
仮想マシン環境におけるアプリケーション・プログラム・インタフェースの最適化の方法および装置

【課題】仮想マシン(VM)環境におけるマネージド・ランタイム・アプリケーションの性能を最適化するために、下層のプロセッサの機能を使用可能にする。
【解決手段】1つ以上のプロセッサ命令に関連するプロセッサ命令スタブ(PIPS)が生成される。この「スタブ」は、プログラムの実行時に種々のタスクを実行するために提供される、動的に生成されるコードの一部を指す。そして、生成されたPIPSに基づいて、1つ以上のプロセッサ命令を実行するために最適化アプリケーション・プログラム・インタフェースが生成される。
【解決手段】1つ以上のプロセッサ命令に関連するプロセッサ命令スタブ(PIPS)が生成される。この「スタブ」は、プログラムの実行時に種々のタスクを実行するために提供される、動的に生成されるコードの一部を指す。そして、生成されたPIPSに基づいて、1つ以上のプロセッサ命令を実行するために最適化アプリケーション・プログラム・インタフェースが生成される。
【発明の詳細な説明】
【技術分野】
【0001】
本開示内容は、概して、マネージド・ランタイム環境に関する。本開示内容は、特に、マネージド・アプリケーション・プログラム・インタフェース(APIs)の最適化の方法および装置に関する。
【背景技術】
【0002】
マネージド・コードは、マネージド・ランタイム環境(MRTE)(例:Microsoft(登録商標)社のC#(「Cシャープ」)またはVisual Basic .Netによって書かれた全てのコード)の制御下で実行するコードである。これに対して、アンマネージド・コードは、MRTEの外側(例:COMコンポーネントおよびWIN32API関数)において実行するコードである。概して、マネージド・コードは、ランタイム時にコンポーネントおよびアプリケーションをサポートするために使用され、アンマネージド・コードは、プラットフォーム(すなわち、プロセッサ)との下位レベルの相互作用をサポートするために使用される。アプリケーションがJava(登録商標)(登録商標)仮想マシン(JVM)およびMicrosoft .Netによって提供される共通言語ランタイム(CLR)のようなMRTE上における動作に移行するにつれて、仮想マシンは、アプリケーションを抽象化してプロセッサへの依存を取り除いていく(すなわち、マネージド・ランタイム・アプリケーションは、仮想マシンにより大きく依存するようになり、プロセッサに対する依存は小さくなる)。
【0003】
現在、Intel(登録商標)インテグレーテッド・パフォーマンス・プリミティブ(IPP)のようなアンマネージド・ソフトウェア・ライブラリ関数は、概して、Intel Pentium(登録商標)テクノロジおよび/またはIntel Itanium(登録商標)テクノロジのうちの1つ以上を使用して実装されたプロセッサ上のアンマネージド環境における実行に最適化されている。アンマネージド・ソフトウェア・ライブラリ関数は、Intelプロセッサによって提供されるストリーミング・シングル・インストラクション/マルチプル・データ(SIMD)拡張(SSE)命令、SSE2命令、および/またはマルチメディア拡張(MMX)命令のようなプロセッサ特有の命令群を使用したカスタムハンドな最適化コードを書くことによって、特定のプロセッサアーキテクチャ上における動作に対して更に最適化されうる。例えば、文字列比較関数は、アンマネージド・コードによって実装され、SSE2命令を使用したカスタムハンドな最適化コードによって最適化されうる。アンマネージド・コードとは対照的に、マネージド・コードをカスタムハンドに最適化する方法が存在しないため、マネージド・コードは、アンマネージド・コードと同様の方法では特定のプロセッサアーキテクチャに対して最適化されない。例えば、一般的に、マネージドAPIsは、最適化に関してジャスト・イン・タイム(JIT)コンパイラに完全に依存している。その結果、マネージド・ランタイム・アプリケーションは、下層のプロセッサ上での実行において、オーディオ処理、ビデオ処理、画像処理、音声認識、暗号などの機能を使用可能にし、かつ、最適化する、プロセッサ特有の最適化命令群を使用することができない。
【図面の簡単な説明】
【0004】
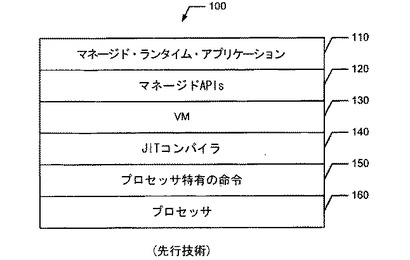
【図1】既存のシステムに構成されたマネージド・ランタイム環境(MRTE)システムのアーキテクチャ階層の一例を示すブロック図である。
【0005】
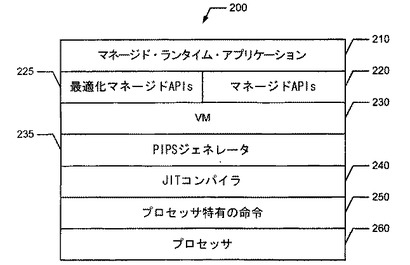
【図2】本明細書で開示される発明の一実施形態により構成されるプロセッサ命令プロキシ・スタブ(PIPS)システムを含む、MRTEシステムの一例におけるアーキテクチャ階層の一例を示すブロック図である。
【0006】
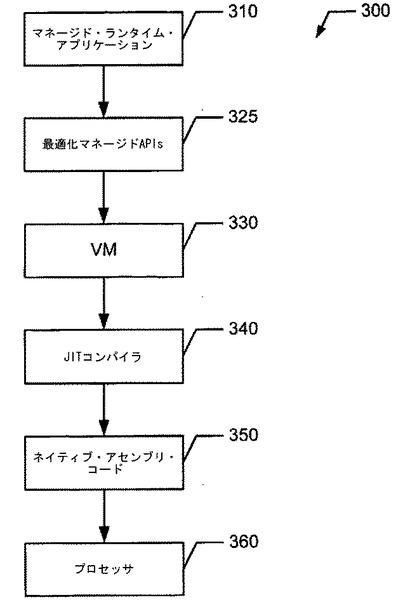
【図3】プロセッサ命令プロキシ・スタブ(PIPS)システムの一例を示すブロック図である。
【0007】
【図4】図3に示すPIPSシステムの一例によって最適化されうるアンマネージド・コードの一例の高級プログラミング言語による表現を示す。
【0008】
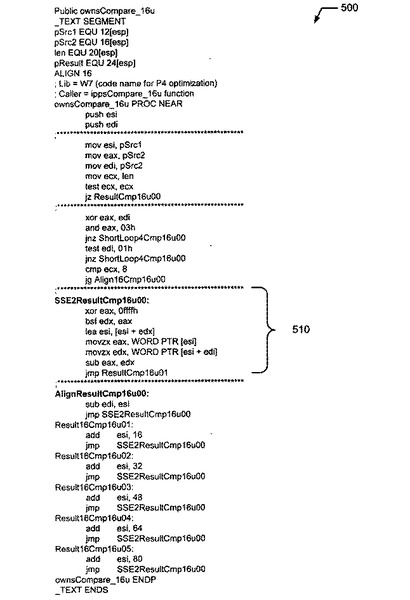
【図5】図4に示す高級プログラミング言語に相当し、ネイティブ・アセンブリ・コードを最適化するPIPSを含む、ネイティブ・アセンブリ・コードの一例のコード表現を示す。
【0009】
【図6】図3に示すPIPSシステムの一例を実装するために実行されうる、マシンアクセス可能な命令群の一例を示す第1のフロー図である。
【図7】図3に示すPIPSシステムの一例を実装するために実行されうる、マシンアクセス可能な命令群の一例を示す第2のフロー図である。
【0010】
【図8】図3に示すPIPSシステムの一例を実装するために使用されうる、プロセッサシステムの一例を示すブロック図である。
【発明を実施するための形態】
【0011】
図1を参照すると、マネージド・ランタイム環境(MRTE)システム100のアーキテクチャ階層は、概して、マネージド・ランタイム・アプリケーション110と、1つ以上のマネージド・アプリケーション・プログラム・インタフェース(APIs)120と、仮想マシン(VM)130と、コンパイラ140と、プロセッサ特有の命令群150と、プロセッサ160とを有する。本明細書で使用される「アプリケーション」は、データの操作を行う1つ以上の方法、プログラム、関数、ルーチン、またはサブルーチンを指す。
【0012】
概して、マネージド・ランタイム・アプリケーション110は、MRTEにおいて種々のサービスを提供するためにプログラマによって書かれる。マネージド・ランタイム・アプリケーション110のソースコードは、例えば、C#、Visual Basic .Net、および/またはその他の適用可能ないかなるオブジェクト指向プログラミング言語によって書かれてもよい。
【0013】
Microsoft .Netフレームワーク・クラス・ライブラリまたはJava(登録商標)クラス・ライブラリのようなマネージドAPIs120は、マネージド・ランタイム・アプリケーション110のソースコードを、それぞれMicrosoft中間言語(MSIL)またはJava(登録商標)バイトコードに変換(すなわち、コンパイル)する。マネージドAPIs120は、マネージド・ランタイム・アプリケーション110とVM130の間のインタフェースとして動作する。
【0014】
