索対象と感性表現とを入力とし、感性表現に対する感性情報および当該感性表現が属する側面情報を少なくとも格納した感性表現DB1を用いて検索対象に対する側面情報毎の感性情報を生成し、検索対象DB2に格納することで、検索条件として入力された感性表現が属する側面についての感性検索を可能とし、全く異なる側面に関するイメージがノイズとなることを避け、検索精度を向上できる。
(もっと読む)
1 - 20 / 92
[ Back to top ]