
Fターム[5B075UU06]の内容
検索装置 (67,127) | 用途 (6,943) | 文書管理装置(ワープロなど) (1,105) | 文書ファイル (854)
Fターム[5B075UU06]に分類される特許
81 - 100 / 854
クラスタリング装置、クラスタリング方法及びクラスタリングプログラム
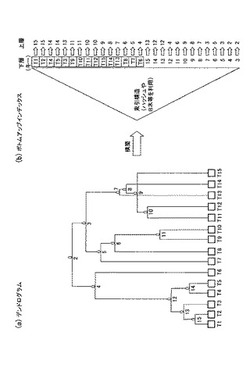
【課題】タグの再利用時において、タグの曖昧性を解消し、タグ数の爆発を防止すること。
【解決手段】全体タグ集合に対して階層的クラスタリングを行ってデンドログラムを構築し、下層から上層を特定可能にするボトムアップなインデックスを事前に生成しておき、上位アプリケーションから要求があった際に、生成されたインデックスを参照して全体タグ集合を複数の部分タグ集合にクラスタリングする。
(もっと読む)
類似文書検索装置

【課題】文書検索を行うに際して、検索文字列に聞き間違いや記憶違い等に起因する部分的誤りが含まれる場合であっても、複数の文書から目的の文書の検索を高速かつ高精度に実現できる類似文書検索装置を得る。
【解決手段】多数の音節から所望の数を繋げた組み合わせで形成される音節N-Gram間の距離に基づいてクラスタリングして複数の音節列クラスタとして登録し、音節列クラスタと検索対象文書との類似度のテーブルを検索用INDEXとして予め作成する検索用INDEX作成手段12と、検索文字列から音節列をサブワード連鎖として抽出するサブワード連鎖抽出手段13と、前記各サブワード連鎖が属する音節列クラスタに対応する類似度を検索用INDEXから求め各検索対象文書に対する類似度を演算する類似度演算手段14と、前記類似度に基づいた文書データの検索結果を出力する出力インタフェース3とを備える。
(もっと読む)
キーワード提示装置、方法及びプログラム
【課題】 本発明の目的は、閲覧文書から類似するキーワードを集約し提示するキーワード提示装置を提供することである。
【解決手段】 閲覧文書から複数のキーワードを抽出する抽出部と、複数の前記キーワードの中で互いに表記が類似するキーワード毎にまとめて、複数の類似キーワード群を得る判別部と、前記類似キーワード群毎に、見出しとなる主キーワードと、それ以外の従キーワードとに分類し、前記従キーワードを前記主キーワードに集約する集約部と、前記主キーワードを提示する提示部とを備えるキーワード提示装置。
(もっと読む)
文書推薦システム、文書推薦装置、文書推薦方法、及びプログラム
【課題】 ユーザの知識レベルに適合した書籍や文書を推薦する文書推薦システム等を提供する。
【解決手段】 ユーザ端末2が、既読文書に対して理解度及び有益度の評価を付与して文書推薦サーバ5に登録すると、文書推薦サーバ5は、全ユーザから登録された文書リスト53aから有益度が比較的高い文書を抽出するとともに、理解度レベル別に平易有益文書55と難解有益文書57を抽出する。文書推薦サーバ5は、各ユーザの文書リスト53aからユーザ別のユーザプロファイル53b、すなわち個々のユーザの苦手分野文書と得意分野文書を表現する検索クエリを作成する。そして、文書推薦サーバ5は、苦手分野文書検索クエリ53dを用いて平易有益文書55を検索し、苦手分野として推薦すべき文書を決定して、ユーザ端末2に提示する。同様に、得意分野として推薦すべき文書を決定してユーザ端末2に提示する。
(もっと読む)
複合語に対する文書数予測装置及び方法及びプログラム
【課題】 少ないコストで文書数を予測でき、また、一部の文書群から検出した複合語を含む文書数を基に、文書数を予測する場合に、一般的な手段での予測文書数よりも精度良く予測する。
【解決手段】 本発明は、ユーザから入力されたクエリが複合語の場合に複合語を単一の単語に分割し、分割された単語に基づいて転置インデックス記憶手段を参照して、分割した単語それぞれに対する転置インデックスを抽出し、予め設定した文書数を対象として、抽出された転置インデックスから抽出した複合語を含む文書数を算出し、検出した複合語を含む文書数と転置インデックス取得ステップで取得した各単語を含む文書数に基づいて、文書数予測ルールを用いて全文書に対する複合語を含む文書数の予測値を算出する。
(もっと読む)