VM130は、ガーベッジコレクション、メモリ管理、およびコードとロールベースのセキュリティのようなサービスをマネージドAPIs120に提供することによって、マネージド・ランタイム・アプリケーション110を管理する抽象的なプロセッサを動作させる。例えば、プロセッサに関する知識を持たないVM130は、Microsoft共通言語ランタイムまたはJava(登録商標)仮想マシンでもよい。マネージドAPIs120およびVM130は、MISLコードまたはJava(登録商標)バイトコードが特定のプロセッサをターゲットとしないために、すべての特定のプラットフォームに対して依存せずに動作する。それに従って、ジャスト・イン・タイム(JIT)コンパイラのようなコンパイラ140は、MISLコードまたはJava(登録商標)バイトコードを、マネージドAPIs120からプロセッサ160によって実行されうるネイティブ・アセンブリ・コードに変換(すなわち、再コンパイル)する。
【0015】
プロセッサ160は、Intel Pentium(登録商標)テクノロジ、Intel Itaniumテクノロジ、および/またはIntelパーソナル・インターネット・クライアント・アーキテクチャ(PCA)テクノロジのうちの1つ以上を使用して実装されてもよい。プロセッサ160は、暗号、マルチメディア、オーディオコーデック、ビデオコーデック、画像コーディング、画像処理、信号処理、文字列処理、音声圧縮、コンピュータビジョンなどのソフトウェア・ライブラリ関数をMRTEシステム100に提供する、SSE命令群、SSE2命令群、MMX命令群、および/またはその他の適用可能な命令群のような、プロセッサ特有の命令群150を実行することが可能であってもよい。
【0016】
しかし、上述のように、アンマネージド・ソフトウェア・ライブラリ関数(すなわち、プロセッサ特有の命令群150)は、プロセッサ160に対して最適化されうるが、マネージド・コード(すなわち、マネージドAPIs120)は、これまでマネージド・コード関数をカスタムハンドで最適化する方法が存在しないため、アンマネージド・ソフトウェアと同様の方法では、ある特定のプロセッサアーキテクチャに対して最適化されない。すなわち、マネージド・ランタイム・アプリケーション110に対応するマネージドAPIs120は、最適化に関して完全にJITコンパイラ140に依存しており、また、JITコンパイラ140は、プロセッサ特有の最適化を行うことができなかった。このように、従来のシステムでは、VM130が下層のプロセッサ160の一定のプロセッサ特有の命令群150をサポートしていなかったために、下層のプロセッサ160は、VM130によって提供されるサービスを使用することができず、また、マネージド・ランタイム・アプリケーション110は、下層のプロセッサ160によって提供される機能を使用することができなかった。
【0017】
図2の例は、マネージド・ランタイム・アプリケーション210、1つ以上のAPIs220、1つ以上の最適化マネージドAPIs225、VM230、PIPSジェネレータ235、コンパイラ240、プロセッサ特有の命令群250、およびプロセッサ260を含むプロセッサ命令プロキシ・スタブ(PIPS)システム200を有する、MRTEのアーキテクチャ階層を示す。本明細書において使用される「スタブ」は、プログラムの実行中に種々のタスクを実行するために提供される動的に生成されるコードの一部を指す。
【0018】
一般的に、PIPSジェネレータ235は、下層のプロセッサ260上におけるマネージド・ランタイム・アプリケーション210の実行を最適化するために、PIPS(例:図5のPIPS510)と呼ばれるコードの一部または命令のセットを生成する。マネージド・ランタイム・アプリケーション210がインストールされると、例えば、PIPSジェネレータ235は、プロセッサ特有の命令群250に基づいて、PIPSを生成する。更に、PIPSジェネレータ235は、マネージド・ランタイム・アプリケーション210によって使用される最適化マネージドAPIs225を作成するために、PIPSをあるマネージドAPIs220に挿入する。下記に詳細に説明するように、マネージド・ランタイム・アプリケーション210が実行されている間、最適化マネージドAPIs225は、アンマネージド・コード(すなわち、プロセッサ特有の命令群250)をマネージド・コード(すなわち、マネージド・ランタイム・アプリケーション210)に書き換えることなく、下層のプロセッサ260の性能を最適化する。最適化マネージドAPIs225は、メモリ(例:図8のメモリ1030)に保存され、MRTEにおけるマネージド・ランタイム・アプリケーション210の実行時にリコールされる。その結果、下層のプロセッサ260上におけるマネージド・ランタイム・アプリケーション210の性能を最適化するために、下層のプロセッサ260の機能が使用可能にされうる。
【0019】
図2のPIPSジェネレータ235はPIPSシステム200内の独立したブロックとして図示されるが、PIPSジェネレータ235によって実行される機能は、VM230および/またはJITコンパイラ240内に組み込まれてもよい。
【0020】
図3を参照すると、PIPSシステム300の例は、MRTEにおいてマネージド・ランタイム・アプリケーション310を実行するために、マネージド・ランタイム・アプリケーション310、1つ以上の最適化マネージドAPIs325、VM330、JITコンパイラ340、ネイティブ・アセンブリ・コード350、およびプロセッサ360を有する。VM330は、マネージド・ランタイム・アプリケーション310を実行するために、複数の異なるプロセッサに対して互換性があるプロセッサ命令群を実行してもよい。しかし、一般的に、VM330は、最適化マネージドAPIs325なしでは使用することができない機能を使用可能にするために下層のプロセッサ360の特定のプロセッサ特有の命令群を実行することはしない。これに対して、PIPSシステム300によってマネージド・ランタイム・アプリケーション310が実行されている間、例えば、JITコンパイラ340は、ネイティブ・アセンブリ・コード350(例:図5のネイティブ・アセンブリ・コード500)を生成するために、最適化マネージドAPIs325をコンパイルする。特に、マネージド・ランタイム・アプリケーション310のインストール時に、最適化マネージドAPIs325を生成するためにPIPSジェネレータ235がPIPSを挿入したため、JITコンパイラ340は、ネイティブ・アセンブリ・コード350を更に最適化することなく、ネイティブ・アセンブリ・コード350を単純にコンパイルして実行する。換言すると、PIPSは、下層のプロセッサ360上においてマネージド・ランタイム・アプリケーション310を実行するために、マネージド・ランタイム・アプリケーション310のマネージドAPIsを予め最適化(すなわち、最適化マネージドAPIs325)した。これにより、JITコンパイラ340がアンマネージド・コード(例:図2のプロセッサ特有の命令群250)をマネージド・コード(すなわち、マネージド・ランタイム・アプリケーション310)に書き換えることなく、最適化マネージドAPIs325は、下層のプロセッサ360の性能を最適化する。その結果、ネイティブ・アセンブリ・コード350は、下層のプロセッサ360におけるマネージド・ランタイム・アプリケーション310の性能を最適化するように、カスタマイズされる。
【0021】
図4の例では、文字列比較関数400は、アンマネージドの高級言語のコードによって実装される。概して、文字列比較関数400は、上述のIntelプロセッシング・テクノロジのうちの1つ以上を使用して実装されたプロセッサにおけるSSE2命令群のようなプロセッサ特有の命令群を使用したカスタムハンドな最適化コーディングによって、C言語ルーチンとして最適化される。しかし、C#またはJava(登録商標)の比較関数コードのようなマネージド・コードを特定のプロセッシング・アーキテクチャに対してカスタムハンドに最適化する方法は存在しない。
