
Fターム[5D015DD02]の内容
Fターム[5D015DD02]に分類される特許
101 - 120 / 123
対話型ロボット、対話型ロボットの音声認識方法および対話型ロボットの音声認識プログラム

【課題】対話する人間の操作負担を増加させることなく、音声認識精度を向上させることのできる対話型ロボットを提供する。
【解決手段】音声認識可能な対話型ロボット400であって、音声認識の対象となる目的音声の音源方向を推定する音源方向推定手段と、音源方向推定手段が推定した音源方向に当該対話型ロボット自身を移動させる移動手段と、移動手段による移動後の位置において、目的音声を取得する目的音声取得手段と、目的音声取得手段が取得した目的音声に対して音声認識を行う音声認識手段とを備えた。
(もっと読む)
音声処理装置

【課題】発話者の音声データに対してなんらかの音声処理を行う場合に、発話者が、自分の声が小さすぎたり大きすぎたりしていることを容易に把握できるようにする。
【解決手段】マイクロフォンMC1〜MC6と、マイクロフォンMC1〜MC6からの音声データに対して所定の音声処理を行う音声処理手段と、この音声データのレベルが、所定のレベル範囲の下限よりも低いか、この所定のレベル範囲内であるか、この所定のレベル範囲の上限よりも高いかを判別するレベル判別手段と、マイクロフォンMC1〜MC6に対応する位置に設けられた表示手段DP1〜DP6と、少なくとも、このレベル判別手段で判別されたレベルが、この所定のレベル範囲の下限よりも低いときと、この所定のレベル範囲の上限よりも高いときとで、表示手段DP1〜DP6に異なる表示を行わせる表示制御手段とを備える。
(もっと読む)
対象音検出方法、信号入力遅延時間検出方法及び音信号処理装置
装着型マイクロホンを用いた環境変動に対してもロバストな受音系の構築を可能にする。音声信号処理装置10は、マイク1,2に入力された音信号間のクロススペクトルの位相を検出する第1及び第2フレーム化部11,12、第1及び第2周波数分析部13,14及びクロススペクトル計算部15と、クロススペクトル計算部15が検出したクロススペクトルの位相の周波数に対する傾きを検出する位相抽出部16、位相unwrap処理部17、周波数大域分割部31及び第1乃至第N傾き計算部321〜32N、と、第1乃至第N傾き計算部321〜32Nが検出した前記周波数に対する傾きに基づいて、マイク1,2が受音した発話の発話区間を検出するヒストグラム等計算部33及び音声/非音声判定部34とを備える。 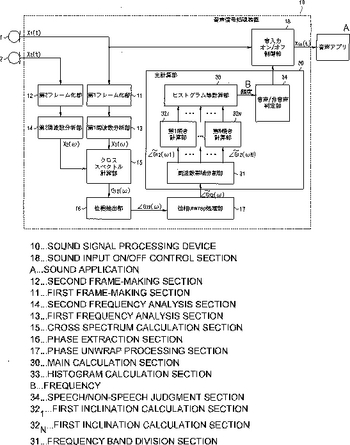 (もっと読む)
(もっと読む)
音声処理装置
【課題】 ユーザに不自由さや不快感を与えることなく、ユーザの音声認識をできるようにする。
【解決手段】 アレイ状にマイクロホンが配設されたマイクロホンユニット100に向けてユーザは発声する。マイクロホンユニット100に配設された複数のマイクロホンに音声が入力されると、制御装置200は、アレイ状に配設された複数のマイクロホンから出力される信号から、発音した時の音圧レベル分布と周波数スペクトルとを検知し、ユーザが発した音声を、この音圧レベル分布と周波数スペクトルとから判別する。
(もっと読む)
音源方向検出方法、音源方向検出装置及び撮影装置
【課題】 特定したい音源方向の数に対し、少ないマイクロホンの数で音源方向を判別するとともに、各々のマイクロホンの特性を正確に合わせる必要性が軽減されるようにする。
【解決手段】 回転軸と垂直な平面上において互いにほぼ180度反対向きに配置された音響変換手段対を複数用いて音源からの音を検出し、その音響変換手段対で検出された音圧レベルの比を複数対について計算し、算出された各音圧レベルの比をその値に応じてパターン分けし、そのパターンの組み合わせを、予め作成しておいた各音圧レベルの比と音源方向との関係を表すパターン組み合わせ情報と照会して音源の方向を特定する。
(もっと読む)
音声処理装置,音声処理方法,プログラム及び記録媒体
