
Fターム[5B075UU06]の内容
検索装置 (67,127) | 用途 (6,943) | 文書管理装置(ワープロなど) (1,105) | 文書ファイル (854)
Fターム[5B075UU06]に分類される特許
41 - 60 / 854
文書管理装置及び文書管理プログラム
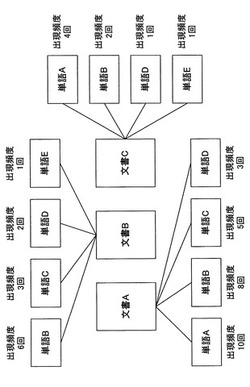
【課題】どのようなキーワードで検索すればよいのか分からない場合であっても、所望の文書を効率よく検索することができる技術を提供する。
【解決手段】画像形成装置は、ボックス部に各文書データ(文書A,文書B,文書C)を記憶する際に、各文書データに含まれる単語を抽出し、抽出した単語のうち各文書データにおける出現頻度の高い上位数個の単語をキーワードとして選択し、そのキーワードを各文書データに関連付けて記憶しておく。文書データを検索する際には、全ての文書データ(文書A,文書B,文書C)における出現頻度の高い上位数個のキーワードを表示する(単語B;16回、単語A;14回、単語C;8回)。表示されたキーワードのいずれかをユーザが選択することにより、選択されたキーワードに関連付けられた文書データが検索される。これらの表示処理、選択処理、検索処理を繰り返すことにより、文書データの絞り込み検索が行えるようになる。
(もっと読む)
電子書籍分析装置及び方法及びプログラム

【課題】 多くの電子書籍の各ページの重要度を効率的に判定する。
【解決手段】 本発明は、電子書籍閲覧者による閲覧行動情報をクライアント端末から収集し、閲覧行動情報を集計して、各ページが閲覧されていた時間の長さに基づいて該ページの重要度を判定し、重要度判定結果を出力する。ページ重要度の判定する際に、閲覧時間の長さのみならず、閲覧行動情報(ページ履歴)により、閲覧された回数、閲覧時間の総和、閲覧時間の総和を文字数で除した値のいずれか、または、組み合わせたものをページ重要度とする。
(もっと読む)
特許検索装置、特許検索方法、およびプログラム
【課題】適切な特許検索式を用いた検索が容易に可能な特許検索装置を提供する。
【解決手段】検索式受付部103が受け付けた特許検索式のキーワードと一致する用語と対応付けられた関連用語を関連用語情報から検索する関連用語検索部104と、検索結果に応じて特許検索式を修正するか否かを判断する修正判断部106と、修正すると判断した場合に、各キーワードと一致する用語と対応する関連用語を候補キーワードとして取得する候補キーワード取得部107と、指定指示受付部111が受け付けた指定指示で指定された候補キーワードで特許検索式を修正する特許検索式修正部112と、修正判断部106が修正すると判断した場合は修正した特許検索式を用いて特許公報の検索を行い、修正しないと判断した場合には検索式受付部103が受け付けた特許検索式で検索を行い検索結果を出力する検索部113とを備えた。
(もっと読む)
テストデータの作成装置
【課題】文書ファイルの検索システムの検証のために用いられるテストデータを、安価に且つ柔軟に、大量に作成する。
【解決手段】テストデータ作成装置は、所謂モンテカルロ法を基づいて、複数の単語を含む多数の文書ファイルに相当するテストデータ、つまり単語頻度及び文書頻度を含むデータを大量に作成する処理を行う。模擬的な文書1〜1000と、模擬的な単語a、単語b、単語cが設定され、各々の単語について、単語頻度の合計値がテーブル61の領域61Aに設定される。この単語頻度の合計値をベースとして、擬似乱数を用いてモンテカルロ法により、各単語についての各々の文書における単語頻度と、各単語の文書頻度とが求められる。
(もっと読む)
文書検索装置及び文書検索システム及びコンピュータプログラム及び文書検索方法
【課題】大量の文書データのなかから検索した文書データについて、適切な評価値を算出し、利用者が望む文書を迅速に発見できるようにする。
【解決手段】検索キーワード入力部121は、検索キーワードを入力する。文書検索部122は、文書記憶装置が記憶した複数の文書データそれぞれについて、検索キーワードが出現する出現位置を算出する。評価値算出部124は、文書データの先頭から文書検索部122が算出した出現位置までの長さを文書データ全体の長さで割った商を算出して比出現位置とし、算出した比出現位置に基づいて、上記文書データの評価値を算出する。
(もっと読む)
文書比較処理装置及び文書比較処理プログラム
【課題】文書情報の内容の整合性を複数の文書情報の比較結果から検出する文書比較処理装置及び文書比較処理プログラムを提供する。
