
国際特許分類[G10L17/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 話者の同定または識別 (337)
国際特許分類[G10L17/00]に分類される特許
91 - 100 / 337
話者テンプレートを更新する装置及び方法

【課題】本発明の目的は、ユーザに余計な作業を強いることなく、実際の話者認識にかかる処理時間を短く抑えて、話者認識の精度を向上する。
【解決手段】IVR40で、音声応答部41が回線ごとの会話データを取得し、音声認識部42が会話データを音声認識してある特定のデータを作成し、声紋認証装置60で、音声解析部66が特定のデータより音声の特徴を抽出し、言語解析部67が特定のデータからキーワードを抽出する。そして、DB管理部65が、会話の相手の内線番号からメッセージが送られたことのあるメッセージボックスを履歴情報記憶部62を参照して特定し、言語解析部67が抽出したキーワードを会話で話す可能性のあるユーザのメッセージボックスをキーワード情報記憶部63を参照して特定し、テンプレート情報記憶部61のこれらのメッセージボックスを検索範囲として話者テンプレートを検索し更新する。
(もっと読む)
音声変換装置

【課題】直接対面することなく音声によって他者に対する対応を行う場合において、利用者の精神的負荷を軽減することのできる技術を提供する。
【解決手段】音声変換装置1の通話相手情報データベース16には、音声の特徴と音声の変換パターンとが対応付けて記憶されている。ユーザ端末2と通話相手端末3との間で音声通信が開始されると、音声変換装置1は、通話相手端末3から送信されてくる音声データを解析して音声の特徴を抽出し、抽出した特徴を通話相手情報データベース16の記憶内容と照合して、音声変換を行うか否かを判定する。音声変換装置1は、判定結果が肯定的である場合に、抽出された特徴に対応する変換態様で、通話相手端末3から受信される音声データ及びユーザ端末2から受信される音声データの少なくともいずれか一方を変換する。
(もっと読む)
人型ロボット
【課題】特定個人に似顔、似声により情報を伝達する人型ロボットにおいて、音声を発する際の動きのなかに、特定の話者の個性を表現することにより、話者が伝達しようとする愛情などを演出できる人型ロボットを提供する。
【解決手段】特定個人に似顔のロボット本体(1)の内部に搭載したストレージ(3)にあらかじめ特定個人の声を収録し発話するために必要となる五十音等の音素データや特定個人の癖となる動作データ等を登録し、発話時にその音声を制御部(2)内のメインCPUユニット(211)により合成して、スピーカ(26)より出力し、同時にアクチュエータ(9)〜(25)を四肢動作させる。
(もっと読む)
自動来客応対装置、自動来客応対方法、及び応対プログラム
【課題】短時間で音声認識時に必要な待ち受け単語を絞り込むことが可能な自動来客応対装置を提供する。
【解決手段】自動来客応対装置では、音声認識処理において必要な単語辞書はサーバより取得され、テンプレート記憶領域に記憶される。来訪者が来訪した場合、テンプレート記憶領域に単語辞書が記憶されているか否かが判断され(S17)、記憶されていない場合(S17:NO)、取得されたサーバアドレスに基づいてサーバにアクセスし、単語辞書が取得される(S19)。一方、単語辞書が記憶されている場合には、サーバにアクセスすることなく記憶されている単語辞書を取得する(S21)。そして、取得した単語辞書が参照され、来訪者の発声した音声が音声認識処理されて、音声に含まれる単語が特定され、来訪者の身元に関する情報が特定される(S25)。
(もっと読む)
録音装置およびプログラムならびに録音再生システム
【課題】生体情報を用いることにより第三者による録音や再生を制限した、録音装置ならびに録音再生システムを提供する。
