
Fターム[5B091CC15]の内容
Fターム[5B091CC15]に分類される特許
1 - 20 / 168
例文表示装置及びプログラム
【課題】入力単語とその翻訳単語を入力して、これらの単語に対応する例文を検索する装置を提供する。
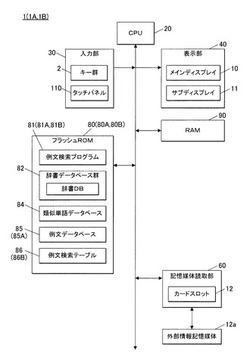
【解決手段】電子辞書1は、英語例文と、英語例文に対して対訳関係にある日本語例文との例文対を複数記憶する例文データベース85と、ユーザ操作に基づいて英語における何れかの単語を英語キーワードとして入力するとともに、日本語における何れかの単語を日本語キーワードして入力する入力部30と、例文データベースにより記憶された複数の例文対のうち、英語キーワードと日本語キーワードとを互いの対訳部分として含む例文対を単語対応例文対として検索するCPU20と、単語対応例文対を表示する表示部40とを備える。
(もっと読む)
機械翻訳辞書作成装置、機械翻訳辞書作成方法、およびプログラム

【課題】機械翻訳用の辞書への新語の登録において、簡易な処理で、世の中で広く用いられている訳語を登録する。
【解決手段】検索に用いられた検索キーワードについて、検索回数と検索キーワードの翻訳辞書8への登録の有無を検索履歴6として記録する検索履歴生成部5と、翻訳辞書8に登録されていない検索キーワードについて、翻訳辞書8に登録されている複数の単語に分解し、各々の単語に対して複数の訳語が登録されている場合には、それぞれの訳語を組み合わせて複数の訳語候補を作成し、各々の訳語候補について翻訳辞書8への登録の有無を確認し、登録されている場合には、検索回数が最も多いものを訳語に決定して翻訳辞書8に登録する翻訳辞書生成部7と、を備える。
(もっと読む)
電子メール情報表示システムおよび電子メールクライアント
【課題】膨大な量の電子メールの中から、必要としている情報を迅速に探し出すことができる電子メール情報表示システムを提供する。
【解決手段】電子メール情報表示システムのクライアントPC101は、ヘッダ情報に基づき、任意の電子メールに対して、送信、受信、返信、および転送を含む電子メールの一連のやり取りの流れを構築し、表示する手段と、一連のやり取りの流れが構築された任意の電子メールを含んだ、一連のやり取りの流れに含まれる全ての電子メールに対して、本文に含まれる文章の各行に対し、引用符「>」の抽出と文章の形態素解析を行う手段と、その結果により、各電子メール本文に含まれるキーワード群と各キーワードに付与されていた引用符数を抽出し、電子メールの一連のやり取りの中での重要キーワードを決定する手段と、電子メールの一連のやり取りの流れと、当該重要キーワードとを表示する手段等を備える。
(もっと読む)
例文検索装置、処理方法およびプログラム
【課題】複数の異なる言語の入力キーワードに基づいて特定言語の例文を検索する例文検索装置、処理方法およびプログラムを提供する。
【解決手段】複数の例文を記憶する例文データベースと、所定言語と異なる特定言語の語句ごとに、その語句と、その語句の訳語である所定言語の語句と、を互いに対応付けて記憶する辞書データベースと、所定言語のキーワードと、特定言語のキーワードと、をそれぞれ受け付ける入力部と、辞書データベース内の所定言語の語句のうち、特定言語のキーワードに対応付けられた訳語を訳語キーワードとして検出する検索式生成部と、例文データベース120内の例文の中から、所定言語のキーワードと訳語キーワードとの少なくとも一方を含む例文を検索し、その検索結果を出力する検索部と、を含む。
(もっと読む)
中継サーバ
【課題】現場の研究開発者が自ら英語以外の言語を用いた特許調査を接続先を意識せずに容易に行うことが可能な特許検索システムのための中継サーバを提供する。
【解決手段】検討対象特許データから重要語を抽出するために検討対象特許データの各単語の重要度を算出する重要度算出手段(330)と、前記重要度に基づいて抽出された重要語を用いて前記検討対象特許データの特許分類を判定する第1の特許分類判定手段(335)と、前記判定した特許分類を用いて専門辞書を特定し、該特定した専門辞書を用いて前記重要語を所望の言語に翻訳する第1の翻訳処理手段(340)と、前記所望の言語に翻訳された重要語を用いて検索式を生成する第1の検索式生成手段(345)と、前記所望の言語に応じた接続先である特許データベースサーバに対して、前記接続先に応じた接続要求を生成する第1の接続要求生成手段(350)とを備えた。
