
Fターム[5D015HH11]の内容
音声認識 (5,191) | パターン照合による認識 (426) | 二段階以上の比較、選択処理 (89)
Fターム[5D015HH11]の下位に属するFターム
予備選択 (16)
パターン照合の並列処理 (16)
再照合 (14)
Fターム[5D015HH11]に分類される特許
1 - 20 / 43
音声認識装置、方法及びプログラム
【課題】音声認識精度を向上することにある。
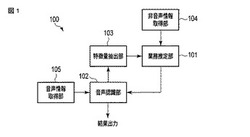
【解決手段】一実施形態に係る音声認識装置は、業務推定部、音声認識部及び特徴量抽出部を含む。業務推定部は、利用者の業務に関連する非音声情報を用いて利用者が行っている業務を推定し、該業務の内容を示す業務情報を生成する。音声認識部は、前記業務情報に対応する音声認識手法に従って前記利用者が発した音声情報に対して音声認識を行い、音声認識結果を生成する。特徴量抽出部は、前記音声認識結果から、前記利用者が行っている業務に関連する特徴量を抽出する。前記業務推定部は、少なくとも前記特徴量を用いて前記利用者の業務を再推定し、前記音声認識部は、再推定の結果得られる業務情報に基づいて音声認識を行う。
(もっと読む)
音声認識装置及びプログラム

【課題】単語を高速で認識することができると共に、特定した単語の信頼度を高める。
【解決手段】音声認識装置10は、各単語と該各単語に関連する単語を示す1又は複数の関連単語とを対応付けて記憶する記憶部140と、第1の音声と前記第1の音声に続く第2の音声とを入力する音声入力部110と、音声入力部110により入力された第1の音声が表している単語を特定し、特定された単語に関連する単語を記憶部140に記憶されている関連単語のうちから抽出し、音声入力部110により入力された第2の音声が表している単語を、抽出した単語のうちから特定する制御部150と、を備える。
(もっと読む)
音声認識システム
【課題】音声認識前のエンロール機能を活用するための登録作業が必要なく、音声認識に係る認識率を飛躍的に向上させ、誤認識や誤動作を起こすことのない音声認識システムを提供することを課題とする。
【解決手段】認識システム1における認識コンピュータ2は、話者Sが発声する音声Vを検出し、音声情報17を取得する音声情報取得手段8と、音声情報17に基づいて、音声Vに係る発音傾向を分析し、特定する発音傾向特定手段9と、標準辞書SD及び複数の発音傾向辞書X1等を記憶する辞書群記憶手段10と、発音傾向に合致等する一の発音傾向辞書X1等を選定する辞書選定手段11と、標準辞書SDを利用して語彙を照合する標準照合手段12と、発音傾向辞書X1等を利用して語彙を照合する発音傾向照合手段13と、認識された音声Vに係る語彙を出力する語彙出力手段14とを具備する。
(もっと読む)
ロボットおよび音声認識装置ならびにプログラム
【課題】音声認識の精度を向上させること。
【解決手段】音声をデジタル化して音声データを出力するマイクロフォン14と、マイクロフォン14から出力された音声データと辞書に登録された単語とを照合することで音声を認識する音声認識装置50とを備え、音声認識装置50は、複数の音声認識エンジンを有する第1処理部61を備え、一の音声認識処理部は、他の音声認識処理部とは異なるタイミングで、かつ、他の音声認識処理部の音声認識期間内に、音声認識を開始するロボットを提供する。
(もっと読む)
パターン認識辞書作成装置及びプログラム
【課題】 辞書を記憶する記憶容量が小さな装置であっても、画像パターンの認識精度を向上させることができるパターン認識辞書作成装置を提供する。
【解決手段】 入力画像の特徴量を求めて特徴ベクトルを生成する特徴ベクトル生成部111と、各画像の特徴ベクトル同士を比較して類似度の高い画像をグループとしてまとめるグループ化部114と、特徴ベクトル生成部で生成された特徴ベクトルに基づいて、画像の画素分布の情報を含む複数の特徴データを生成する主成分分析部113と、パターン認識用辞書を作成する場合に、グループに含まれない画像の特徴データのデータ量よりもグループに含まれる画像の特徴データのデータ量が多くなるように記憶装置23にデータを記憶させる辞書生成・登録部115とを有している。
(もっと読む)
音声翻訳装置、方法、およびプログラム