特徴語抽出装置及びプログラム
【課題】 事前に定義された属性に限らずに分析軸の候補として特徴語を設定できると共に、着目すべき比較範囲の絞り込みや、着目すべき特徴語の参照を支援できる。
【解決手段】 特徴語抽出装置においては、カテゴリIDに関連付けられた文書IDの個数を含むカテゴリ個数データの提示中に、選択を受け付けたカテゴリ個数データのカテゴリIDに関連したカテゴリ特徴語のうち、特徴度が上位のカテゴリ特徴語における文書特徴語をカテゴリ特徴語として提示する。また、カテゴリ個数データの提示中、複数個のカテゴリ個数データの各カテゴリIDの和集合からなる複数の比較対象からなる比較対象集合の選択を受け付けると、当該比較対象集合内の各文書IDに関連した文書特徴語と、文書記憶部10内の各文書とに基づいて当該文書特徴語の相違特徴度を算出し、相違特徴度が上位の文書特徴語をカテゴリ相違特徴語として提示する。
(もっと読む)
文書検索装置及び方法及びプログラム
【課題】 検索装置が単位時間あたりに処理できる検索要求数を向上させる。
【解決手段】 本発明は、文書が更新されると転置インデックスも更新される。このとき、文書の更新に合わせて当該文書中の単語毎に更新時刻ntを単語−最新時刻DBに保持しておき、キャッシュ(スコアキャッシュDB)には検索語毎に前回の利用時刻tcを保持しておき、検索時には、単語毎の更新時刻ntと前回の利用時刻tcとを比較して、更新時刻ntが古ければキャッシュ情報をそのまま利用してスコアキャッシュDBに格納されている文書IDをスコアの高い順に出力する。
(もっと読む)
情報検索装置及び方法及びプログラム
【課題】 検索実行時に検索結果の表示に遅延を生じることなく、検索語の同義語を考慮した高精度の検索結果を出力する。
【解決手段】 本発明は、検索範囲を解析し、単語毎に各電子文書内での出現頻度等の情報(以下単語頻度情報)と、当該単語の含まれる同義語IDの情報を合わせて当該単語のレコードとして集約した単語インデックスを作成し、単語インデックスの単語毎の単語頻度情報を同義語ID毎に集約した同義語インデックスを作成し、検索語をキーとして単語インデックスを参照して得られた同義語IDをキーとして同義語インデックスを参照し、取得した単語頻度情報を用いて検索語との一致度を算出する。
(もっと読む)
文書分類方法、文書分類装置、およびプログラム
【課題】文書分類方式として一般的なKNN法において、適合率を維持しつつ再現率を向上させ、利用者が所望する数の分類を出力可能とする。
【解決手段】K件の類似文書に付与された分類の各々について、分類が付与された類似文書の類似度の総和を算出し、総和値の高い分類を特定する。次に、類似文書に付与された分類から上記特定された分類を除外し、除外した結果付与された分類数が0個になった類似文書を除外し、残った類似文書の中からK件の類似文書を特定し、分類を特定するという処理を繰り返す。
(もっと読む)
情報処理装置、情報処理方法およびプログラム
【課題】予め登録された複数の文書情報を含む事例情報を、複数の文書情報の内容に応じ
て適切なグループに分類すること。
【解決手段】各々に重要度が定められた複数の文書情報を含む事例情報を記憶する事例記
憶装置から事例情報を取得する取得手段と、事例情報が分類される複数のグループの各々
に対応したキーワードを記憶するキーワード記憶手段と、事例情報に含まれる文書情報を
解析して、各キーワードに対応する情報を文書情報の各々から抽出する抽出手段と、文書
情報の各々から抽出した情報と文書情報の各々に定められた重要度とに応じて、事例情報
に対応するキーワードを特定する特定手段と、取得手段によって取得された事例情報を、
特定手段によって特定されたキーワードに対応するグループに分類する分類手段とを具備
する。
(もっと読む)
要素列の近似的な照合又は検索及びその方法を実行するためのプログラムを格納した記録媒体
【課題】 オートマトンを変形した構成とすることで、文章の要素列と複数の辞書語の要素列を効率的に実行することが可能な近似的な照合又は検索方法に関する。