(もっと読む)
同韻語検索装置、同韻語検索方法、同方法を実現するプログラム、及び同プログラムを記録するコンピュータ読み取り可能な記録媒体
【課題】 簡単な操作で迅速に所望の同韻語を抽出できるようにすること。
【解決手段】 母音情報及び鼻音情報が付与された文字列情報を格納する辞書機能と、辞書機能からの文字列情報または入力される文字列情報を表示する機能と、この表示される文字列情報の読み数情報を表示する機能と、この表示される読み数情報に対して所望の位置情報を指定入力する機能と、この指定入力される位置情報に関し当該位置情報を変更可能とする機能と、この変更可能な位置情報を参照して当該位置情報と相当の位置にて指定入力された位置情報に対応する文字の読みの母音情報若しくは鼻音情報と合致する文字列情報を辞書機能から検索抽出する機能と、この抽出された文字列情報を出力表示する機能とを設けたことを特徴とする。
(もっと読む)
情報処理装置、方法及びプログラム
【課題】与えられた文脈からは類型が不明な名詞の類型を判定する。
【解決手段】検索エンジンの検索結果における名詞に関する文脈に基づくことにより、与えられた文脈からは類型が不明な名詞についても名詞の類型が判定できるので、判定した類型を、例えば関連検索における関連検索ワードの提示や、ウェブ検索結果のリスト順の制御に反映するなど、ユーザの意図に基づく情報処理結果の最適化に活用可能となる。要約の所定数に対し、類型ごとに、対応するパターンで判定対象の名詞が用いられているなどで判定された数量を集計し、その多いものを優先して判定結果として後処理へ渡すなどの形で出力することにより、複数の類型に該当する名詞についても、最も一般的な類型、又は数番目までの主要な類型を判定結果として利用できるので、多くのユーザの意図に合致する情報処理結果の最適化が可能となる。
(もっと読む)
情報検索手法による統一化されたタスク依存の言語モデルの生成
【課題】タスク独立のコーパスから言語モデルを生成するための方法(20)が提供される。
【解決手段】一実施例では、タスク依存の統一化された言語モデル(140)が生成される。統一化された言語モデル(140)には、ノンターミナルを持つ複数の文脈自由文法(144)およびそこに組み込まれた同一のノンターミナルの少なくともいくつかを持つハイブリッドNグラムモデル(142)が含まれる。
(もっと読む)
翻訳支援装置、方法及びプログラム
【課題】翻訳者の訳語決定作業を適切に支援する。
【解決手段】本装置は、第1言語の単語と当該単語に対する第2言語の訳語とを格納する訳語格納部と、第2言語による例文を格納するコーパス格納部と、第1言語の複合語の入力を受け付けた際、当該複合語に含まれる各単語について、訳語格納部から当該単語に対する訳語を取得する取得部と、取得した訳語の組み合わせで表される第1訳語列の一部分である第2訳語列を生成する訳語列生成部と、第1訳語列に含まれ且つ第2訳語列には含まれない単語である差分単語の代わりとしてワイルドカード検索のための所定のデータを第2訳語列に付して検索キーを生成するキー生成部と、検索キーを用いてコーパス格納部を検索し、当該検索キーにて検出された単語列から第2訳語列以外の単語である代替訳語を抽出する抽出部と、第1訳語列と共に、差分単語の該当部分に対応付けて、抽出された代替訳語を列挙して提示する出力部とを有する。
(もっと読む)
地域対応手話生成システム、地域対応手話生成方法、および地域対応手話生成プログラム
【課題】手話の地域性に対応し、聴覚障害者がより容易に、より迅速に情報を理解できるようにする。
【解決手段】地域対応手話生成システムであって、外部システム200から少なくとも1つのテキストを入力する入力手段111と、入力された各テキストについて第1の記憶手段101を参照して対応する手話IDを検索し、検索した手話IDに対応する手話表現映像を第2の記憶手段102から検索する検索手段112と、検索した各テキストの手話表現映像を出力する出力手段113とを備え、第1の記憶手段101は、地域毎に個別に作成され当該地域でのみ通用する特有の手話が存在するテキストについては当該地域用の手話表現映像の手話IDが記憶され、第2の記憶手段102には、地域を越えて通用する標準の手話表現映像と所定の地域でのみ通用する特有の手話表現映像とが記憶されている。
(もっと読む)
検索最適化方法、プログラム及び装置
【課題】蓄積されたFAQなどから今回の質問等に適合した文章を抽出できるようにする。