【課題】発話内容の修正にかかる利用者の負担を軽減させることができる音声翻訳装置、方法、およびプログラムを提供する。
【解決手段】音声入力受付部100は、日本語の発話音声の入力を受け付け、音声認識部120は、発話音声の入力が受け付けられる毎に、当該発話音声を認識して文字列を生成し、蓄積部42は文字列を順次蓄積し、判定部130は、新たに蓄積する候補である第2文字列が先に蓄積された第1文字列の言い直しであるか否かを判定し、修正部140は、言い直しでない場合には、第2文字列を蓄積部42に蓄積させ、言い直しである場合には、第1文字列を第2文字列に修正して蓄積部42に蓄積させ、翻訳部150は、蓄積部42に蓄積される毎に、蓄積されている文字列を英語に翻訳し、出力部30は、翻訳結果を出力する。
(もっと読む)
音声認識検索装置及び音声認識検索方法
【課題】日々変化する情報を検索する際に、音声認識精度を向上させることができる音声認識検索装置を提供する。
【解決手段】
更新される検索対象データを記憶する検索対象データ記憶部31と、検索対象データから第1の音声認識辞書を動的に生成する辞書生成部25と、第1の音声と第2の音声とを取得する音声取得部34と、第1の音声認識辞書を用いて第1の音声を認識しテキスト化して第1のテキストデータを生成し、第2の音声認識辞書を用いて第2の音声を認識しテキスト化して第2のテキストデータを生成する音声認識部21と、第1のテキストデータを第1の検索キーワードとして検索対象データ内を検索する第1の検索部28と、第2のテキストデータを第2の検索キーワードとして第1の検索部28による検索結果内を検索する第2の検索部29とを備える。
(もっと読む)
フラグメントを使用した大規模なリストにおける音声認識
【課題】計算の労力がさらに最小化される、エントリのリストから、エントリを選択する音声認識方法を改善すること。
【解決手段】音声入力によってエントリのリストからエントリを選択する音声認識方法であって、該方法は、以下のステップ:音声入力を検出するステップと、該音声入力を認識するステップと、該リストのエントリのフラグメントを提供するステップと、該認識された音声入力を該エントリのリストと比較することにより、該比較の結果に基づいて最も良く一致するエントリの候補リストを生成するステップであって、該候補リストを生成するために、該認識された音声入力は、該エントリの該フラグメントと比較される、ステップとを包含する、方法。
(もっと読む)
音声認識方法および装置ならびに音声認識プログラムおよびその記録媒体
【課題】前向き探索および後向き探索を含む複数の探索を独立に実行し、各探索により得られた認識結果を正当に評価することにより、文法に記述できない物音や音声が文頭や文末に混入する場合でも、確度の高い認識結果を得られるようにした音声認識方法および装置ならびに音声認識プログラムおよびその記録媒体を提供する。
【解決手段】前向き探索では、音声データの最終フレームまで到達していない状態仮説Eに関して、その累積尤度Sf9と、後向き探索で得られた最大累積尤度Mr14との加算値をフレーム数T(=23)で除した値(Sf9+Mr14)/Tがフレーム平均尤度となる。後向き探索では、音声データの先頭フレームまで到達していない状態仮説Gに関して、その累積尤度Sr14と、前向き探索で得られた最大累積尤度Mf9との加算値をフレーム数T(=23)で除した値(Sr14+Mr9)/Tがフレーム平均尤度となる。
(もっと読む)
木構造辞書を記録した記憶媒体、木構造辞書作成装置、及び木構造辞書作成プログラム
【課題】 言語モデルを変更せずに、大語彙連続音声認識において未知語をある信頼度をもって認識できるようにするための木構造辞書を記憶した記憶媒体、その作成装置、及びその作成プログラムを提供する。
【解決手段】 音声認識装置140は、予め用意されている既知単語のための木構造辞書を記憶するための単語辞書150と、既知単語のユニグラム確率及びバイグラム確率を記憶するための言語モデル152と、クラス毎に未知語のための木構造辞書を記憶するための未知語を含む木構造辞書156と、単語辞書150及び言語モデル152を用いて、未知語を含む木構造辞書156を作成したり、未知語を含む木構造辞書156に新たな未知語を追加したりすることにより、木構造辞書156を管理するための未知語辞書管理部160とを含む。
(もっと読む)
音声認識装置
