
国際特許分類[G10L11/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 15/00〜21/00のグループ中のどれか一つに限定されない音声または音響の特徴量の測定または検出 (1,940)
国際特許分類[G10L11/00]の下位に属する分類
音声信号の有無の検出 (242)
音声信号のピッチの抽出 (206)
音声信号の有声音と無声音の部分の弁別 (36)
国際特許分類[G10L11/00]に分類される特許
21 - 30 / 1,456
子音識別装置、およびプログラム
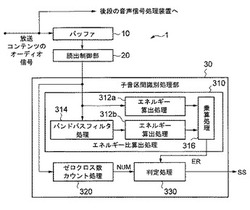
【課題】オーディオ信号における子音区間を簡単で処理負荷の軽い信号処理で確実に識別することを可能にする。
【解決手段】オーディオ信号の波形を表すサンプル列を所定サンプル数のブロックに区切り、ブロック毎に当該ブロックにおける全周波数成分のエネルギーと当該ブロックにおける所定の周波数帯域に属する周波数成分のエネルギーとを各々算出し、両者の比を算出する。加えて、各ブロックの単位時間当たりのゼロクロス数をカウントする。そして、上記エネルギー比、および隣接するブロック間でのゼロクロス数の変化態様に基づいてブロック毎に当該ブロックが子音区間に含まれるものであるか否かを判定する。
(もっと読む)
特定音響信号含有区間検出装置、方法、及びプログラム

【課題】音響信号の時間伸縮の可能性を考慮し、参照信号と蓄積信号上の参照信号に類似した区間の長さが異なる場合にも、参照信号と類似する音を含む区間を、蓄積信号中で精度よく検出することができるようにする。
【解決手段】周波数帯域毎に、各小領域参照信号スペクトログラムと類似する小領域蓄積信号スペクトログラムを検出する。周波数帯域毎に検出された、各小領域参照信号スペクトログラムに類似した小領域蓄積信号スペクトログラムの小領域類似度を、予め定められた区間伸縮率の範囲に基づく、該小領域蓄積信号スペクトログラムを含む蓄積信号の複数の時刻tを先頭とする区間の各々の区間類似度に加算することにより、蓄積信号の各区間に対する区間類似度を計算する。区間類似度に基づいて、蓄積信号中の参照信号と類似する音を含む区間を検出する。
(もっと読む)
歌唱支援装置
【課題】歌唱者が特定の評価を受けた音と同じ特徴を持つ音が再出するタイミングを事前に歌唱者に伝えること。
【解決手段】画像e1は、特定された評価期間が開始する時刻t0から時間T1前の時刻t1となったときに、進行方向r1において時刻t1が規定された位置に表示される。画像e1は、過去の歌唱音声において音高がずれていた音がもうすぐ現れることを歌唱者に伝えるための画像である。画像e2は、「半音高めに」という文字列を示し、進行方向r1において評価期間x18が規定されている位置に表示されている。画像e2は、歌唱者にとって苦手な音が登場するタイミングと、その際歌唱者が実行すべき歌い方とを伝えるための画像である。カラオケ装置は、これらの画像を複数表示させる場合に、強調すべき画像ほど立体的に飛び出させて表示させることで、どの画像に注意すればよいかを歌唱者に分かりやすく伝えることができる。
(もっと読む)
オーディオ信号の重要周波数成分の抽出方法及びその装置、及びこれを利用した低ビット率オーディオ信号の符号化及び/または復号化方法及びその装置
【課題】重要周波数成分を有するオーディオ信号を抽出する方法及びその装置、低ビット率オーディオ信号の符号化/復号化方法及び重要周波数成分を抽出する装置を提供する。
【解決手段】オーディオ信号の重要周波数成分の抽出方法は、周波数領域でのオーディオ信号に対し、心理音響モデルによるSMR値のような信号の知覚的重要度を計算する段階と、知覚的重要度により、マスキング・スレショルド値が周波数領域のオーディオ信号より小さい周波数の信号を、少なくとも一つ以上の第1重要周波数成分として選択する段階と、少なくとも一つ以上の第1重要周波数成分として選択されたオーディオ信号のうち、所定の重み付け値を考慮してスペクトルピークを抽出し、周波数領域のオーディオ信号を符号化するのに使われる少なくとも一つ以上の第2重要周波数成分として選択する段階により、知覚的に重要な周波数成分を符号化し、低ビット率で高音質を提供できる。
(もっと読む)
音声誤検出判別装置、音声誤検出判別方法、およびプログラム
【課題】様々な雑音環境化において音声認識の精度を向上させることが可能な音声誤検出判別装置、音声誤検出判別システム、音声誤検出判別方法、およびプログラムを提供する。