【解決手段】 オートマトンの遷移ルールが付与された辞書語の要素列を登録するための工程と、近似的な照合又は検索を行うための、エラー値の上限値を設定するための工程と、照合対象となる文章の要素列を入力するための工程と、遷移ルールが付与された辞書語の要素及びエラー値の上限値に基づき、第1の命令手順及び第2の命令手順によって、辞書語の要素と文章の要素列において照合対象となった部分文字列の要素とを照合し、辞書語の最後に照合を行った要素の位置情報pと、照合の不一致のエラー値eの内部的変数の組を生成する工程と、生成された内部的変数の組を記憶する工程と、内部的変数の組をもとに、照合結果を出力する工程を有する要素列の近似的な照合又は検索方法である。
(もっと読む)
感情極性推定装置、感情極性推定方法及び感情極性推定処理プログラム
【課題】テキスト全体または1文に書かれている言語表現の感情極性の自動推定を高精度に行う。
【解決手段】推定すべき性質を示す述語間の関係を記述した論理式を感情極性の推定に用いる論理式として保存し、上記論理式により構築されるマルコフ論理ネットワークにより、1文感情極性とテキスト全体の感情極性を同時に推定するための感情極性推定用論理式の重みを学習するための学習コーパスデータを学習コーパスデータ保存手段に保存された学習コーパスデータを用いて、上記マルコフ論理ネットワークについて、1文感情極性とテキスト全体の感情極性を同時に推定するための感情極性推定用論理式の重みを学習処理モジュールにより学習し、得られた上記感情極性推定用論理式の重みデータを保存し、保存されたテキストデータについて、保存された感情極性推定用論理式の重みデータを用いて、1文感情極性とテキスト全体の感情極性を同時に推定する。
(もっと読む)
情報処理装置及びプログラム
【課題】利用者による操作が行われる時期に基づく情報管理を効率化できる情報処理装置及びプログラムを提供する。
【解決手段】操作受付部32が、利用者から操作対象情報に対する操作を受け付ける。関連付け部36が、操作に応じた処理の実行の際に、この操作の時期に対応する時期対応情報が操作対象情報に関連付けられていない場合に、時期対応情報を生成して操作対象情報に関連付ける。
(もっと読む)
文書間距離算出器および文章検索器
【課題】従来、文書間や検索時の文書と検索キー間の類似度は、文章中の単語の共起に基づき算出されるが、複数主題の文章で関連ない単語同士の共起がある場合、正しい類似度が求められず、又同義語や異なる言い回しの文章の類似度を精度よく算出できず、さらに、文章構造の類似性に従った似通った文章の分類ができない。
【解決手段】文書入力手段からの文書の文字列を構文解析手段で形態素解析および係り受け解析し、その構文解析結果から統語情報付き木構造作成手段で統語情報付き木構造を作成し、統語情報付き木構造の並列関係にあるノードを子ノードとした並列ノードを並列ノード追加手段で統語情報付き木構造に追加し、並列ノード順序付けする手段で追加並列ノード下のノードを順序付けし、その統語情報付き木構造を他文書の統語情報付き木構造に編集し、その編集距離を距離計算手段で算出する。
(もっと読む)
文書検索装置、文書検索方法、文書検索プログラム
【課題】ユーザ希望の専門性や難易度に沿った検索結果を提示する。
【解決手段】事前準備段階では、文書集合Sに基づき文書索引作成部4が文書索引を作成し、DB6に保存する。つぎにDB6の保存データに基づき説明スコア算出手段5が、文書集合Sの各電子文書に含まれる各単語間の説明関係に基づき被説明単語に対する説明単語の説明スコアを算出してDB7に保存する。検索処理段階では、文書集合特定部9が、DB6の文書索引を検索し、検索語を含む文書集合を特定する。つぎに文書専門度推定部10が、DB7に保存された説明単語の説明スコアと、DB8に事前に保存された説明単語の専門度と、説明単語の出現回数との乗算和に基づき専門度の推定値を算出する。その後にスコア決定手段11が、ユーザ入力の要求専門度の値に対する前記推定値を、検索語を含む電子文書のランキングスコアに反映させる。
(もっと読む)
特徴語抽出装置、特徴語抽出方法および特徴語抽出プログラム
【課題】特定のカテゴリに対応する適切な特徴語を効率的に抽出する。