【解決手段】文書比較処理装置1は、文書情報を文書形式毎に分類する文書形式分類手段100と、同一形式の文書情報間で位置及び内容が共通する文字列を形式テンプレート情報111として抽出する形式テンプレート抽出手段102と、同一案件に含まれる文書情報で共通する文字列を位置とともに共通値情報112として抽出する案件共通値抽出手段103と、案件の文書情報から共通値情報112に含まれる文字列を除いて入力欄とした案件テンプレート情報113を抽出する案件テンプレート抽出手段105と、誤り検出の対象となる文書情報において、案件テンプレート情報113の入力欄に対応する内容を共通値情報112に当てはめて互いに異なる内容となる文字列を検出する誤り検出手段106とを有する。
(もっと読む)
書籍情報検索装置、書籍情報検索システム、書籍情報検索方法及びプログラム
【課題】知識が全くない分野に関する書籍を精度良く検索する。
【解決手段】索引語のグループ化処理(S101)では、書籍情報データベースから書籍データを順次読み込み、見出しごとに、当該見出しに対応するページ範囲に入る出現ページに係る索引語を抽出し、抽出された複数の索引語を索引グループとしてグループ化する。関連度算出処理(S102)では、索引データから任意の索引語を2つずつ順次読み込み、索引グループによって示される索引語の共起情報に基づいて、読み込まれた2つの索引語の関連度合を示す関連度スコアを算出する。追加キーワード提示処理(S104)では、関連語データベースを検索することで、入力キーワードと一致する第1関連語又は第2関連語を抽出し、関連度スコアに基づいて、抽出された第1関連語又は第2関連語の中から入力キーワードに対する追加キーワードを提示する。
(もっと読む)
局所対応抽出装置及び局所対応抽出方法
【課題】本発明は、事前にインデックス化されてない任意の文字列の間で代表的な局所対応を網羅的に抽出する局所対応抽出装置を提供することを目的とする。
【解決手段】任意の二つの文書間で類似する文字列である局所対応を抽出する局所対応抽出部を備える局所対応抽出装置において、遷移元セルに対応する第二行列のセルがいずれかの局所対応に属することを示し、かつ、第一行列生成部によって算出された最大のスコアが所定値よりも大きい場合、算出されたスコアが同じ局所対応に属するセルの最大のスコアよりも大きい場合、算出対象のセルに対応する二つの文字が局所対応の終点となることを記憶することを特徴とする。
(もっと読む)
情報検索装置、情報検索方法及び情報検索プログラム
【課題】検索条件により文書集合が限定された場合でも、スコア算出時に高速にこれら値を取得し、検索語に対する各文書のスコアの出力を行うこと。
【解決手段】本発明における情報検索装置は、1以上の検索語と分類キーとを含む検索条件を入力する検索条件入力手段と、分類キー毎に検索対象の文書の母集団が対応付けられるとともに、母集団内の文書格納数値と文書の平均文書長値と、複数の検索対象の文書内のワード毎に当該ワードを含む文書頻度値とが算出され格納された索引情報を記憶した記憶手段と、分類キーに対応付けされた母集団の文書格納数値及び平均文書長値と、分類キーに対応付けられた母集団内の文書のうち、検索語と一致するワードを含む当該母集団の文書頻度値とを取得し、取得した値に基づいて当該母集団内の文書毎の適合度を算出し文書を検索する検索手段と、文書に適合度を付して出力する検索結果出力手段とを有する。
(もっと読む)
検索用索引自動生成装置を有するファイル検索システム
【課題】ファイルサーバから目的のファイルを検索する際、利用者がその都度有効な検索条件を試行錯誤したり、管理者が分類構造を事前に用意するといった手間を省き、より高い精度でのファイル取得を可能にする。
【解決手段】ファイルの位置情報を保管するデータベースとともに、データベースに問い合わせファイル検索を実行する検索サーバ内に、社内ファイル検索用索引の自動生成装置を設け、利用者がPCから指定した検索条件の検索回数と利用者IDを記録し、事前に管理者が検索サーバに設定した有効回数を超えた場合に、当該検索条件を索引として利用者PCのWebブラウザ上に分類構造で表示する。
(もっと読む)
ファイル履歴情報管理サーバ、ファイル履歴情報管理プログラム、ファイル出力装置、ファイル出力プログラム、ファイル履歴情報管理システム及びファイル履歴情報の管理方法
【課題】 履歴情報に容易にアクセスできるとともにデータのバックアップにも有効であり、かつ利用環境の制約を受けにくい、ファイルに対して実行された操作の履歴情報の管理に用いられファイル履歴情報管理サーバ等を提供する。