【解決手段】入力信号取得部は、所定方向の音源からの音声を含む周囲音を複数のマイクによりそれぞれ収音した複数の音声信号を取得する。認識結果取得部は、音声信号に基づく音声認識を行った結果検出された、音声信号の音声区間を示す音声区間情報を含む認識結果を取得する。到来率算出部は、それぞれの複数の音声信号の単位時間毎の信号と所定方向とに基づき、単位時間における所定方向からの音声が周囲音に占める割合を示す音声到来率を算出する。誤り検出部は、認識結果と音声到来率とに基づき、音声区間情報が誤検出でないか否かを検出する。これにより、音声認識による音声区間の誤検出を判別できる。
(もっと読む)
表示制御装置
【課題】歌唱者、観客などの人の挙動に応じた演出を、楽曲の進行に伴って表示される歌唱者に対応する画像に対してリアルタイムに施すこと。
【解決手段】本発明の実施形態におけるカラオケ装置1は、カラオケの歌唱中に歌唱者を撮影し、歌唱者の画像を表示画面300に表示させる。カラオケ装置1は、さらに、歌唱者の歌唱の巧拙を評価値として算出し、評価値に応じて歌唱者の画像の大きさを決定し、表示画面300に表示される歌唱者の画像の大きさを変化させるように表示制御を行う。また、カラオケ装置1は、デュエット曲など2人の歌唱者による歌唱においては、双方の評価値の比に応じて、2人の歌唱者の画像の大きさを変化させるように表示制御を行う。
(もっと読む)
評価装置
【課題】歌唱されるべき基準に対して歌唱者が歌唱した音声が沿っている程度に反応するキャラクターを表示すること。
【解決手段】カラオケ装置においては、歌唱音声の評価結果に応じて様々な表情をするキャラクターDが表示される。例えば、評価期間X1における歌唱音声が「普通」と評価された結果、「普通」という感情を表した表情のキャラクターD1が表示される。また、評価期間X2における歌唱音声が「悪い」と評価された結果、「悪い」という感情を表した表情のキャラクターD2が表示される。また、評価期間X3における歌唱音声が「良い」と評価された結果、「良い」という感情を表した表情のキャラクターD3が表示される。カラオケ装置においては、このように、歌唱者の歌唱音声が歌唱されるべき基準に沿っている程度に反応するキャラクターが表示される。
(もっと読む)
音声処理装置
【課題】発話音声の低音を豊かにして聞きやすい音声にするとともに、内容を聞き取りやすい音色にすることが可能な音声処理装置を提供する。
【解決手段】発話者の口腔から口唇を介して空間に放射された発話音声を入力する音声入力部、口唇から耳介へ音声が回り込む経路の伝達特性を持つ第1フィルタ、口唇の放射特性の逆特性を持つ第2フィルタ、口唇内部の口腔から頭蓋の骨肉を介して内耳に到達する経路の伝達特性を持つ第3フィルタを備え、第2フィルタと第3フィルタを直列に接続して第2処理部を形成し、入力された発話音声を第1フィルタおよび前記第2処理部に入力し、出力された音声信号を加算して出力する。
(もっと読む)
マスカ音測定装置、およびサウンドマスキング装置
【課題】マスカ音を測定することができるマスカ音測定装置を実現する。
【解決手段】適応型フィルタ111とポストプロセッサ121は、話者位置音声信号Sbとマスキング位置音声信号Soにより、話者音声に対する適応フィルタ処理を行い、フィルタ処理後の話者位置音声信号Sbである判定用話者音声信号Sbcを音声分析部130へ出力する。適応型フィルタ112とポストプロセッサ122は、原マスカ音信号Smと第1減算信号により、マスカ音に対する適応フィルタ処理を行い、フィルタ処理後の原マスカ音信号Smである判定用マスカ音信号Smcを音声分析部130へ出力する。音声分析部130は、判定用話者音声信号Sbcと判定用マスカ音信号Smcの音量レベルを比較して、マスキング効果の有無を判定する。
(もっと読む)
抑揚判定装置
【課題】歌唱者が楽曲を歌唱したときの音声とその楽曲の内容との関係を考慮して抑揚を判定する
【解決手段】判定対象区間のGMデータにおける最も低い音高と最も高い音高との差分が第1の閾値を超える場合(ステップS712;YES)、制御部10はユーザ歌唱音声データの音量の平均(平均音量)を算出する(ステップS713)。次に制御部10は、判定対象区間における、最高の音高のノートを持つGMデータに対応するユーザ歌唱音声データの音高(最高音高)を特定し(ステップS714)、特定した音高のノートと時間軸で一致するユーザ歌唱音声データにおける音量(最高音高音量)を特定する。制御部10は、平均音量と最高音高音量の差分である差分音量を算出し(ステップS716)、差分音量が第2の閾値を超える場合(ステップS717;YES)、判定対象区間において楽曲の特徴に合わせた抑揚が付けられていると判定する(ステップS718)。
(もっと読む)
21 - 30 / 1,456
[ Back to top ]