
Fターム[5B091CC00]の内容
機械翻訳 (6,566) | 辞書、知識ベース (865)
Fターム[5B091CC00]の下位に属するFターム
Fターム[5B091CC00]に分類される特許
1 - 8 / 8
翻訳システム
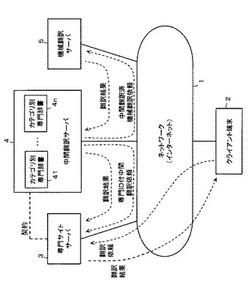
【課題】汎用の機械翻訳を用いる場合においても、使用者は、翻訳依頼をするだけで、より高精度の翻訳結果を得られるようにした翻訳システムを提供する。
【解決手段】汎用の機械翻訳用辞書を用いて機械翻訳を実行する機械翻訳実行手段5と、第1の言語による特定の専門用途に関する翻訳対象文を、第1の言語とは異なる第2の言語に翻訳する翻訳依頼を受け付ける翻訳依頼受付手段と、翻訳依頼受付手段で受け付けた翻訳依頼に基づき、第1の言語による翻訳対象文を解析し、特定の専門用途における第1の言語の語を第2の言語の語に変換するための専門辞書により変換可能な語のみを第2の言語の語に変換する中間翻訳を実行して中間翻訳結果を得、その中間翻訳結果を機械翻訳実行手段5に渡す中間翻訳実行手段を備える。機械翻訳実行手段で中間翻訳結果について機械翻訳が実行されて得られた機械翻訳結果を翻訳依頼に応じた翻訳結果とする。
(もっと読む)
用語の対応を見出す方法、プログラム及びシステム

【課題】 ランダムウォークの技法を用いて、多数の用語を対象としても妥当な計算量で異言語の単語集合を列挙することが可能な技法を提供すること。
【解決手段】 第1の言語(例えば日本語)の専門用語集合と、第1の言語の一般用語集合と、第2の言語(例えば英語)の専門用語集合と、第2の言語の一般用語集合とを生成する。次に、第1の言語と第2の言語それぞれにおいて、同一言語の専門用語集合と一般用語集合の間に、コーパスの情報に基づきリンクで結び、2部グラフを生成する。次に、異なる言語の一般用語の対訳辞書(例えば、英和辞書)で一般用語間のリンクを生成し、異なる言語の一般用語間で2部グラフを連結する。次に、同一言語内、及び異なる言語間の2部グラフのリンクの重み付けされた情報に基づき、関連度行列Mを生成する。次に、Q=(1-c)(I-cM)-1という、類似度行列Qを計算する。
(もっと読む)
機械翻訳装置、機械翻訳方法および機械翻訳プログラム
【課題】
利用者の現在の利用シーンに対応する適応モデルをオンラインで動的に生成する機械翻訳装置を実現することである。
【解決手段】
実施形態の機械翻訳装置は、第1言語を入力する言語入力手段と、前記言語入力手段に入力された第1言語の利用者もしくは利用場所に関する付加情報を取得する付加情報取得手段と、第2言語と当該第2言語を取得した際の利用者もしくは利用場所に関する付加情報を対応付けた第2言語の参照データを格納する参照データ格納手段と、前記付加情報取得手段で取得された第1言語の付加情報の全部あるいは一部と同一な内容の付加情報を有する第2言語のテキスト情報を取得するテキスト情報取得手段と、前記テキスト情報取得手段によって取得された第2言語のテキスト情報を利用して、前記言語入力手段に入力された第1言語を第2言語に翻訳する翻訳手段とを備える。
(もっと読む)
例文帳作成装置及び例文帳作成プログラム
【課題】単語学習用の例文帳を容易に作成する。
【解決手段】電子辞書1は、表示部40と、複数の文章を記憶する例文データベース85と、ユーザ操作に基づいて複数の単語を蓄積記憶する単語帳テーブル86と、単語帳テーブル86に記憶された単語を複数含む文章を、これら複数の単語の例文として例文データベース85から検索するCPU20と、検索された例文を蓄積記憶する例文帳テーブル87とを備える。CPU20は、ユーザ操作に基づいて、例文帳テーブル87に記憶された例文を表示部40に表示させる。
(もっと読む)
表示制御装置及びプログラム
【課題】ヒストリ機能や単語帳機能といった各種機能で単語が登録された場合、ユーザがその登録単語を実際の文章中で適切に理解できるようにすること。
【解決手段】表示制御装置において、ユーザがいずれかの英語テキストを指定すると、指定の英語テキストと対訳の日本語テキストとが表示される。ユーザが、英語テキスト中の英単語を単語帳登録した後、いずれかの英語テキストを指定すると、単語帳に登録された英単語のと同じ英単語が、その英語テキスト中に検知されると、対訳の日本語テキストを表示する際、検知された英単語に対応する翻訳部分がその英単語に置き換えられて表示される。
(もっと読む)
校正支援装置及び校正支援プログラム
【課題】文書に対してなされた校正における校正規則を、校正前文書及び校正後文書から自動抽出できるようにする。
【解決手段】文書読出部15が校正前文書7及び校正後文書8を読み出し、文書解析部16がこれを解析して要素に分割し、各要素の共起関係を抽出する。頻度算出部17は、校正前文書において共起関係が出現する頻度及び校正後文書において共起関係が出現する頻度を夫々算出する。さらに、差分算出部19が、校正後の共起頻度から校正前の共起頻度を差し引いた差分を算出し、共起関係に含まれる要素を次元軸とし差分を成分とする差分ベクトルを生成する。また、校正規則作成部20が、差分ベクトルが生成された要素について差分ベクトルを反転させ、当該反転させたベクトルと他の要素の差分ベクトルとが一致又は近似するときに、当該要素と当該他の要素とで校正規則を作成する。そして、表示処理部21及び辞書登録部22が当該校正規則を出力する。
(もっと読む)
カスタム言語モデル
カスタム言語モデルを生成するためのコンピュータ・プログラム製品を有するシステム、方法、及び装置。一実施形態では、方法が提供される。前記方法は、ドキュメントのコレクションを受信する段階と;前記ドキュメントを1又は2以上のクラスタにクラスタリングする段階と;前記1又は2以上のクラスタの各クラスタのためにクラスタ・ベクトルを生成する段階と;対象プロファイルに関連した対象ベクトルを生成する段階と;前記クラスタ・ベクトルの各々と前記対象ベクトルを比較する段階と;比較に基づいて1又は2以上のクラスタのうちの1又は2以上を選択する段階と;前記選択された1又は2以上のクラスタからドキュメントを使用して言語モデルを生成する段階とを有する。  (もっと読む)
(もっと読む)
情報処理装置、およびプログラム
【課題】従来の情報処理装置においては、自然言語の単語列の中の話題の変化点を推定できない、という課題があった。
【解決手段】処理対象情報が格納されるN個のバッファと、前記各バッファに対応付けて、ディリクレ分布を、それぞれ2以上格納しており、各バッファから、単位情報を取得し、バッファごとに、処理対象情報の中の最も近い変化点以降の単位情報から直前の単位情報までの1以上の単位情報に基づいて、ディリクレ分布を更新し、各バッファに対応する2以上のディリクレ分布を用いて、次の単位情報に関する確率分布である予測確率分布を、バッファごとに算出し、算出したバッファごとの予測確率分布に基づいて、バッファ変化点確率を算出し、バッファ変化点確率に基づいて所定の処理を行う情報処理装置により、自然言語の単語列の中の話題の変化点を推定できる。
(もっと読む)
1 - 8 / 8
[ Back to top ]