
国際特許分類[G10L17/00]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 話者の同定または識別 (337)
国際特許分類[G10L17/00]に分類される特許
161 - 170 / 337
カラオケネットワークシステム
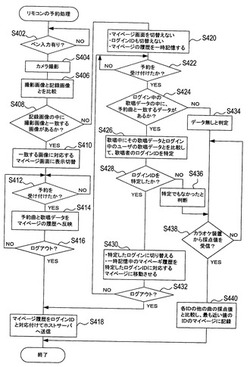
【課題】リモコン端末を利用するユーザの交代を検知して個人用Webページを確実に切り替えることで、前にリモコン端末を利用したユーザの個人用Webページから予約などを誤って行ってしまうことを防ぎ、ログアウトするまでの間にカラオケ装置やリモコン端末側で更新や追加されたユーザ各個人のカラオケ情報やその他の情報を、ホストサーバのデータベースに正しく記録させること。
【解決手段】ユーザの顔画像と先のログイン処理にてメモリ56に記憶した顔画像とを比較する(S406)。顔画像による利用者の確認ができないときには(S408:NO)、ユーザインターフェースを切り替えてサービス提供を継続しながら(S430)、今回の歌唱データと過去の歌唱データとの比較によって利用者の確認を行う(S426)。そして、ログアウト時にマイページ履歴をログインIDと対応付けてカラオケ用ホストサーバ2へ送信する(S418)。
(もっと読む)
音声データ処理システム、音声データ処理方法、及びプログラム

【課題】言語学習用の会話文等を録音してなる音声データにおいて、話者の切り替え位置を検出すること。
【解決手段】音声データ処理システム1において、複数人の音声を一人分ずつ録音してなる音声データを取得する音声データ取得部12と、上記音声データに所定のパターン認識処理を施し、該パターン認識処理の結果に基づいて、上記音声データを音声を発した人ごとの部分に分類する分類部13と、分類部13の分類結果に基づき、上記音声データ中の話者の切り替え位置を決定する位置決定部14と、を含むことを特徴とする。
(もっと読む)
カラオケシステム、カラオケ用リモコン装置
【課題】プライバシーを確保しつつ、リモコン装置を用いた個人情報を検索することが可能なカラオケシステムを提供する。
【解決手段】 カラオケ装置とリモコン装置を有し、リモコン装置は、個人ID情報入力処理を指示するユーザの操作入力に応じて個人ID情報入力画面がディスプレイに表示された状態でマイクからの入力が検出されると個人検索モードを設定して、個人ID情報を利用して楽曲を絞り込む個人演奏履歴検索又は個人ID情報を利用しないで楽曲を絞り込む通常検索の何れか一方の検索手法を選択可能な個人検索モード画面をディスプレイに表示し、個人検索モード画面で個人演奏履歴検索が選択されるとマイクから入力された音声の声紋情報と演奏履歴検索指示情報をカラオケ装置へ送信し、検索結果の情報リストが入力されると該リストをディスプレイに表示して選択させ、選択された楽曲の曲番情報を演奏すべき楽曲の曲番情報として送信する。
(もっと読む)
話者特定装置及び音声認識装置並びに話者特定用プログラム及び音声認識用プログラム
【課題】話者特定処理に必要な計算量や記憶容量等を最小限に抑制しつつ、ある程度の認識率が得られる話者特定装置を提供する。
【解決手段】話者による発話の音響的特徴を示す話者モデルと、当該話者の発話に相当する特徴量信号Soと、を比較し、それらの間の類似度を検出すると共に、検出された類似度と、当該類似度の検出の際に比較された類似度閾値と、を比較して話者特定を行う話者認識部5と、話者の特定に用いられた話者モデルの更新数に基づいて類似度閾値を更新する閾値設定部6と、を備え、閾値設定部6は、当該更新数を用いて類似度閾値を表した閾値関数であって且つ予め設定された閾値関数と、当該更新数と、を用いて更新後の類似度閾値を求める。
(もっと読む)
音声合成装置、方法、プログラム及びその記録媒体、音声案内システム、方法
【課題】音声案内システムにおいて、オペレータの音声から合成音声に切り替わった際の、ユーザが感じる違和感を軽減する技術を提供する。
【解決手段】話者識別部42が、オペレータ16の音声から抽出した特徴量を用いて、オペレータ16の音声に最も当てはまりの良い識別モデルを、予め用意された複数の識別モデルの中から選択する。合成音声生成部43が、選択された識別モデルに対応する音声データを読み出して、オペレータが決定したユーザに提供する音声に関する情報に対応する、オペレータの音声の音質に近い音質を有する合成音声を生成する。
