
国際特許分類[G10L11/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 15/00〜21/00のグループ中のどれか一つに限定されない音声または音響の特徴量の測定または検出 (1,940)
国際特許分類[G10L11/00]の下位に属する分類
音声信号の有無の検出 (242)
音声信号のピッチの抽出 (206)
音声信号の有声音と無声音の部分の弁別 (36)
国際特許分類[G10L11/00]に分類される特許
31 - 40 / 1,456
音声処理装置
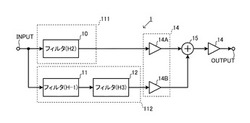
【課題】発話音声の低音を豊かにして聞きやすい音声にするとともに、内容を聞き取りやすい音色にすることが可能な音声処理装置を提供する。
【解決手段】発話者の口腔から口唇を介して空間に放射された発話音声を入力する音声入力部、口唇から耳介へ音声が回り込む経路の伝達特性を持つ第1フィルタ、口唇の放射特性の逆特性を持つ第2フィルタ、口唇内部の口腔から頭蓋の骨肉を介して内耳に到達する経路の伝達特性を持つ第3フィルタを備え、第2フィルタと第3フィルタを直列に接続して第2処理部を形成し、入力された発話音声を第1フィルタおよび前記第2処理部に入力し、出力された音声信号を加算して出力する。
(もっと読む)
マスカ音測定装置、およびサウンドマスキング装置

【課題】マスカ音を測定することができるマスカ音測定装置を実現する。
【解決手段】適応型フィルタ111とポストプロセッサ121は、話者位置音声信号Sbとマスキング位置音声信号Soにより、話者音声に対する適応フィルタ処理を行い、フィルタ処理後の話者位置音声信号Sbである判定用話者音声信号Sbcを音声分析部130へ出力する。適応型フィルタ112とポストプロセッサ122は、原マスカ音信号Smと第1減算信号により、マスカ音に対する適応フィルタ処理を行い、フィルタ処理後の原マスカ音信号Smである判定用マスカ音信号Smcを音声分析部130へ出力する。音声分析部130は、判定用話者音声信号Sbcと判定用マスカ音信号Smcの音量レベルを比較して、マスキング効果の有無を判定する。
(もっと読む)
抑揚判定装置
【課題】歌唱者が楽曲を歌唱したときの音声とその楽曲の内容との関係を考慮して抑揚を判定する
【解決手段】判定対象区間のGMデータにおける最も低い音高と最も高い音高との差分が第1の閾値を超える場合(ステップS712;YES)、制御部10はユーザ歌唱音声データの音量の平均(平均音量)を算出する(ステップS713)。次に制御部10は、判定対象区間における、最高の音高のノートを持つGMデータに対応するユーザ歌唱音声データの音高(最高音高)を特定し(ステップS714)、特定した音高のノートと時間軸で一致するユーザ歌唱音声データにおける音量(最高音高音量)を特定する。制御部10は、平均音量と最高音高音量の差分である差分音量を算出し(ステップS716)、差分音量が第2の閾値を超える場合(ステップS717;YES)、判定対象区間において楽曲の特徴に合わせた抑揚が付けられていると判定する(ステップS718)。
(もっと読む)
カラオケ装置
【課題】各利用者の音域に応じてカラオケ演奏に係る各種制御を実現するカラオケ装置を提供する。
【解決手段】予め定められた所定の演奏曲を出力させると共に、その演奏曲の出力と併行してマイクロフォン40から入力される音声情報に基づいて、その音声情報の入力主体である利用者の音域を判定する音域判定手段90を備えたものであることから、カラオケ演奏を行いながら各利用者の音域を判定することができ、その判定結果を歌唱評価をはじめとする各種制御に応用することができる。すなわち、各利用者の音域に応じてカラオケ演奏に係る各種制御を実現するカラオケ装置16を提供することができる。
(もっと読む)
電子音楽装置及び信号処理特性制御プログラム
【課題】オーディオ信号のパラメータが展開された2次元の表示面に対するユーザ操作に従って、簡単かつ直感的にオーディオ信号処理特性を設定し変更する制御を行う。
【解決手段】この信号処理特性制御システムでは、オーディオ信号sL,sRを分析して2つのパラメータを求め、2次元平面(画面)Pnに展開してタッチパネル12に表示しる。ここで、2次元平面Pn上の点pa,pbがタッチ操作されると、操作点pa,pbに対応して平面Pn上に所定形状の指定パラメータ領域Arを設定し、設定した領域Arに該当するパラメータ範囲に対して所定の信号処理を施す。次いで、タッチ操作点pa,pbが回動されると(Ac1)所定の信号処理特性を変更する。また、指定パラメータ領域Ar内でユーザにより1乃至複数の操作点pc,pd,…が移動されると(Ac2〜Ac5)、この移動操作Ac2〜Ac5を検出し、所定の信号処理特性を制御する。