【解決手段】複数の文書データに含まれる単語対が共起する文書データの数を示す第1の出現頻度と、指定カテゴリが対応付けられた複数の文書データのうち、単語対が共起する文書データの数を示す第2の出現頻度とを算出し、第2の出現頻度から第1の出現頻度を除算した値を共起度として算出し、単語をノードとし、共起度をエッジとしたネットワークデータをN×Nの対称行列である行列データとして生成し、生成した行列データの最大固有値を凝集度として算出し、算出した凝集度に対応する固有ベクトルから定められる複数の単語の集合であるクラスタを抽出し、単語毎のクラスタに対する帰属度を算出し、閾値を超える帰属度をもつ複数のノードを指定カテゴリの特徴を表す特徴語として抽出する。
(もっと読む)
類似度計算装置、類似度計算方法および類似度計算プログラム
【課題】単語や文字が持つ意味の極性に関する情報を別途定量化して類似度計算に反映させることが可能な類似度計算装置を提供する。
【解決手段】文書を入力する文書入力部1と、入力された文書を形態素解析して単語に分割し、文法情報等を付与する形態素解析部2と、前記形態素解析結果に対して極性を付与する極性付与部3と、前記形態素解析結果と前記極性付与結果をもとに、入力文書の概念情報を抽出する概念情報抽出部4と、前記抽出された概念情報と、あらかじめ用意された文書データベース8中の文書に関する概念情報をもとに、入力文書と文書データベース8中の文書との類似度を計算し、類似度の高い文書を前記文書データベース8から取得する類似度計算部5と、前記計算された類似度に従って、前記文書データベース8から取得された文書を順序付けて出力する計算結果出力部6と、を備える。
(もっと読む)
文書検索システム及び文書活用度評価システム
【課題】ユーザが望む文書を的確に抽出することができる文書検索方法を提供する。
【解決手段】データ処理装置30は、文書データベースに格納されている文書ファイル単位で付与される重みを導出する文書重み作成部32を備える。文書重み作成部32は、各文書ファイルについての文書重みの設定にあたり、文書データベース10に蓄積された文書ファイル間の類似度をそれぞれ算出する処理、一の注目文書ファイルを順次定め、閲覧・登録履歴データに基づいて、前記注目文書ファイルを起点とする文書ファイルの参照経路を推定する処理、文書ファイル間の類似度を参照し、注目文書ファイルと前記作成系譜上にある文書ファイルとの間の各々の類似度を合算して、注目文書ファイルの活用度に関する評価値を導出する処理、を実行する。
(もっと読む)
文字列管理装置、文字列登録方法、文字列検索方法および文字列管理プログラム
【課題】検索時における異体字の表記ゆれを許容できるようにする。
【解決手段】文字列管理装置1は、異体字とこれを代表する見做し文字とを定義した見做し文字定義体2と、データベース3と、登録対象の文字列pに異体字があれば、文字列pと見做し文字mとをセットにした登録文字列rを生成する登録文字列生成部4とを備え、さらに、検索用の文字列sの異体字を見做し文字mで正規化した検索条件f1を生成する検索条件生成部5と、検索時に登録文字列rの異体字をその見做し文字mで正規化した被検索文字列f2を生成する被検索文字列抽出部6と、検索条件f1と被検索文字列f2とを比較する比較部7と、比較の結果、一致した場合に登録文字列rがセットで持つ文字列pを返却文字列oとして取得し、その返却文字列oを検索元へ返却する返却文字列取得部8とを備えている。
(もっと読む)
カテゴリ主題語句抽出装置及び階層的タグ付与装置及び方法及びプログラム及びコンピュータ読み取り可能な記録媒体
【課題】 予めカテゴリ分けされた文書群からカテゴリの主題を示す語句を抽出し、抽出された語句を利用して文書に対して階層的なタグを付与する。
【解決手段】 本発明は、本文とタイトルで出現割合が異なる語句をカテゴリの主題として抽出し、カテゴリの主題を示す語句と、各文書のカテゴリとカテゴリの主題はカテゴリが上位、カテゴリの主題が下位の階層関係であることから、文書がどのカテゴリに属するのかの尤もらしさを示すカテゴリタグスコアと、そのカテゴリに属する文書の主題の語句が、今着目している文書に対して適切かどうかを示すカテゴリ主題タグスコアを求め、これらのスコアの組み合わせの中から適切なものを抽出し、抽出した組み合わせに対応するカテゴリとカテゴリ主題語句を階層的にタグとして文書に付与する。
(もっと読む)
81 - 100 / 854
[ Back to top ]