【0022】
図2および図3と関連して説明されたように、下層のプロセッサ360上における文字列比較関数400の性能を最適化するPIPS510を含む、ネイティブ・アセンブリ・コード500の一部の例が、図5に示される。特に、ネイティブ・アセンブリ・コード500は、PIPSジェネレータ235によって生成されたPIPS510を有する。例えば、PIPSジェネレータ235は、文字列比較関数400のインストール時にPIPS510を生成するために、Microsoft .NETによって提供されるネイティブ・マーシャリング言語(ML)コードを使用してもよい。PIPS510に基づいて、PIPSジェネレータ235は、マネージド・ランタイム・アプリケーション310に相当する最適化マネージドAPIs325を生成する。JITコンパイラ340は、図5に示すように、実行する下層のプロセッサ360に対するPIPS510を含む、文字列比較関数に対応するネイティブ・アセンブリ・コード500をコンパイルする。文字列比較関数400がランタイム時に開始されたとき、VM330は、ネイティブ・アセンブリ・コード500を生成するために、JITコンパイラ340に対して、最適化マネージドAPIs325を取り込む。PIPSジェネレータ235が予めPIPS510を最適化マネージドAPIs325に挿入したため、JITコンパイラ340は、最適化マネージドAPIs325を更に最適化することなく、最適化マネージドAPIs325をコンパイルして実行する。その結果、下層のプロセッサ360のプロセッサ特有の命令群250(すなわち、アンマネージド・コード)がPIPS510によってVMレイヤにまで抽象化されたため、マネージド・ランタイム・アプリケーション310は、VM330によって提供されるサービス(例:ガーベッジコレクション、メモリ管理、および/またはコードとロールベースのセキュリティ)、および、下層のプロセッサ360の機能の両方の利益を得ることができる。換言すると、最適化マネージドAPIs325は、マネージド・ランタイム・アプリケーション310を動作させるために、下層のプロセッサ360の機能を使用可能にするプロセッサ特有の命令群を使用可能にすることができる。
【0023】
フロー図600および700は、図6および図7にそれぞれ図示されるマネージドAPIを最適化するためにプロセッサによって実行されうる、マシンアクセス可能な命令群を示す。通常の技術を有する当業者は、この命令群が揮発性または非揮発性のメモリまたはその他の大容量ストレージデバイス(例:フロッピー(登録商標)ディスク、CD、およびDVD)のようなコンピュータによってアクセス可能な全ての媒体に保存された全てのプログラミングコードの使用による多くの異なる方法によって実装されうることを、理解するであろう。例えば、マシンアクセス可能な命令群は、消去可能プログラマブル・リード・オンリー・メモリ(EPROM)、リード・オンリー・メモリ(ROM)、ランダム・アクセス・メモリ(RAM)、磁気メディア、光メディア、および/またはその他の適用可能なタイプの媒体のような、マシンアクセス可能な媒体に組み込まれてもよい。あるいは、マシンアクセス可能な命令は、プログラマブル・ゲート・アレイおよび/または特定用途向け集積回路(ASIC)に組み込まれてもよい。更に、図6および図7には動作の特定の順番が図示されているが、通常の技術を有する当業者は、これらの動作が他の順番において実行されうることを理解するであろう。また、フロー図600および700は、図2および図5に関連して、マネージドAPIsを最適化する方法の一例として提供および説明されるのみである。
【0024】
図6の例では、フロー図600は、PIPSジェネレータ235が下層のプロセッサ260のプロセッサ特有の命令群250に関連するPIPS510を生成する、ブロック610から開始する。例えば、PIPSジェネレータ235は、マネージド・ランタイム・アプリケーション210のインストール中に、下層のプロセッサ260に相当するプロセッサ識別子に基づいて、PIPS510を生成してもよい。上述の通り、プロセッサ特有の命令群250は、下層のプロセッサ260上におけるマネージド・ランタイム・アプリケーション210の性能を最適化するために、プロセッサ特有の命令を使用することなくして使用できない、オーディオ処理、ビデオ処理、画像処理、音声認識、暗号などのような、下層のプロセッサ260の機能を使用可能にする。ブロック620において、PIPSジェネレータ235は、PIPS510に基づいて、最適化マネージドAPIs225を生成する。特に、PIPSジェネレータ235は、PIPS510をマネージド・ランタイム・アプリケーション210に相当するあるマネージドAPIs220に挿入する。PIPSジェネレータ235は、下層のプロセッサ260においてマネージド・ランタイム・アプリケーション210が実行されている間、最適化マネージドAPIs225がJITコンパイラ240から使用可能となるように、最適化マネージドAPIs225を保存する。
【0025】
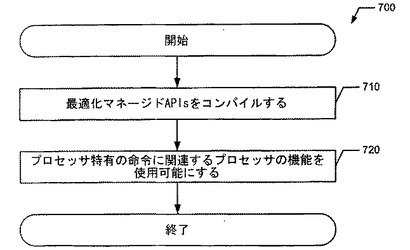
図7の例では、フロー図700は、JITコンパイラ240がマネージド・ランタイム・アプリケーション210に相当する最適化マネージドAPIs225をコンパイルして実行する、ブロック710から開始する。上述のように、PIPSジェネレータ235がプロセッサ特有の命令群250に関連するPIPS510を最適化マネージドAPIs225に予め挿入したため、JITコンパイラ240は、最適化マネージドAPIs225を更に最適化することなく、最適化マネージドAPIs225をコンパイルしうる。すなわち、PIPS510は、最適化マネージドAPIs225によって、下層のプロセッサ260上で実行するためにマネージド・ランタイム・アプリケーション210をカスタムハンドで最適化する。ブロック640において、JITコンパイラ240は、プロセッサ特有の命令群250に相当する下層のプロセッサ260の機能を使用可能にする。VM230によって提供されるガーベッジコレクション、メモリ管理、およびコードとロールベースのセキュリティのようなサービスに加えて、マネージド・ランタイム・アプリケーション210は、下層のプロセッサ260上で実行される間、暗号、マルチメディア、オーディオコーデック、ビデオコーデック、画像コーディング、画像処理、信号処理、音声圧縮、コンピュータビジョンなどの最適化マネージドAPIs225によってマネージド・ランタイム・アプリケーション210に提供される、ソフトウェア・ライブラリ関数を使用しうる。その結果、最適化マネージドAPIs225は、マネージド・ランタイム・アプリケーション210が、プロセッサ特有の命令を使用することなくして使用できない、または、他のプロセッサにおいては非効率的である下層のプロセッサ260の機能を使用可能にする、プロセッサ特有の命令群250を実行することを可能にする。更に、最適化マネージドAPIs225は、ネイティブ・アセンブリ・コード500によって、下層のプロセッサ260におけるマネージド・ランタイム・アプリケーション210の性能をカスタムハンドに最適化する。
【0026】
本明細書において開示される方法および装置は、欧州コンピュータ・マネージメント・アソシエーション(ECMA)共通言語インフラストラクチャ(CLI)(second edition, December 2002)およびECMA C#言語仕様(second edition, December 2002)の実装のソースコードに適する。しかし、通常の技術を有する当業者は、開示内容が他のランタイム環境におけるソースコードに対しても適用可能であることを理解するであろう。