【解決手段】 ファイルサーバに保存され、ファイルサーバに履歴情報が記録されているファイルに対し、端末装置を操作するユーザが印刷命令を実行した際に、この印刷命令に対してサーバで新たなURL等の記憶領域を割り当て、割り当てた記憶領域に印刷命令までの履歴情報を書き込んで保存する。さらに、ファイルサーバは割り当てたURLを識別するための二次元コードを発行してユーザ端末に送信し、ユーザ端末では印刷する文書等に二次元コードを埋め込むことによって、プリンタから印刷された文書の二次元コードを読み取るだけで、印刷までの履歴情報にダイレクトにアクセスすることを可能にしている。
(もっと読む)
文書検索装置、文書検索方法および文書検索プログラム
【課題】状況に応じて話題になっている事物に関する文書を高速に検索することを可能とした文書検索装置を提供する。
【解決手段】入力された文書中に含まれる場所または日時などの状況を解析する状況解析部1と、前記状況を含む検索インデクスを作成する検索インデクス作成部2と、前記各状況における文書から、状況との距離に基づいて特徴語を抽出する特徴語抽出部3と、文書検索時に入力された状況から前記抽出された特徴語を検索するための特徴語インデクスを作成する特徴語インデクス作成部4と、ユーザから指定された状況を入力する状況入力部5と、前記特徴語インデクスを参照して、前記入力された状況に関する特徴語を選択する特徴語提示部6および特徴語入力部7と、前記検索インデクスを参照して、前記入力された状況と前記選択された特徴語に関連する文書を検索する検索結果取得部8と、を備える。
(もっと読む)
文書データ管理装置およびプログラム
【課題】それぞれが文書データに対応する複数の識別画像(アイコン)のうち、基準識別画像の表示位置と、検索対象識別画像の表示位置とに関する情報を検索条件として文書データの検索処理を行う文書データ管理装置およびプログラムを提供する。
【解決手段】それぞれが複数の文書データの1つに対応するアイコン(識別画像)を表示部200において表示させる文書データ管理装置100は、アイコンの表示位置に基づく位置情報を生成する位置情報生成部126と、アイコンの1つを基準アイコンとして指定する基準アイコン指定情報と検索対象アイコンの表示範囲を基準アイコンの表示位置に基づいて指定する表示範囲条件とを含む検索条件を取得する検索条件取得部128、位置情報から、基準アイコンを除くアイコンについて基準アイコンに対する該アイコンの配置を示す配置情報を生成し、配置情報が表示範囲条件に合致するアイコンを検索する検索部130を有する。
(もっと読む)
文書処理装置、文書処理方法、及び、プログラム
【課題】記憶装置に記憶させるデータ量を削減しながら、インデックス情報を迅速に生成することが可能な文書処理装置を提供すること。
【解決手段】文書処理装置100は、文書を表す複数の文書データを受け付ける文書データ受付部101と、上記受け付けられた文書データが表す文書に含まれるすべての単語のそれぞれに対して、当該単語と、当該単語が出現する文書を識別するための文書識別情報と、当該単語が当該文書にて出現する位置を表す位置情報と、を対応付けたインデックス情報を記憶装置STに記憶させるインデックス情報記憶処理部102と、上記記憶されているインデックス情報に基づいて、上記文書の少なくとも一部を復元する文書復元部103と、を備える。
(もっと読む)
まとめ上げ作業支援装置、方法及びプログラム
【課題】まとめ上げ作業を効率的に行うことを可能にする。
【解決手段】本装置は、作業対象の集合についてまとめるべき特徴語句である第1特徴語句の指示を受け付け、第1特徴語句を含む文書の件数である第1文書数を計数し、集合毎に当該集合についてのまとめるべき特徴語句として指示されている特徴語句を含む文書の文書数を格納する記憶部において作業対象の集合についての文書数を第1文書数で更新する計数部と、集合を文書数の多い順に並べた場合における作業対象の集合の1つ上位の集合についての文書数と第1文書数との差分を計算する差分計算部と、上記差分を基に、作業対象の集合について新たにまとめるべき第2特徴語句を含む次の指示を受けても1つ上位の集合との順位が入れ替わらないという条件が満たされているか判断する判定部と、条件が満たされている場合、作業対象の集合より下位の集合のうちいずれかを新たな作業対象として提示する出力部とを有する。
(もっと読む)
文書検索装置、文書検索方法及び文書検索プログラム