【解決手段】本方法は、入力文に含まれる所定種類の第1の単語群を抽出し、データ格納部に格納するステップと、入力文に対して選択された選択出力文に含まれる所定種類の第2の単語群を抽出し、データ格納部に格納するステップと、データ格納部に格納されている第1の単語群のうち第2の単語群と共通する共通単語を抽出するステップと、単語毎に当該単語を含む出力文の識別子及び重み値を格納するインデックス格納部において、第1の単語群のうち少なくとも共通単語と選択出力文の識別子で特定される重み値を増加させる更新ステップとを含む。
(もっと読む)
電子機器及び情報表示プログラム
【課題】見出し語の読みが登録されていないユーザ辞書から検索を行う。
【解決手段】電子辞書1は、各見出し語に対し、見出し語の読みを表して検索用のキーとして用いられる検索用読みと見出し語の説明情報とを対応付けてなる辞書DB820を記憶するとともに、各見出し語に説明情報を対応付けて作成されたユーザ辞書DB830を取得して記憶するフラッシュROM80と、見出し語の読みについての検索文字列の入力操作を受ける入力部30と、辞書DB820から検索文字列に対応する検索用読みの見出し語を辞書検索見出し語として検索するとともに、各辞書検索見出し語の文字列に対応する見出し語をユーザ辞書抽出見出し語としてユーザ辞書DB830から抽出し、当該ユーザ辞書抽出見出し語を一覧表示させるCPU20とを備える。CPU20は、一覧表示されたユーザ辞書抽出見出し語のうち、ユーザに選択される見出し語の説明情報をユーザ辞書DB830から読み出して表示させる。
(もっと読む)
FAQ候補抽出システムおよびFAQ候補抽出プログラム
【課題】話し言葉やノイズといった談話データの特性に強く、談話の文章構造の枠組みを規定せずに、談話データの構造を解析した結果からQ&A対を抽出するFAQ候補抽出システムを提供する。
【解決手段】談話データ101および談話セマンティクス200を入力とし、談話データ101からFAQ候補300となる質問−回答対を抽出して出力するFAQ候補抽出システム1であって、談話セマンティクス200は各ステートメントのフロー情報21を含み、質問文であることを示すフローが設定された第1のステートメントを同定し、さらに第1のステートメントの後に最初に現れ、かつ話者が異なり、談話に固有の事項について具体的な内容を述べているものであることを示すフローが設定された第2のステートメントを同定し、第1のステートメントと第2のステートメントとを質問−回答対として抽出するQ&A対抽出部60を有する。
(もっと読む)
対訳辞書拡張装置およびそのプログラム
【課題】本発明は、類義語の手話訳が日本語−手話対訳辞書に登録されていない場合でも、新たな日本語語彙の手話訳を得ることができる対訳辞書拡張装置を提供することを目的とする。
【解決手段】対訳辞書拡張装置1は、日本語−手話対訳辞書を拡張するものであり、類義語データが入力される入力端子10と、類義語データを記憶する対訳なし類義語記憶手段20と、日本語−手話対訳辞書を記憶する日本語−手話対訳辞書記憶手段30と、日本語−手話対訳辞書を拡張する日本語−手話対訳辞書拡張手段40と、更新信頼度を算出する更新信頼度算出手段50と、日本語−手話対訳辞書を出力する出力端子60とを備え、拡張した後の日本語−手話対訳辞書を繰り返し検索する。
(もっと読む)
機械翻訳システム、機械翻訳方法及び機械翻訳プログラム
【課題】翻訳処理の際に、別の機械翻訳システム上の辞書の情報を利用することが可能であり、かつ、システム間のデータ転送量が少なくて済むようにする。
【解決手段】第1の翻訳システムは、翻訳に用いる辞書を記憶する第1の辞書記憶手段と、第1の辞書記憶手段が記憶する辞書を用いて、入力文を翻訳する第1の翻訳手段と、第1の辞書記憶手段が記憶する辞書を用いて、第1の翻訳手段が翻訳処理に用いた辞書エントリに関連づけられた辞書エントリを第1の辞書記憶手段が記憶する辞書から抽出し、抽出した辞書エントリを通信回線を介して第2の翻訳システムに送信する辞書エントリ抽出手段とを含み、第2の翻訳システムは、翻訳に用いる辞書を記憶する第2の辞書記憶手段と、第1の翻訳システムから通信回線を介して送信された辞書エントリを受信し、受信した辞書エントリを第2の辞書記憶手段が記憶する辞書に登録する辞書登録手段とを含む。
(もっと読む)
音声翻訳システム、辞書サーバ装置、およびプログラム