【0027】
図8は、本明細書において開示される方法および装置の実装に適合するプロセッサシステム1000の一例を示すブロック図である。プロセッサシステム1000は、デスクトップコンピュータ、ラップトップコンピュータ、ノートブックコンピュータ、パーソナルデジタルアシスタント(PDA)、サーバ、インターネットアプライアンス、またはその他いかなるタイプのコンピュータデバイスでもよい。
【0028】
図8に示されるプロセッサシステム1000は、メモリコントローラ1012および入力/出力(I/O)コントローラ1014を含む、チップセット1010を有する。よく知られているように、チップセットは、一般的に、プロセッサ1020からアクセス可能である、または、プロセッサ1020によって使用されるメモリおよびI/O管理機能を提供し、一般的な目的および/または特定の目的のレジスタ、タイマーなども提供する。プロセッサ1020は、1つ以上のプロセッサを使用して実装される。例えば、プロセッサ1020は、Intel Pentium(登録商標)テクノロジ、Intel Itaniumテクノロジ、Intel Centrino(登録商標)テクノロジおよび/またはIntel XScale(登録商標)テクノロジのうちの1つ以上を使用して実装されてもよい。あるいは、他のプロセッシング技術がプロセッサ1020を実装するために使用されてもよい。プロセッサ1020は、第1レベル・ユニファイド・キャッシュ(L1)、第2レベル・ユニファイド・キャッシュ(L2)、第3レベル・ユニファイド・キャッシュ(L3)、および/または通常の技術を有する当業者が認識するその他の適用しうる全ての構造を使用して実装されうる、キャッシュ1022を有する。
【0029】
従来技術のように、メモリコントローラ1012は、プロセッサ1020がバス1040によって揮発性メモリ1032および非揮発性メモリ1034を含むメインメモリ1030にアクセスして通信できるようにする機能を実行する。揮発性メモリ1032は、同期型ダイナミック・ランダム・アクセス・メモリ(SDRAM)、ダイナミック・ランダム・アクセス・メモリ(DRAM)、RAMBUSダイナミック・ランダム・アクセス・メモリ(RDRAM)、および/またはその他全てのタイプのランダム・アクセス・メモリ・デバイスによって実装されてもよい。非揮発性メモリ1034は、フラッシュメモリ、リード・オンリー・メモリ(ROM)、電気的消去可能リード・オンリー・メモリ(EEPROM(登録商標))、および/またはその他全てのタイプのメモリデバイスを使用して実装されてもよい。
【0030】
プロセッサシステム1000は、バス1040に接続されたインタフェース回路1050も有する。インタフェース回路1050は、イーサネット(登録商標)・インタフェース、ユニバーサル・シリアル・バス(USB)、第3世代入力/出力インタフェース(3GIO)インタフェース、および/またはその他適用可能な全てのタイプのインタフェースのような、いかなる従来のインタフェースの標準を使用して実装されてもよい。
【0031】
1つ以上の入力デバイス1060は、インタフェース回路1050に接続される。1つまたは複数の入力デバイス1060は、ユーザによるプロセッサ1020に対するデータおよびコマンドの入力を可能にする。例えば、1つまたは複数の入力デバイス1060は、キーボード、マウス、タッチセンシティブディスプレイ、トラックパッド、トラックボール、isopoint、および/または音声認識システムによって実装されてもよい。
【0032】
1つ以上の出力デバイス1070もまた、インタフェース回路1050に接続される。例えば、1つまたは複数の出力デバイス1070は、ディスプレイデバイス(例:発光ディスプレイ(LED)、液晶ディスプレイ(LCD)、陰極線管(CRT)ディスプレイ、プリンタ、および/またはスピーカ)によって実装されてもよい。このように、インタフェース回路1050は、一般的には、他のデバイスの中でも特に、グラフィックスドライバカードを有する。
【0033】
プロセッサシステム1000は、ソフトウェアおよびデータを保存する1つ以上の大容量ストレージデバイス1080も有する。そのような1つまたは複数の大容量ストレージデバイス1080の例は、フロッピー(登録商標)ディスクとドライブ、ハードディスクドライブ、コンパクトディスクとドライブ、およびデジタル多用途ディスク(DVD)とドライブを含む。
【0034】
インタフェース回路1050は、ネットワークによる外部コンピュータとのデータの交換を促進するモデムまたはネットワークインタフェースカードのような通信デバイスも含む。プロセッサシステム1000とネットワーク間の通信リンクは、イーサネット(登録商標)接続、デジタル加入者回線(DSL)、電話線、携帯電話システム、同軸ケーブルなどのような、いかなるタイプのネットワーク接続でもよい。
【0035】
1つまたは複数の入力デバイス1060、1つまたは複数の出力デバイス1070、1つまたは複数の大容量ストレージデバイス1080、および/またはネットワークへのアクセスは、概して、従来技術の手法に沿ってI/Oコントローラ1014によってコントロールされる。特に、I/Oコントローラ1014は、プロセッサ1020がバス1040およびインタフェース回路1050によって1つまたは複数の入力デバイス1060、1つまたは複数の出力デバイス1070、1つまたは複数の大容量ストレージデバイス1080、および/またはネットワークにアクセスできるようにする機能を実行する。
【0036】
図8に示されるコンポーネントはプロセッサシステム1000内の独立したブロックとして図示されるが、これらのブロックのうちのいくつかによって実行される機能は、1つの半導体回路内に組み込まれてもよく、または、2つ以上の独立した集積回路を使用して実装されてもよい。例えば、メモリコントローラ1012およびI/Oコントローラ1014は、チップセット1010内の独立したブロックとして図示されるが、通常の技術を有する当業者は、メモリコントローラ1012およびI/Oコントローラ1014は1つの半導体回路に組み込まれうることを理解するであろう。
【0037】
本明細書ではある一定の方法、装置、および製品の例が説明されるが、本発明の特許請求の範囲は、これらに限定されない。本発明の範囲は、逐語的にまたは均等論によって添付の特許請求の範囲に収まる全ての方法、装置、製品に及ぶ。例えば、本明細書は、他のコンポーネントの中でもハードウェア上で実行されるソフトウェアまたはファームウェアを含むシステム例を開示するが、これらのシステムは、単に本発明を説明するためのものであって本発明を限定するものではない。特に、全ての開示されたハードウェア、ソフトウェア、および/またはファームウェアコンポーネントは、ハードウェア内に独占的に組み込まれてもよく、ソフトウェアに独占的に組み込まれてもよく、ファームウェアに独占的に組み込まれてもよく、または、ハードウェア、ソフトウェア、および/またはファームウェアの組み合わせに組み込まれてもよいことが意図されている。
【技術分野】
【0001】
本開示内容は、概して、マネージド・ランタイム環境に関する。本開示内容は、特に、マネージド・アプリケーション・プログラム・インタフェース(APIs)の最適化の方法および装置に関する。
【背景技術】
【0002】