(もっと読む)
音声情報付与方法、音声情報付与装置及びコンピュータプログラム
【課題】アダプタもしくはサーバで画像情報に音声情報を付与する場合、アダプタのマイク等から入力した音声信号をアダプタもしくはサーバで音声認識し、音声信号に含まれる言葉のみでなく、個人を識別する情報等も抽出するようにする。
【解決手段】画像撮影装置に保存された画像情報を取得する(ステップS4001)。次に画像情報に音声情報を付与するために、音声情報のもととなる音声信号をアダプタもしくは画像撮影装置のマイクから入力する(ステップS4003)。次に、入力した音声信号をアダプタで音声認識及び話者照合する(ステップS4004)。次に認識した情報を音声情報に変換する(ステップS4005)。次にステップS4005で作成された音声情報を取得した画像情報に付与・リンクして、音声情報付き画像情報を作成する。
(もっと読む)
車載用カラオケシステム
【課題】 安全運転に支障を来すことなくガイドボーカルを伝達することができるようにする。
【解決手段】 楽曲データを格納する楽曲データベース55と、ガイドボーカルの出力を提供するための歌詞音声データを記憶する歌詞音声データ記憶手段59と、歌唱者が運転者として指定された選曲データに運転者フラグを付帯させて予約待ち行列に登録する予約管理手段58と、運転者フラグが付帯した楽曲の場合には運転席のみに対応した指向性スピーカ23からガイドボーカルを出力し、運転者フラグが付帯していない楽曲の場合にはガイドボーカルの出力を行わないような制御を行う歌詞音声出力制御手段60と、歌詞テロップデータを当該楽曲の演奏データに同期させて表示手段24に出力する再生制御手段61と、を備える。
(もっと読む)
混合モデル生成装置、音処理装置およびプログラム
【課題】混合モデルの生成に必要な記憶容量を削減する。
【解決手段】特徴抽出部42は、登録区間TRにわたって連続する音信号Sを区分した複数の単位区間Tの各々について複数の特徴量xを順次に抽出する。記憶回路30は、ひとつの単位区間Tの複数の特徴量xを記憶する領域A1と、複数の確率分布の加重和である更新混合モデルλBを記憶する領域A2とを含む。モデル生成部52は、領域A1の複数の特徴量xの単位区間モデルλAを単位区間Tごとに生成する。モデル合成部54は、単位区間モデルλAと領域A2の更新混合モデルλBとを合成する。更新部56は、領域A2の更新混合モデルλBを、モデル合成部54が生成した新規な更新混合モデルλBに更新する。更新部56による複数回にわたる更新後の更新混合モデルλBが混合モデルλとして話者認証や話者識別に使用される。
(もっと読む)
音声認証システム及び認証局サーバ
【課題】認証局の照合によって、通話者を特定することができたか否かの認証結果を得られるため、他方の通話者が通話を開始するかどうかを判断することが可能な音声認証システム及び認証局サーバを提供すること。
【解決手段】複数の通信端末と接続された交換機と、交換機と接続され、通信端末を使用する通話者を特定する認証局サーバとを備え、認証局サーバは、通話者の本人属性と、本人属性に対応した通話者の登録音声データとを記録した記録部146と、認証用音声データと登録音声データとを照合し、通話者を特定する音声照合部148と、音声照合部による照合の結果得られた認証結果を交換機に送信する送信部150とを備えることを特徴とする。
(もっと読む)
話者認識システム
【課題】
パワースペクトル情報だけでなく、従来から利用されてこなかった位相情報を話者認識に適用することを特徴とする話者同定あるいは話者照合を行う方法を提供すること。
【解決手段】
ある誰かが発声した音声に含まれる話者の個人性を表す特徴パラメータを抽出し、同じ特徴パラメータをもとに予め構築した話者モデルの中の誰のモデルの音声に相当するかを識別する方法(話者同定)あるいは、ある人の音声であるかどうかを判定する方法(話者照合)において、音声波形に含まれる話者の特徴を表す従来に使用されていなかった位相特徴パラメータの抽出方法と従来の特徴パラメータ抽出法を併用して、話者同定あるいは話者照合を行う。
(もっと読む)
161 - 170 / 337
[ Back to top ]