【課題】 所定の時間間隔を単位時間として声紋認証を行う際に、この声紋認証単位時間のうちの一部の時間だけ大きな声で発話が行われて残りの時間には発話が行われなかったような場合にも、誤認証率を下げて発話者特定の精度を高める。
【解決手段】 所定のサンプリング周期でサンプリングされた入力音声データを、各サンプリングタイミングのデータ毎に、閾値と比較することによって有音データか無音データかに分類し、このサンプリング周期よりも長い所定の時間間隔(声紋認証単位時間)を単位として、この分類結果を集計する(S2〜S11)。その集計結果に基き、入力音声データを声紋認証の対象とするか否かを、声紋認証単位時間分の音声データ毎に決定する(S12〜S16)。そして、入力音声データのうち、この声紋認証の対象とすることを決定した各声紋認証単位時間分の音声データについてのみそれぞれ声紋認証を行う。
(もっと読む)
マイクロホン装置、発話検出装置、発話検出方法および音声出力方法
【課題】 話者の発話期間を効率的に検出可能なマイクロホン装置を実現する。
【解決手段】 超音波送出部111は、話者Sに向けて超音波を送出する。音波超音波受信部112は、話者Sの発話による音波と、話者Sに当たって反射した超音波と、の混合波を受信する。受信した混合波は、帯域分離部12のLPF121とBPF122によって、音波と超音波とに分離される。検波回路13は、超音波として分離された信号波を検波して半波整流と平滑化とを行う。微分回路14は、検波された信号波の時間変化を検出し、話者Sの唇の動きに相当するを波形を抽出する。発話判定部15は、微分回路14によって検出された時間変化に相当する信号波の信号レベルが所定の閾値を超えているか否かを判別し、判別結果に基づいてスピーカスイッチ16に音声出力をONさせる。
(もっと読む)
音声入力装置
【課題】 話者音声を確実に抽出することのできる簡易な構成の音声入力装置を提供する。
【解決手段】 音声入力装置10は、所定の位置関係に配置された複数のマイクロフォンで構成されるマイクロフォンアレイにより話者が発声する話者音声および騒音を収音する収音手段1と、収音手段1の出力に基づいて収音手段1に対する話者の方向を決定する話者方向決定手段2と、話者方向に基づいて収音手段1の指向性を変更して話者音声を抽出する話者音声抽出手段3とを含む。
(もっと読む)
音声入力装置及び方法、並びにプログラム及び記憶媒体
【課題】 低音量で明瞭でない音声でも音声入力や音声認識を行うことができる音声入力装置及び方法、並びにプログラム及び記憶媒体を提供することにある。
【解決手段】 音声入力装置において、咽喉マイク1は、人の声帯のある喉付近に装着され、人が音声を発したときに、その音声に応じた声帯の振動を検出して、その振動を電気信号に変換する。変換された電気信号は、A/D変換部2に送られる。A/D変換部2は、咽喉マイク1から送られてきたアナログ信号をデジタル信号に変換し、そのデジタル信号を特徴抽出部3に送る。特徴抽出部3は、デジタル信号を周波数変換し、周波数領域で特徴パラメータを抽出し、発声された特徴パラメータの列として照合部4に送る。照合部4は、認識辞書部5に記憶された各単語の標準パターンとの比較を行い、最も近似する単語を選択する。CPU6は、認識辞書部5で選択された単語を入力文字として処理する。
(もっと読む)
単独行動者及びグループ行動者検知装置
【課題】各地点の動画像を取得し、該動画像から取得した人物の挙動の情報に基づいて人物をグループ分けすることによって、人物が単独行動をしているかグループ行動をしているかを的確に検知することができ、人物の性別、年齢等の情報からそのグループ形態がどのようなものであるかを検知することができ、さらに、体格、泣き声等の情報から迷子を的確に、かつ、迅速に検知することができるようにする。
【解決手段】動画像から人物及び人物の位置を所定時間経過毎に検出する人物検出手段と、人物の相互の位置関係から人物をグループ分けするグループ判定を行う人物グループ判定手段と、グループ判定の結果から人数に着目して単独行動者又はグループ行動者とグループ形態とを判定する人物グループ形態判定手段と、グループ形態を通知する人物グループ通知手段とを有し、動画像に含まれる人物についてグループ判定を行う。