マネージド・コードは、マネージド・ランタイム環境(MRTE)(例:Microsoft(登録商標)社のC#(「Cシャープ」)またはVisual Basic .Netによって書かれた全てのコード)の制御下で実行するコードである。これに対して、アンマネージド・コードは、MRTEの外側(例:COMコンポーネントおよびWIN32API関数)において実行するコードである。概して、マネージド・コードは、ランタイム時にコンポーネントおよびアプリケーションをサポートするために使用され、アンマネージド・コードは、プラットフォーム(すなわち、プロセッサ)との下位レベルの相互作用をサポートするために使用される。アプリケーションがJava(登録商標)(登録商標)仮想マシン(JVM)およびMicrosoft .Netによって提供される共通言語ランタイム(CLR)のようなMRTE上における動作に移行するにつれて、仮想マシンは、アプリケーションを抽象化してプロセッサへの依存を取り除いていく(すなわち、マネージド・ランタイム・アプリケーションは、仮想マシンにより大きく依存するようになり、プロセッサに対する依存は小さくなる)。
【0003】
現在、Intel(登録商標)インテグレーテッド・パフォーマンス・プリミティブ(IPP)のようなアンマネージド・ソフトウェア・ライブラリ関数は、概して、Intel Pentium(登録商標)テクノロジおよび/またはIntel Itanium(登録商標)テクノロジのうちの1つ以上を使用して実装されたプロセッサ上のアンマネージド環境における実行に最適化されている。アンマネージド・ソフトウェア・ライブラリ関数は、Intelプロセッサによって提供されるストリーミング・シングル・インストラクション/マルチプル・データ(SIMD)拡張(SSE)命令、SSE2命令、および/またはマルチメディア拡張(MMX)命令のようなプロセッサ特有の命令群を使用したカスタムハンドな最適化コードを書くことによって、特定のプロセッサアーキテクチャ上における動作に対して更に最適化されうる。例えば、文字列比較関数は、アンマネージド・コードによって実装され、SSE2命令を使用したカスタムハンドな最適化コードによって最適化されうる。アンマネージド・コードとは対照的に、マネージド・コードをカスタムハンドに最適化する方法が存在しないため、マネージド・コードは、アンマネージド・コードと同様の方法では特定のプロセッサアーキテクチャに対して最適化されない。例えば、一般的に、マネージドAPIsは、最適化に関してジャスト・イン・タイム(JIT)コンパイラに完全に依存している。その結果、マネージド・ランタイム・アプリケーションは、下層のプロセッサ上での実行において、オーディオ処理、ビデオ処理、画像処理、音声認識、暗号などの機能を使用可能にし、かつ、最適化する、プロセッサ特有の最適化命令群を使用することができない。
【図面の簡単な説明】
【0004】
【図1】既存のシステムに構成されたマネージド・ランタイム環境(MRTE)システムのアーキテクチャ階層の一例を示すブロック図である。
【0005】
【図2】本明細書で開示される発明の一実施形態により構成されるプロセッサ命令プロキシ・スタブ(PIPS)システムを含む、MRTEシステムの一例におけるアーキテクチャ階層の一例を示すブロック図である。
【0006】
【図3】プロセッサ命令プロキシ・スタブ(PIPS)システムの一例を示すブロック図である。
【0007】
【図4】図3に示すPIPSシステムの一例によって最適化されうるアンマネージド・コードの一例の高級プログラミング言語による表現を示す。
【0008】
【図5】図4に示す高級プログラミング言語に相当し、ネイティブ・アセンブリ・コードを最適化するPIPSを含む、ネイティブ・アセンブリ・コードの一例のコード表現を示す。
【0009】
【図6】図3に示すPIPSシステムの一例を実装するために実行されうる、マシンアクセス可能な命令群の一例を示す第1のフロー図である。
【図7】図3に示すPIPSシステムの一例を実装するために実行されうる、マシンアクセス可能な命令群の一例を示す第2のフロー図である。
【0010】
【図8】図3に示すPIPSシステムの一例を実装するために使用されうる、プロセッサシステムの一例を示すブロック図である。
【発明を実施するための形態】
【0011】
図1を参照すると、マネージド・ランタイム環境(MRTE)システム100のアーキテクチャ階層は、概して、マネージド・ランタイム・アプリケーション110と、1つ以上のマネージド・アプリケーション・プログラム・インタフェース(APIs)120と、仮想マシン(VM)130と、コンパイラ140と、プロセッサ特有の命令群150と、プロセッサ160とを有する。本明細書で使用される「アプリケーション」は、データの操作を行う1つ以上の方法、プログラム、関数、ルーチン、またはサブルーチンを指す。
【0012】
概して、マネージド・ランタイム・アプリケーション110は、MRTEにおいて種々のサービスを提供するためにプログラマによって書かれる。マネージド・ランタイム・アプリケーション110のソースコードは、例えば、C#、Visual Basic .Net、および/またはその他の適用可能ないかなるオブジェクト指向プログラミング言語によって書かれてもよい。
【0013】
Microsoft .Netフレームワーク・クラス・ライブラリまたはJava(登録商標)クラス・ライブラリのようなマネージドAPIs120は、マネージド・ランタイム・アプリケーション110のソースコードを、それぞれMicrosoft中間言語(MSIL)またはJava(登録商標)バイトコードに変換(すなわち、コンパイル)する。マネージドAPIs120は、マネージド・ランタイム・アプリケーション110とVM130の間のインタフェースとして動作する。
【0014】
VM130は、ガーベッジコレクション、メモリ管理、およびコードとロールベースのセキュリティのようなサービスをマネージドAPIs120に提供することによって、マネージド・ランタイム・アプリケーション110を管理する抽象的なプロセッサを動作させる。例えば、プロセッサに関する知識を持たないVM130は、Microsoft共通言語ランタイムまたはJava(登録商標)仮想マシンでもよい。マネージドAPIs120およびVM130は、MISLコードまたはJava(登録商標)バイトコードが特定のプロセッサをターゲットとしないために、すべての特定のプラットフォームに対して依存せずに動作する。それに従って、ジャスト・イン・タイム(JIT)コンパイラのようなコンパイラ140は、MISLコードまたはJava(登録商標)バイトコードを、マネージドAPIs120からプロセッサ160によって実行されうるネイティブ・アセンブリ・コードに変換(すなわち、再コンパイル)する。
【0015】
プロセッサ160は、Intel Pentium(登録商標)テクノロジ、Intel Itaniumテクノロジ、および/またはIntelパーソナル・インターネット・クライアント・アーキテクチャ(PCA)テクノロジのうちの1つ以上を使用して実装されてもよい。プロセッサ160は、暗号、マルチメディア、オーディオコーデック、ビデオコーデック、画像コーディング、画像処理、信号処理、文字列処理、音声圧縮、コンピュータビジョンなどのソフトウェア・ライブラリ関数をMRTEシステム100に提供する、SSE命令群、SSE2命令群、MMX命令群、および/またはその他の適用可能な命令群のような、プロセッサ特有の命令群150を実行することが可能であってもよい。
【0016】