【解決手段】音声録音機能を有する録音装置1を、発話者の入力音声を取り込む音声入力部101と、取り込まれた入力音声データに、録音もしくは再生に関する承諾語が含まれているか否かを判定する承諾語判定手段102と、入力音声データに承諾語が含まれていた場合、録音処理機能の実行と並行して、取得された入力音声データの特徴抽出を行い、発話者の生体情報を生成する特徴抽出部103と、生成された発話者の生体情報に基づき暗号鍵を生成する暗号鍵生成部104と、取り込まれた入力音声データを生成された暗号化鍵により暗号化して暗号化済み音声ファイルを生成する暗号化部105と、で構成し、音声録音と承諾語を用いた暗号鍵の生成とを同時並行処理することとした。
(もっと読む)
システム制御方法及び信号処理システム
システム制御方法は、ユーザの環境において入力装置(14-16)を介してユーザにより通信された情報を表す少なくとも1つの信号を取得し、第1のソース(1,2)からの信号は、環境において認知できる形式で利用可能であり、第1のソース(1,2)から生じる情報とユーザから生じる情報との間の遷移が生じることが想定される時点を少なくとも推定し、予想時間に関してシステムによる機能の実行をタイミング調整することを含む。 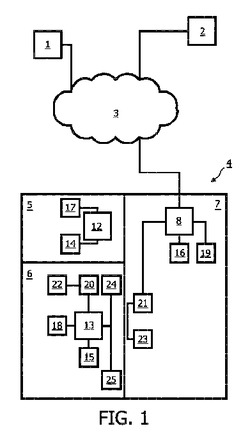 (もっと読む)
(もっと読む)
オーディオアンプ
【課題】歌唱者の声を歌唱者が希望する声質に変更して出力することができるカラオケアンプを提供する。
【解決手段】歌唱者の声の特徴である声質データを記憶した音声データベース16、歌唱音声信号を所望の声質に加工するためのルールを記憶した声質加工ルールデータベース17、声質加工ルールに基づいて歌唱音声信号を加工する声質加工部24を備える。声質加工部24は、歌唱者の声質データおよび歌唱者が希望する声質の声質加工ルールに基づいて、入力された歌唱音声信号の声質を加工して出力する。
(もっと読む)
議事録作成支援装置、議事録作成支援方法、議事録作成支援用プログラム及び議事録作成支援システム
【課題】 話者識別の手間や誤りを簡易なプロセスによって解消し、正確で円滑な議事録の作成及び編集を可能とする。
【解決手段】 話者の音声を入力する音声入力手段11と、入力された音声を文字情報に変換する音声認識手段21と、前記音声から特徴情報を抽出する話者特徴抽出手段22と、抽出した前記特徴情報にもとづき前記文字情報を分類する話者グルーピング手段31と、所定のルールにもとづき、分類された前記文字情報に任意の話者識別情報を割り当てて出力する話者特定手段33と、からなる議事録作成支援装置1及び議事録作成支援システムSys1を構成する。
(もっと読む)
録音装置
【課題】出席者の発言区間や非発言区間を区分して表示するとともに、各区間の雰囲気を一覧表示することができる録音装置を提供する。
【解決手段】録音端末1では、収音部10が収音した音声を、解析部11が会議出席者の発言ごとの区間に区分するとともに、各区間の情況を解析する。再生端末2では、各発言者の発言区間および非発言区間をタイムチャート形式で表示するとともに、各区間の情況を示すマークを表示し、そのマークに基づいて区間を選択して個別に再生できるようにする。
(もっと読む)
複数信号区間推定装置、複数信号区間推定方法、そのプログラムおよび記録媒体
【課題】音声の収録中に話者位置の移動が生じても、同一話者には同一インデックスを付与することを可能とする。
【解決手段】周波数領域変換部110が観測信号を所定長のフレームに順次切り出して当該フレームごとに周波数領域に変換し、音声区間推定部120が周波数領域の観測信号に基づき、各フレームが音声区間に該当するか否かを推定し、到来方向推定部130が周波数領域の観測信号に基づき、当該周波数領域の観測信号の到来方向を各フレームごとに推定し、到来方向分類部140が音声区間に該当すると推定された各フレームを、到来方向の類似性に基づき話者ごとのクラスタに分類する。そして、話者同定部250が所定の時刻までに同一クラスタに分類された各フレームの周波数領域の観測信号に基づき、当該クラスタに係る話者のモデルをクラスタごとに作成し、当該所定の時刻以降の観測信号の話者を各話者のモデルに基づき推定する。
(もっと読む)
91 - 100 / 337
[ Back to top ]