(もっと読む)
情報処理装置、情報処理方法及びプログラム
【課題】本発明の課題は、不正が困難な方法で、かつ、従来よりも手間のかからない方法で、ユーザの存在認定を行うことを可能とする技術を提供することである。
【解決手段】本発明の情報処理装置は、スピーカから出力される出力音の出力音情報を特定する特定部と、スピーカから出力される出力音を取得することができる範囲に位置するユーザ端末によって取得された取得音の取得音情報を受信する取得音受信部と、出力音が出力された時間帯と取得音が取得された時間帯とが重複する時間帯について、出力音に係る出力音情報と取得音に係る取得音情報とが近似又は合致しているか否かを判定する判定部と、出力音と近似又は合致していると判定された取得音を取得したユーザ端末のユーザに対して、取得音が取得された時間帯、及び、出力音を取得することができる範囲についての存在認定をする認定部と、を備えることを特徴とする。
(もっと読む)
音声判別装置、音声判別方法および音声判別プログラム
【課題】
音響信号から利用者の音声の主要な成分を除外せずに妨害音の影響を除外する音声判別装置を提供することである。
【解決手段】
実施形態の音声判別装置は、利用者の音声を含む第1の音響信号の周波数スペクトルと妨害音を含む第2の音響信号の周波数スペクトルに基づいて、周波数帯域別の重みを付与する重み付与手段と、前記重み付与手段で付与された周波数帯域別の重みを利用して、前記第1の音響信号の周波数スペクトルから特徴量を抽出する特徴抽出手段と、前記特徴抽出手段で抽出された特徴量に基づいて、前記第1の音響信号の音声/非音声を判別する音声/非音声判別手段とを備える。
(もっと読む)
音声判別装置、音声判別方法および音声判別プログラム
【課題】
複数チャンネルのシステム音によって生じるエコーに対しても頑健に動作する音声判別装置を提供することである。
【解決手段】
実施形態の音声判別装置は、複数チャンネルのシステム音を複数のスピーカから再生した再生音およびユーザの音声を含んだ第1の音響信号について音声/非音声を判別する音声判別装置であって、少なくとも前記複数チャンネルのシステム音に基づいて、周波数帯域別の重みを付与する重み付与手段と、前記重み付与手段で付与された周波数帯域別の重みを利用して、前記第1の音響信号に含まれる前記再生音を抑圧した第2の音響信号から特徴量を抽出する特徴抽出手段と、前記特徴抽出手段で抽出された特徴量に基づいて、前記第1の音響信号について音声/非音声を判別する音声/非音声判別手段とを備える。
(もっと読む)
オーディオデータ特徴抽出方法、オーディオデータ照合方法、オーディオデータ特徴抽出プログラム、オーディオデータ照合プログラム、オーディオデータ特徴抽出装置、オーディオデータ照合装置及びオーディオデータ照合システム
【課題】誤りのない確実なオーディオデータの照合を実現することのできるオーディオデータ照合システムを提供する。
【解決手段】本発明のオーディオデータ照合システム1は、既知のオーディオデータから特徴データを抽出するオーディオデータ特徴抽出装置2と、既知のオーディオデータから生成された特徴データに識別情報を登録してデータベース31に格納する特徴データ格納サーバ3と、未知のオーディオデータから特徴データを生成し、データベース31に格納されている特徴データと比較して照合するオーディオデータ照合装置4とを備えていることを特徴とする。
(もっと読む)
分析装置、分析プログラムおよび分析方法
【課題】より簡易に会話スタイルを分析すること。
【解決手段】分析装置10は、取得部14aと、第1の検出部14bと、第2の検出部14cと、抽出部14eと、分析部14fとを有する。取得部14aは、音声データを取得する。第1の検出部14bは、取得された音声データから、第1の確率モデルを用いて、有声音領域および無声音領域を検出する。第2の検出部14cは、検出された有声音領域および無声音領域に基づいて、第2の確率モデルを用いて、音声データにおける発話領域および沈黙領域を検出する。抽出部14eは、検出された発話領域および沈黙領域の会話特性を抽出する。分析部14fは、抽出された会話特性に基づいて、会話スタイルを分析する。
(もっと読む)
31 - 40 / 1,456
[ Back to top ]