しかし、上述のように、アンマネージド・ソフトウェア・ライブラリ関数(すなわち、プロセッサ特有の命令群150)は、プロセッサ160に対して最適化されうるが、マネージド・コード(すなわち、マネージドAPIs120)は、これまでマネージド・コード関数をカスタムハンドで最適化する方法が存在しないため、アンマネージド・ソフトウェアと同様の方法では、ある特定のプロセッサアーキテクチャに対して最適化されない。すなわち、マネージド・ランタイム・アプリケーション110に対応するマネージドAPIs120は、最適化に関して完全にJITコンパイラ140に依存しており、また、JITコンパイラ140は、プロセッサ特有の最適化を行うことができなかった。このように、従来のシステムでは、VM130が下層のプロセッサ160の一定のプロセッサ特有の命令群150をサポートしていなかったために、下層のプロセッサ160は、VM130によって提供されるサービスを使用することができず、また、マネージド・ランタイム・アプリケーション110は、下層のプロセッサ160によって提供される機能を使用することができなかった。
【0017】
図2の例は、マネージド・ランタイム・アプリケーション210、1つ以上のAPIs220、1つ以上の最適化マネージドAPIs225、VM230、PIPSジェネレータ235、コンパイラ240、プロセッサ特有の命令群250、およびプロセッサ260を含むプロセッサ命令プロキシ・スタブ(PIPS)システム200を有する、MRTEのアーキテクチャ階層を示す。本明細書において使用される「スタブ」は、プログラムの実行中に種々のタスクを実行するために提供される動的に生成されるコードの一部を指す。
【0018】
一般的に、PIPSジェネレータ235は、下層のプロセッサ260上におけるマネージド・ランタイム・アプリケーション210の実行を最適化するために、PIPS(例:図5のPIPS510)と呼ばれるコードの一部または命令のセットを生成する。マネージド・ランタイム・アプリケーション210がインストールされると、例えば、PIPSジェネレータ235は、プロセッサ特有の命令群250に基づいて、PIPSを生成する。更に、PIPSジェネレータ235は、マネージド・ランタイム・アプリケーション210によって使用される最適化マネージドAPIs225を作成するために、PIPSをあるマネージドAPIs220に挿入する。下記に詳細に説明するように、マネージド・ランタイム・アプリケーション210が実行されている間、最適化マネージドAPIs225は、アンマネージド・コード(すなわち、プロセッサ特有の命令群250)をマネージド・コード(すなわち、マネージド・ランタイム・アプリケーション210)に書き換えることなく、下層のプロセッサ260の性能を最適化する。最適化マネージドAPIs225は、メモリ(例:図8のメモリ1030)に保存され、MRTEにおけるマネージド・ランタイム・アプリケーション210の実行時にリコールされる。その結果、下層のプロセッサ260上におけるマネージド・ランタイム・アプリケーション210の性能を最適化するために、下層のプロセッサ260の機能が使用可能にされうる。
【0019】
図2のPIPSジェネレータ235はPIPSシステム200内の独立したブロックとして図示されるが、PIPSジェネレータ235によって実行される機能は、VM230および/またはJITコンパイラ240内に組み込まれてもよい。
【0020】
図3を参照すると、PIPSシステム300の例は、MRTEにおいてマネージド・ランタイム・アプリケーション310を実行するために、マネージド・ランタイム・アプリケーション310、1つ以上の最適化マネージドAPIs325、VM330、JITコンパイラ340、ネイティブ・アセンブリ・コード350、およびプロセッサ360を有する。VM330は、マネージド・ランタイム・アプリケーション310を実行するために、複数の異なるプロセッサに対して互換性があるプロセッサ命令群を実行してもよい。しかし、一般的に、VM330は、最適化マネージドAPIs325なしでは使用することができない機能を使用可能にするために下層のプロセッサ360の特定のプロセッサ特有の命令群を実行することはしない。これに対して、PIPSシステム300によってマネージド・ランタイム・アプリケーション310が実行されている間、例えば、JITコンパイラ340は、ネイティブ・アセンブリ・コード350(例:図5のネイティブ・アセンブリ・コード500)を生成するために、最適化マネージドAPIs325をコンパイルする。特に、マネージド・ランタイム・アプリケーション310のインストール時に、最適化マネージドAPIs325を生成するためにPIPSジェネレータ235がPIPSを挿入したため、JITコンパイラ340は、ネイティブ・アセンブリ・コード350を更に最適化することなく、ネイティブ・アセンブリ・コード350を単純にコンパイルして実行する。換言すると、PIPSは、下層のプロセッサ360上においてマネージド・ランタイム・アプリケーション310を実行するために、マネージド・ランタイム・アプリケーション310のマネージドAPIsを予め最適化(すなわち、最適化マネージドAPIs325)した。これにより、JITコンパイラ340がアンマネージド・コード(例:図2のプロセッサ特有の命令群250)をマネージド・コード(すなわち、マネージド・ランタイム・アプリケーション310)に書き換えることなく、最適化マネージドAPIs325は、下層のプロセッサ360の性能を最適化する。その結果、ネイティブ・アセンブリ・コード350は、下層のプロセッサ360におけるマネージド・ランタイム・アプリケーション310の性能を最適化するように、カスタマイズされる。
【0021】
図4の例では、文字列比較関数400は、アンマネージドの高級言語のコードによって実装される。概して、文字列比較関数400は、上述のIntelプロセッシング・テクノロジのうちの1つ以上を使用して実装されたプロセッサにおけるSSE2命令群のようなプロセッサ特有の命令群を使用したカスタムハンドな最適化コーディングによって、C言語ルーチンとして最適化される。しかし、C#またはJava(登録商標)の比較関数コードのようなマネージド・コードを特定のプロセッシング・アーキテクチャに対してカスタムハンドに最適化する方法は存在しない。
【0022】
図2および図3と関連して説明されたように、下層のプロセッサ360上における文字列比較関数400の性能を最適化するPIPS510を含む、ネイティブ・アセンブリ・コード500の一部の例が、図5に示される。特に、ネイティブ・アセンブリ・コード500は、PIPSジェネレータ235によって生成されたPIPS510を有する。例えば、PIPSジェネレータ235は、文字列比較関数400のインストール時にPIPS510を生成するために、Microsoft .NETによって提供されるネイティブ・マーシャリング言語(ML)コードを使用してもよい。PIPS510に基づいて、PIPSジェネレータ235は、マネージド・ランタイム・アプリケーション310に相当する最適化マネージドAPIs325を生成する。JITコンパイラ340は、図5に示すように、実行する下層のプロセッサ360に対するPIPS510を含む、文字列比較関数に対応するネイティブ・アセンブリ・コード500をコンパイルする。文字列比較関数400がランタイム時に開始されたとき、VM330は、ネイティブ・アセンブリ・コード500を生成するために、JITコンパイラ340に対して、最適化マネージドAPIs325を取り込む。PIPSジェネレータ235が予めPIPS510を最適化マネージドAPIs325に挿入したため、JITコンパイラ340は、最適化マネージドAPIs325を更に最適化することなく、最適化マネージドAPIs325をコンパイルして実行する。その結果、下層のプロセッサ360のプロセッサ特有の命令群250(すなわち、アンマネージド・コード)がPIPS510によってVMレイヤにまで抽象化されたため、マネージド・ランタイム・アプリケーション310は、VM330によって提供されるサービス(例:ガーベッジコレクション、メモリ管理、および/またはコードとロールベースのセキュリティ)、および、下層のプロセッサ360の機能の両方の利益を得ることができる。換言すると、最適化マネージドAPIs325は、マネージド・ランタイム・アプリケーション310を動作させるために、下層のプロセッサ360の機能を使用可能にするプロセッサ特有の命令群を使用可能にすることができる。