【課題】従来、音声翻訳において使用する音声認識辞書、翻訳辞書、および音声合成辞書において不整合があった。
【解決手段】2以上の言語について、音声認識、翻訳、音声合成に利用する全言語用語情報を2以上格納し得る全言語対辞書格納部と、全言語について、用語の音声認識情報を含む音声認識用情報を取得し、1以上の音声認識サーバ装置に送信する音声認識用情報送信部と、全言語について、用語の表記を含む翻訳用情報を取得し、1以上の翻訳サーバ装置に送信する翻訳用情報送信部と、全言語について、用語の音声合成情報を含む音声合成用情報を取得し、1以上の音声合成サーバ装置に送信する音声合成用情報送信部とを具備する辞書サーバ装置により、辞書間の不整合を解消できる。
(もっと読む)
漢文例文検索装置およびプログラム
【課題】漢文例文検索装置において、漢文の例文を漢文の訓読の規則を考慮して適切に検索すること。
【解決手段】漢文検索入力画面Gの熟語検索文字列入力エリアE1に検索文字列(熟語)が入力された場合には、漢文例文データベースから順次読み出される例文データを対象に、前記検索文字列(熟語)と完全一致し且つその文字列間に返り点が存在しない文字列(熟語)を含んでいる例文データが検索されて表示される。また、読み順検索文字列入力エリアE2に検索文字列(読み順)が入力された場合には、漢文例文データベース24cから順次読み出される例文データを対象に、漢文の訓読の規則に従った漢字1文字が順次取得され、前記検索文字列(読み順)と完全一致する例文データが検索されて表示される。
(もっと読む)
辞書評価支援装置およびプログラム
【課題】業務文書チェック辞書のような辞書の評価作業を支援することを可能とする。
【解決手段】正規表現解析部32は、パターンマッチ辞書24に格納されている第1のパターンに含まれる第1の自立語を抽出する。形態素解析辞書検索部33は、第1の自立語と同音かつ同品詞である第2の自立語を形態素解析辞書23から検索する。辞書パターン作成部34は、第2の自立語を含む表現を表す第2のパターンを作成する。パターンマッチ部35は、第1のパターンによって表される表現を含む第1の例文のパターンマッチ結果および第2のパターンによって表される表現を含む第2の例文のパターンマッチ結果を作成する。例文追加部37は、第1の例文の数が予め定められた数以上でない場合、当該第1のパターンによって表される表現を含む第3の例文を例文コーパス22に追加する。結果出力部38は、第1乃至第3の例文のパターンマッチ結果を出力する。
(もっと読む)
オンライン辞書サービス提供装置及び方法
【課題】多様な種類の言語に対してユーザが選択した言語に基づいた翻訳サービスを提供することができるオンライン辞書サービス提供装置及び方法を提供する。
【解決手段】ローディングされたウェブページに含まれた単語に対応する単語インデックス情報及び予め定められた翻訳言語情報を含むクエリをユーザ端末から受信し、前記翻訳言語情報及び単語インデックス情報を抽出するクエリ分析部と、原本言語の各単語に対する対象言語による翻訳データを含む少なくとも一つの辞書データを含む辞書データ格納部と、前記翻訳言語情報及び前記単語インデックス情報に基づいて前記辞書データを選択する辞書選択部と、前記選択された辞書データから前記単語インデックス情報に該当する前記翻訳データを検索する検索部と、前記翻訳データを前記クライアントに伝送する検索結果伝送部とを含む。
(もっと読む)
異国単語の内容が一目瞭然たる翻訳方法の発明
【課題】一度辞書を引けば以後は一簡易表示で意味、発音、綴り、緒情報を表示し二回目以降は一度で分かる表示法を提供する。
【解決手段】表音文字の外国語の単語を表意文字及び平かな、片仮名、ハングル文字、アルファベット及び発音記号、数式記号、濁点半濁点、括弧を組み合わせて表記し、補助としてアルファベットと表意文字を合体したユニットを表意文字の代用とする方法、外国単語を表意文字又は当ユニットを手がかりに検索する方法である。表示法は4段構造を持ち、1段目に必要に応じ平かな主体の該当外国語単語の慣用読みを、2段目に該当外国語単語を置き、3段目に例えば「封筒」の「envelope」であればenの当表示たる「入乃」があり接頭辞でラテン語系が分かる。このように必要に応じ補足説明や接頭辞、単語の構成や由来など諸情報を記す。4段構造の4段目に同じく当表示のen[閉゛牢ァ封゜]という表示を置く。
(もっと読む)
1 - 20 / 168
[ Back to top ]