【課題】多数の語彙を短時間で、かつ確実に認識する音声認識装置を提供する。
【解決手段】キーワードを認識した際に、その誤認識傾向を記録した変換表を用意し、その変換表によって展開した正解候補キーワードを用意する。この正解候補キーワードを含む語彙を登録した認識文法を再び読み込み、再認識を実行する。例えば「○○公園」という音声データに対して「ホケン」というキーワードが得られることが多いのであれば認識キーワード「ホケン」と正解候補キーワード「コウエン」の関係度を高く設定する。
(もっと読む)
話者適応装置、話者適応方法及び話者適応プログラム
【課題】利用者に選択を強いること無く、完全に自動で話者適応を実行できるようにする。
【解決手段】音響分析部11は、入力音声の音響特徴量を抽出する。音響モデルデータベース13及び言語モデルデータベース14には、抽出された音響特徴量に基づいて音声認識を実行するための統計的な音響モデル及び言語モデルが格納されている。探索処理部12は、音響特徴量に統計モデルを適用して探索処理を実行し、音声認識結果を出力する。認識結果修正部15には、探索処理により出力される認識結果テキストに対して利用者からの修正を加えられる。適応利用判定部17は、修正テキストに対する信頼度スコアを算出し、修正テキストを話者適応に利用するか否かを閾値判定する。話者適応部18は、修正テキストを話者適応に利用すると判定された場合に話者適応を実行する。
(もっと読む)
音声認識装置、方法およびプログラム
【課題】認識処理を効率よく削減する。
【解決手段】フレームごとに音声特徴ベクトルを生成する手段101と、語ごとに状態遷移モデル化した第1モデルを格納する手段102と、1以上の第2モデルを格納する手段103、104と、音声特徴ベクトル列と第1モデルから語ごとに終了フレームでのある状態へ至る確率を状態ごとに計算し語ごとに複数の確率のうちの最大確率を選択する手段105と、語ごとに最大確率に対応する最大確率遷移パスを選択する手段105と、語ごとに最大確率遷移パスを第2モデルでの対応する対応遷移パスに変換する手段106、107と、音声特徴ベクトル列と第2モデルとから語ごとに対応遷移パスで終了フレームでの状態へ至る確率を計算する手段106、107と、第1モデル、第2モデルでそれぞれ得られた、語ごとの最大確率および確率に基づいて、入力音声がどの語であるかを認定する手段108と、を具備する。
(もっと読む)
語句として新たに認識するべき文字列等を取得する技術
【課題】語句として認識するべき文字列とその発音を、これまでより精度良く取得する。
【解決手段】本発明のシステムは、語句として認識する候補となる候補文字列を入力テキストから複数選択し、選択したそれぞれの候補文字列について、当該候補文字列に含まれる各文字に対して予め定められた発音を組み合わせることで、当該候補文字列の発音の候補を複数生成し、生成した発音の各候補をそれぞれ各候補文字列に対応付けたデータを、各語句がテキスト中に出現する頻度を示す数値を記録した言語モデルデータと組み合わせて、語句を示す文字列と発音の組ごとにその出現頻度を示す頻度データを生成し、生成した頻度データに基づいて入力音声を音声認識して、入力音声に含まれる複数の語句のそれぞれについて当該語句を示す文字列を発音に対応付けた認識データを生成し、候補文字列および発音の候補の組合せのうち認識データに含まれる組合せを選択して出力する。
(もっと読む)
音声認識装置及び方法
【課題】音声認識において、音響モデルを選択するために必要とされるメモリの使用量及び計算量を減らす。
【解決手段】話者及び環境に対して一定の第1音響モデルと;特定の話者及び環境の少なくとも一方に依存して変化する複数の第2音響モデルと;第2音響モデルを複数グループに分類するための、第1音響モデルと共有のパラメータ及び非共有のパラメータを有する分類モデルと;入力音声に対する第1尤度を算出して共有パラメータに関する計算結果を得ると共に第1尤度が相対的に大きい複数の単語候補を得るために、入力音声に対して第1音響モデルを用いて音声認識を行う第1の認識部と103;共有パラメータに関する計算結果及び分類モデルの非共有のパラメータを用いて入力音声に対する複数グループの第2尤度を算出する計算部と104;第2尤度が最大のグループを選択する選択部105と;を具備する。
(もっと読む)
音声認識装置