(もっと読む)
音声認識通報装置
【課題】 緊急車両の接近方向、接近状態を運転者が直感的に認識できる音声認識通報装置を提供する。
【解決手段】 自動車車外には複数のマイクが配置されており、車外の音声を集音する。警報音認識部は集音した音声から緊急車両の発する警報音を認識し、方向検出部によって緊急車両の存在方向を検出する。制御部は検出した緊急車両の方向に応じて各車内スピーカに音源部が生成した擬似警報音の音声信号を割り当てるようにミキサに設定する。さらにカーオーディオの音量を下げて、擬似警報音の音量を上げるようにミキサに設定する。これにより運転者は緊急車両の接近方向を音声によって正確に認識することができる。また、ナビゲーションシステムと連動してディスプレイに表示する地図上に緊急車両の接近状態を示してもよい。
(もっと読む)
音響信号入出力装置
【目的】音声認識機能を備える各種システムの音声認識装置に対する音響信号入出力装置を提供する。
【構成】音響信号入出力装置30は、マイクロフォン1a〜1dを所定間隔d離して組み合わせてなる音響信号入力手段1と、各マイクロフォン1a〜1dのアナログ音響信号Sa〜Sdをデジタル音響信号Da〜Ddに変換するA/Dコンバータ2と、変換されたデジタル音響信号Da〜Ddを分析して音源の方向を検出する音源定位手段3と、音源定位手段3にて定位された音源Aが予め設定された角度範囲δ内の方向からの音源か否かを判定する音源角度判定手段11と、音源Aが人の音声か否かをデジタル音響信号Ddを分析して判定する音声検出手段12と、音源Aが予め設定された前記角度範囲δ内の方向であり且つ人の音声が含まれる場合のみ前記デジタル音響信号Ddを出力するゲート回路20と、を備える構成である。
(もっと読む)
マイクロホン装置、発話判別装置および発話判別方法
【課題】 話者の発話区間を精緻かつ効率的に検出可能な発話判別装置を実現する。
【解決手段】 発振部12はマイクロ波を発振して、送受信部14に供給する。送受信部14は、話者の唇に向けてマイクロ波を送出し、その反射波を受信する。混合部15は、発振部12が発振したマイクロ波と受信した反射波とを周波数混合し、混合波を生成する。発話判定部17は、混合波から、送出波と反射波との間の周波数の違いに相当する成分を検出し、その周波数成分が所定の閾値よりも大きいか否かを判別する。閾値よりも大きいと判別すると、話者が発話していると判定して、発話判定部17は所定レベルの信号を音声切替部18に供給する。音声切替部18は、信号の供給を受けて、音声出力のON/OFFを切り替える。
(もっと読む)
ロボット制御装置および方法、記録媒体、並びにプログラム
【課題】ノイズとユーザが発した音声とを弁別することにより、音声認識するロボットの動作を自然な動作とする。
【解決手段】 音声認識部101Aは、マイクロホン82−1乃至82−Nから入力される音声信号の音声認識処理を行う。制御部101aは、音声認識処理結果に対して、正解確信度を計算し、その正解確信度が所定の閾値より大きいと判定した場合、音声認識結果を行動決定機構部103に出力する。行動決定機構部103は、ロボットが認識処理結果に対応する動作を行うように制御する。本発明は、例えば、音声認識を行うロボットに適用できる。
(もっと読む)
音声に基づく装置制御
音声制御部100は、
オーディオ信号(103、105、107、109、111)をそれぞれ受け取る複数のマイクロホン(102、104、106、108、110)を有するマイクロホンアレイと、オーディオ信号から、ユーザ(U1)のクリーンな信号(117)を抽出するビーム形成モジュール(116)と、前記ユーザ(U1)により話された、オーディオ信号(111)により表された所定のキーワードを認識するキーワード認識システム(120)であって、前記認識に基づき前記ビーム形成モジュールを制御するように構成されたものと、前記音声信号(117)の認識された音声アイテムに基づき、前記装置(200)への命令を生成する音声認識部(118)とを有する。その結果、音声制御部(100)は、ユーザ(U1)により話された音声アイテムに対応するオーディオ信号の部分を、音声認識のためによりよく選択することができる。  (もっと読む)