【課題】状況情報に基づき話題になっている事物に関する文書を検索する。
【解決手段】文書検索装置100において、状況関連文書検索部4は状況情報の入力を受けると予め取得した文書に含まれる状況情報を当該文書と関連付けて格納した検索インデクス10を参照して当該入力された状況情報に関連する状況関連文書を検索する。特徴語取得部5は前記状況関連文書から特徴語を取得する。特徴語スコア付与部6は前記特徴語と当該特徴語を含んだ状況関連文書に含まれている状況情報との距離に基づいて当該特徴語に対してスコアを付与する。特徴語提示部7は前記特徴語のスコアの値に基づき複数の特徴語を提示する。特徴語入力部8は前記提示された複数の特徴語から選択された一つまたは複数の特徴語を検索結果提示部9に入力する。検索結果提示部9は特徴語入力部8から供された一つまたは複数の特徴語を含む状況関連文書を提示する。
(もっと読む)
画像処理方法、画像処理装置、およびプログラム
【課題】画像中のメインの被写体である代表文字列領域に対して、代表文字列領域以外の文字列情報を欠落させずに再利用する。
【解決手段】代表文字列領域抽出手段が、入力された画像から当該画像の中央に位置し、所定の大きさを有する文字領域である代表文字列領域を抽出する代表文字列領域抽出工程と、非代表文字列領域抽出手段が、入力された前記画像において、前記代表文字列領域の外にある文字領域である非代表文字列領域を抽出する非代表文字列領域抽出工程と、関連付け手段が、前記非代表文字列領域抽出工程において抽出された前記非代表文字列領域それぞれを、前記非代表文字列領域と前記代表文字列領域のそれぞれの消失点の位置関係に基づいて、前記代表文字列領域に関連付ける関連付け工程と、保持手段が、前記関連付け工程において関連付けられた前記代表文字列領域と前記非代表文字列領域の情報を保持する保持工程とを有する。
(もっと読む)
検索サービス装置及び検索サービス方法
【課題】特定のサイト内に現われるキーワードに絞って連想したサジェストを行うことを行い、そのサイトに特化したサジェストを行う利点を生かして迅速に適切な検索を行い得るようにする。
【解決手段】形態素解析手段を用いて、前記文書データの文章から、サジェストキーワード候補を値として抽出し、サジェストキーワード候補が出現する出現ページ数の多いサジェストキーワード候補を上位として選定してサジェストキーワードとし、キーワード抽出結果ファイルが、検索キーワード、WebページのURIとタイトルを備えたサジェストキーワードとサジェストキーワードがそのWebページの文書データに出現する回数を組みとしてファイルする。
(もっと読む)
重要日時表現判定方法、重要日時表現判定装置、重要日時表現判定プログラム
【課題】様々な形式で記述された日時表現に対して文書の内容に関連する重要な日時表現か否かを判定可能とする。
【解決手段】入力された電子文書を文に分割し(S201)、分割された各文を単語に分割する(S202)。日時表現に該当する単語列のパターンが記述された日時表現辞書を参照して、入力された電子文書を構成する各文の単語列パターンから日時表現を特定する(S203)。日時表現の表記パターン、該日時表現の前後に出現する単語、該日時表現の文書中での出現位置に基づき該日時表現の文脈中の用いられ方を表す日時表現文脈ベクトルを求める(S204)。日時表現文脈ベクトルを、事前の学習で作成した日時表現の重要・不要を判定するための重要日時表現判定モデルに応じて分類し、日時表現が重要か否かを判定する(S205)。
(もっと読む)
コンテンツ検索装置及び方法及びプログラム
【課題】 コンテンツを関連付ける対象領域を設定することなく、低コストでドキュメントの特定位置とコンテンツとを関連付ける。
【解決手段】 本発明は、ドキュメントから、文字ブロックを抽出し、文字ブロックと該文字ブロックが出現するドキュメントにおけるページ識別子とページ内座標を関連付けてインデックスDBに出力する。入力された検索クエリ(ドキュメント内の一部領域)から抽出したクエリ文字ブロックに基づいてインデックスDBを検索し、検索結果をページ毎に集計し、最も多くの文字ブロックが検索されたページをヒットページとし、ヒットページ内で検索された文字ブロックのページ内座標の重心を算出し、ページ内ヒット位置とし、算出されたヒットページとページ内ヒット位置をクエリとして、ページ内ヒット位置の近傍のページ位置が関連付けられたコンテンツをコンテンツDBから検索する。
(もっと読む)
41 - 60 / 854
[ Back to top ]