【課題】ユーザが発話により指定した地名を認識するものにあって、ユーザが必ずしも階層構造の上位から地名の指定を行わずとも、認識可能個数以内の辞書データに基づいて、認識処理を良好に行う。
【解決手段】地名辞書生成部9は、初期状態において、データベース7の最上位階層から複数の階層(全階層)のグループA〜Eに跨る地名データを抽出し、且つ、そのうち下の階層のグループ(グループC、D、E)については、認識可能最大個数Nを超えないように、該グループ内の、現在地算出部4により入力された現在位置を含む区域に関しての地名データを優先して抽出することにより、現在地地名辞書データを生成する。このとき、現在地地名辞書データには、全国的に有名な地名の特別グループA及び「都道府県名」のグループBの全体が常に含まれる。
(もっと読む)
音声認識装置及び音声認識プログラム
【課題】高精度な音声認識を実現する。
【解決手段】学習用の音声信号及び該音声信号に対応して書き起こされたテキストから学習した確率モデルを用いて、入力される認識対象の音声信号に対する音声認識を行う音声認識装置において、前記学習用の音声信号に対して音響特徴量の分析を行う音響分析手段と、前記テキストに対して形態素解析を行う形態素解析手段と、前記音響分析手段及び前記形態素解析手段の結果から所定処理時間毎における音声と文字の対応関係を生成するアライメント生成手段と、前記アライメント生成手段により得られる前記対応関係に基づいて、音声と言語の相関関係確率モデルを学習する相関関係確率学習手段と、前記相関関係確率学習手段により得られる相関関係確率モデルに基づいて、前記認識対象の音声信号に対する音声認識を行う音声認識手段とを有することにより、上記課題を解決する。
(もっと読む)
音声信号前処理装置、音声信号処理装置、音声信号前処理方法、及び音声信号前処理用のプログラム
【課題】 様々な振動源からの外来ノイズを効果的に低減する。
【解決手段】 本発明の音声信号前処理装置10は、雑音低減用第一フィルタ20と雑音低減用第二フィルタ22とを有し、音声を含む電気信号を処理して雑音成分を低減するものであり、第一フィルタ20または第二フィルタ22のいずれか一方がコヒーレントフィルタリングにより雑音を低減するコヒーレントフィルタであり、他方が非コヒーレントフィルタリングにより雑音を低減する非コヒーレントフィルタであり、第二フィルタ22は第一フィルタ20の出力をフィルタリングすることを特徴とする。
(もっと読む)
音声応答システム、音声応答プログラム
【課題】使用者の発話に合致する蓋然性の高い音声候補を特定のカテゴリに偏重することなく認識し、使用者による当該音声候補の選択結果に応答するシステム等を提供する。
【解決手段】音声応答システム10によれば、マイク2への入力音声に基づき、異なるドメインに属する複数の音声候補が認識され、かつ、出力される。これにより、当該使用者の発話から乖離したカテゴリに属する複数の音声候補が偏重的に出力される事態が回避され、当該複数の音声候補に使用者の発話に該当する音声候補を高い確率で含ませることができる。そして、当該複数の音声候補の中から使用者により選択された、当該使用者の発話に合致した1つの音声候補が高い確率で認識され、使用者の意図に沿った形での応答が可能となる。
(もっと読む)
ゲーム装置、ゲームの進行方法、およびゲーム進行プログラム
【課題】現実世界の多種多様な音または音声を使ってキャラクタを探索し、捕獲し、収集するというゲーム内容を実現するゲーム装置を提供する。
【解決手段】ゲーム装置10は、複数の音または音声に関する特徴情報からなる情報群に含まれる個々の音または音声に関する複数の特徴情報を、複数のキャラクタの個々の識別情報と対応付けて、かつ音または音声とキャラクタとの対応関係を予めプレイヤーに明示することなく記憶させた音データベースを備える。ゲームプレイ中に音探索モードを選択し起動させると入力される音または音声の特徴が解析され、その解析結果が予め記憶された特徴情報と照合される。第1の照合処理において複数の特徴情報のうちの一部が照合され、キャラクタが識別される。第1の照合処理によりキャラクタが識別されないとき第2の照合処理が実行され、第1の照合処理による照合に用いていない他の特徴情報が照合され、キャラクタが識別される。
(もっと読む)
1 - 20 / 43
[ Back to top ]