(もっと読む)
音声処理システム
【課題】 装着者の行動を妨げることなく、簡便かつ低消費電力で装着者の音声認識を行うことのできる音声処理システムを提供する。
【解決手段】 音声処理システムは、無線通信機能付きヘッドセットと、ヘッドセットと無線通信可能な外部装置とを含み、無線通信機能付きヘッドセットは、ヘッドセットの装着者の音声を検出して音声信号を生成するマイクロホンと、音声信号を認識し、認識した音声信号の内容に対応する識別信号を生成する音声認識手段と、音声認識手段によって生成された識別信号を、無線通信により外部装置へ送出する認識結果伝送手段とを備え、外部装置は、受信した識別信号に対応する動作を行う。
(もっと読む)
ヘッドセット及び無線通信システム
【課題】
音声によって外部機器を確実に制御することができるヘッドセット及び無線通信システムを提供することを目的とする。
【解決手段】
本発明に係るヘッドセットは、通話するために携帯電話機13と無線通信するヘッドセット11であって、骨伝導音声を検出して音声信号を出力し、当該出力された音声信号を認識し、当該認識された音声信号を無線通信によって出力するものである。また、本発明に係るヘッドセットは、当該骨伝導マイクによって出力された音声信号から骨伝導音声の特徴情報を抽出し、当該抽出された特徴情報に基づいて、骨伝導音声を発声した個人の特徴を識別するものである。さらに、本発明に係る無線通信システムは、このようなヘッドセット11と、ヘッドセット11から出力された音声信号に基づいて動作制御を実行する外部機器21とを備えた無線通信システム1である。
(もっと読む)
個人認証システム
【課題】 セキュリティレベルの更なる向上が可能であり、かつ、生きた本人が直接操作しない限り、セキュリティ突破することが困難な個人認証システムを提供する。
【解決手段】 認証処理対象者の音声情報を骨伝導音検出部340と気導音検出部304との双方にて検出し、それら骨伝導音声情報と気導音声情報との双方に基づいて認証処理を行なう。骨伝導音と気導音との単独では知りえなかった、両波形の差異に由来した特徴情報が新たに把握可能となり、個人認証のセキュリティレベルを大幅に高めることができる。また、骨伝導音声情報と気導音声情報とが、いずれも情報種別としては同質の音声情報であるため、ハードウェアやソフトウェアの処理上の共有化も容易であり、波形の差異に由来した特徴情報を演算によって抽出することも容易である。
(もっと読む)
音響通信のための方法およびシステム
眼鏡フレーム(10)が、ユーザ(21)の音声信号をキャプチャするための少なくとも1つの方向依存のマイクロホン(13、15、16)と、外部電子デバイス(30)に信号を伝送するための通信手段(12)とを含み、少なくとも1つのマイクロホン(13、15、16)の方向依存性は、適応する形でユーザ固有に調整可能であるようになっている、音響通信のためのシステムおよび方法。特に、方向依存のマイクロホンは、マイクロホン・アレイとして、かつ/またはMEMS技術で実施されることが可能であり、接触マイクロホンが、使用されることが可能である。  (もっと読む)
(もっと読む)
体内伝導音マイクロフォン、信号処理装置、コミュニケーションインタフェースシステム、採音方法
非可聴つぶやき音をできるだけ忠実に取得しようとする際に、主として液体である体内軟部組織の皮膚表面と気体である空気空間との界面での音響インピーダンスの不整合に起因する高域の減衰を抑制する。人間の乳様突起直下の体表にマイクロフォンを装着させ、声帯の規則振動を用いない発話行動(口の動き)に伴って調音される非可聴つぶやき音の肉伝導の振動音を、硬化したシリコーンゴム等を
介してコンデンサマイクロフォン部で採取することにより、音響インピーダンスの不整合に起因する高域の減衰を抑制することができる。
(もっと読む)
101 - 120 / 123
[ Back to top ]