【0023】
フロー図600および700は、図6および図7にそれぞれ図示されるマネージドAPIを最適化するためにプロセッサによって実行されうる、マシンアクセス可能な命令群を示す。通常の技術を有する当業者は、この命令群が揮発性または非揮発性のメモリまたはその他の大容量ストレージデバイス(例:フロッピー(登録商標)ディスク、CD、およびDVD)のようなコンピュータによってアクセス可能な全ての媒体に保存された全てのプログラミングコードの使用による多くの異なる方法によって実装されうることを、理解するであろう。例えば、マシンアクセス可能な命令群は、消去可能プログラマブル・リード・オンリー・メモリ(EPROM)、リード・オンリー・メモリ(ROM)、ランダム・アクセス・メモリ(RAM)、磁気メディア、光メディア、および/またはその他の適用可能なタイプの媒体のような、マシンアクセス可能な媒体に組み込まれてもよい。あるいは、マシンアクセス可能な命令は、プログラマブル・ゲート・アレイおよび/または特定用途向け集積回路(ASIC)に組み込まれてもよい。更に、図6および図7には動作の特定の順番が図示されているが、通常の技術を有する当業者は、これらの動作が他の順番において実行されうることを理解するであろう。また、フロー図600および700は、図2および図5に関連して、マネージドAPIsを最適化する方法の一例として提供および説明されるのみである。
【0024】
図6の例では、フロー図600は、PIPSジェネレータ235が下層のプロセッサ260のプロセッサ特有の命令群250に関連するPIPS510を生成する、ブロック610から開始する。例えば、PIPSジェネレータ235は、マネージド・ランタイム・アプリケーション210のインストール中に、下層のプロセッサ260に相当するプロセッサ識別子に基づいて、PIPS510を生成してもよい。上述の通り、プロセッサ特有の命令群250は、下層のプロセッサ260上におけるマネージド・ランタイム・アプリケーション210の性能を最適化するために、プロセッサ特有の命令を使用することなくして使用できない、オーディオ処理、ビデオ処理、画像処理、音声認識、暗号などのような、下層のプロセッサ260の機能を使用可能にする。ブロック620において、PIPSジェネレータ235は、PIPS510に基づいて、最適化マネージドAPIs225を生成する。特に、PIPSジェネレータ235は、PIPS510をマネージド・ランタイム・アプリケーション210に相当するあるマネージドAPIs220に挿入する。PIPSジェネレータ235は、下層のプロセッサ260においてマネージド・ランタイム・アプリケーション210が実行されている間、最適化マネージドAPIs225がJITコンパイラ240から使用可能となるように、最適化マネージドAPIs225を保存する。
【0025】
図7の例では、フロー図700は、JITコンパイラ240がマネージド・ランタイム・アプリケーション210に相当する最適化マネージドAPIs225をコンパイルして実行する、ブロック710から開始する。上述のように、PIPSジェネレータ235がプロセッサ特有の命令群250に関連するPIPS510を最適化マネージドAPIs225に予め挿入したため、JITコンパイラ240は、最適化マネージドAPIs225を更に最適化することなく、最適化マネージドAPIs225をコンパイルしうる。すなわち、PIPS510は、最適化マネージドAPIs225によって、下層のプロセッサ260上で実行するためにマネージド・ランタイム・アプリケーション210をカスタムハンドで最適化する。ブロック640において、JITコンパイラ240は、プロセッサ特有の命令群250に相当する下層のプロセッサ260の機能を使用可能にする。VM230によって提供されるガーベッジコレクション、メモリ管理、およびコードとロールベースのセキュリティのようなサービスに加えて、マネージド・ランタイム・アプリケーション210は、下層のプロセッサ260上で実行される間、暗号、マルチメディア、オーディオコーデック、ビデオコーデック、画像コーディング、画像処理、信号処理、音声圧縮、コンピュータビジョンなどの最適化マネージドAPIs225によってマネージド・ランタイム・アプリケーション210に提供される、ソフトウェア・ライブラリ関数を使用しうる。その結果、最適化マネージドAPIs225は、マネージド・ランタイム・アプリケーション210が、プロセッサ特有の命令を使用することなくして使用できない、または、他のプロセッサにおいては非効率的である下層のプロセッサ260の機能を使用可能にする、プロセッサ特有の命令群250を実行することを可能にする。更に、最適化マネージドAPIs225は、ネイティブ・アセンブリ・コード500によって、下層のプロセッサ260におけるマネージド・ランタイム・アプリケーション210の性能をカスタムハンドに最適化する。
【0026】
本明細書において開示される方法および装置は、欧州コンピュータ・マネージメント・アソシエーション(ECMA)共通言語インフラストラクチャ(CLI)(second edition, December 2002)およびECMA C#言語仕様(second edition, December 2002)の実装のソースコードに適する。しかし、通常の技術を有する当業者は、開示内容が他のランタイム環境におけるソースコードに対しても適用可能であることを理解するであろう。
【0027】
図8は、本明細書において開示される方法および装置の実装に適合するプロセッサシステム1000の一例を示すブロック図である。プロセッサシステム1000は、デスクトップコンピュータ、ラップトップコンピュータ、ノートブックコンピュータ、パーソナルデジタルアシスタント(PDA)、サーバ、インターネットアプライアンス、またはその他いかなるタイプのコンピュータデバイスでもよい。
【0028】
図8に示されるプロセッサシステム1000は、メモリコントローラ1012および入力/出力(I/O)コントローラ1014を含む、チップセット1010を有する。よく知られているように、チップセットは、一般的に、プロセッサ1020からアクセス可能である、または、プロセッサ1020によって使用されるメモリおよびI/O管理機能を提供し、一般的な目的および/または特定の目的のレジスタ、タイマーなども提供する。プロセッサ1020は、1つ以上のプロセッサを使用して実装される。例えば、プロセッサ1020は、Intel Pentium(登録商標)テクノロジ、Intel Itaniumテクノロジ、Intel Centrino(登録商標)テクノロジおよび/またはIntel XScale(登録商標)テクノロジのうちの1つ以上を使用して実装されてもよい。あるいは、他のプロセッシング技術がプロセッサ1020を実装するために使用されてもよい。プロセッサ1020は、第1レベル・ユニファイド・キャッシュ(L1)、第2レベル・ユニファイド・キャッシュ(L2)、第3レベル・ユニファイド・キャッシュ(L3)、および/または通常の技術を有する当業者が認識するその他の適用しうる全ての構造を使用して実装されうる、キャッシュ1022を有する。
【0029】
従来技術のように、メモリコントローラ1012は、プロセッサ1020がバス1040によって揮発性メモリ1032および非揮発性メモリ1034を含むメインメモリ1030にアクセスして通信できるようにする機能を実行する。揮発性メモリ1032は、同期型ダイナミック・ランダム・アクセス・メモリ(SDRAM)、ダイナミック・ランダム・アクセス・メモリ(DRAM)、RAMBUSダイナミック・ランダム・アクセス・メモリ(RDRAM)、および/またはその他全てのタイプのランダム・アクセス・メモリ・デバイスによって実装されてもよい。非揮発性メモリ1034は、フラッシュメモリ、リード・オンリー・メモリ(ROM)、電気的消去可能リード・オンリー・メモリ(EEPROM(登録商標))、および/またはその他全てのタイプのメモリデバイスを使用して実装されてもよい。
【0030】
プロセッサシステム1000は、バス1040に接続されたインタフェース回路1050も有する。インタフェース回路1050は、イーサネット(登録商標)・インタフェース、ユニバーサル・シリアル・バス(USB)、第3世代入力/出力インタフェース(3GIO)インタフェース、および/またはその他適用可能な全てのタイプのインタフェースのような、いかなる従来のインタフェースの標準を使用して実装されてもよい。
【0031】
1つ以上の入力デバイス1060は、インタフェース回路1050に接続される。1つまたは複数の入力デバイス1060は、ユーザによるプロセッサ1020に対するデータおよびコマンドの入力を可能にする。例えば、1つまたは複数の入力デバイス1060は、キーボード、マウス、タッチセンシティブディスプレイ、トラックパッド、トラックボール、isopoint、および/または音声認識システムによって実装されてもよい。
【0032】
1つ以上の出力デバイス1070もまた、インタフェース回路1050に接続される。例えば、1つまたは複数の出力デバイス1070は、ディスプレイデバイス(例:発光ディスプレイ(LED)、液晶ディスプレイ(LCD)、陰極線管(CRT)ディスプレイ、プリンタ、および/またはスピーカ)によって実装されてもよい。このように、インタフェース回路1050は、一般的には、他のデバイスの中でも特に、グラフィックスドライバカードを有する。
【0033】
プロセッサシステム1000は、ソフトウェアおよびデータを保存する1つ以上の大容量ストレージデバイス1080も有する。そのような1つまたは複数の大容量ストレージデバイス1080の例は、フロッピー(登録商標)ディスクとドライブ、ハードディスクドライブ、コンパクトディスクとドライブ、およびデジタル多用途ディスク(DVD)とドライブを含む。
【0034】
インタフェース回路1050は、ネットワークによる外部コンピュータとのデータの交換を促進するモデムまたはネットワークインタフェースカードのような通信デバイスも含む。プロセッサシステム1000とネットワーク間の通信リンクは、イーサネット(登録商標)接続、デジタル加入者回線(DSL)、電話線、携帯電話システム、同軸ケーブルなどのような、いかなるタイプのネットワーク接続でもよい。
【0035】
1つまたは複数の入力デバイス1060、1つまたは複数の出力デバイス1070、1つまたは複数の大容量ストレージデバイス1080、および/またはネットワークへのアクセスは、概して、従来技術の手法に沿ってI/Oコントローラ1014によってコントロールされる。特に、I/Oコントローラ1014は、プロセッサ1020がバス1040およびインタフェース回路1050によって1つまたは複数の入力デバイス1060、1つまたは複数の出力デバイス1070、1つまたは複数の大容量ストレージデバイス1080、および/またはネットワークにアクセスできるようにする機能を実行する。
【0036】
図8に示されるコンポーネントはプロセッサシステム1000内の独立したブロックとして図示されるが、これらのブロックのうちのいくつかによって実行される機能は、1つの半導体回路内に組み込まれてもよく、または、2つ以上の独立した集積回路を使用して実装されてもよい。例えば、メモリコントローラ1012およびI/Oコントローラ1014は、チップセット1010内の独立したブロックとして図示されるが、通常の技術を有する当業者は、メモリコントローラ1012およびI/Oコントローラ1014は1つの半導体回路に組み込まれうることを理解するであろう。
【0037】
本明細書ではある一定の方法、装置、および製品の例が説明されるが、本発明の特許請求の範囲は、これらに限定されない。本発明の範囲は、逐語的にまたは均等論によって添付の特許請求の範囲に収まる全ての方法、装置、製品に及ぶ。例えば、本明細書は、他のコンポーネントの中でもハードウェア上で実行されるソフトウェアまたはファームウェアを含むシステム例を開示するが、これらのシステムは、単に本発明を説明するためのものであって本発明を限定するものではない。特に、全ての開示されたハードウェア、ソフトウェア、および/またはファームウェアコンポーネントは、ハードウェア内に独占的に組み込まれてもよく、ソフトウェアに独占的に組み込まれてもよく、ファームウェアに独占的に組み込まれてもよく、または、ハードウェア、ソフトウェア、および/またはファームウェアの組み合わせに組み込まれてもよいことが意図されている。
【特許請求の範囲】
【請求項1】
1つ以上のプロセッサ命令に関連するプロセッサ命令プロキシ・スタブを生成するステップと、
前記1つ以上のプロセッサ命令に関連する1つ以上のプロセッサの機能を使用可能にするために、前記プロセッサ命令プロキシ・スタブに基づいて最適化マネージド・アプリケーション・プログラム・インタフェースを生成するステップと
を備える方法。
【請求項2】
前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、マネージド・ランタイム環境の仮想マシンに関連するレイヤにおいて前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項3】
前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、マネージド・ランタイム・アプリケーションのインストール時に前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項4】
前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、ストリーミングSIMD拡張(SSE)命令、SSE2命令、およびマルチメディア拡張命令のうちの1つに関連する前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項5】
前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、仮想マシンのマーシャリング言語コードによって前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項6】
前記プロセッサの前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、前記1つ以上のプロセッサ命令に関連する前記プロセッサの識別に応じて、前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項7】
前記最適化マネージド・アプリケーション・プログラム・インタフェースに基づいて、マネージド・ランタイム・アプリケーションの実行中に、前記1つ以上のプロセッサ命令に関連する機能を使用可能にするステップを更に備える請求項1に記載の方法。
【請求項8】
命令群を記録したマシンアクセス可能な媒体であって、
前記命令群は、マシン上で実行されることにより、
1つ以上のプロセッサ命令に関連するプロセッサ命令プロキシ・スタブを生成し、
前記1つ以上のプロセッサ命令に関連する1つ以上のプロセッサの機能を使用可能にするために前記プロセッサ命令プロキシ・スタブに基づいて、最適化マネージド・アプリケーション・プログラム・インタフェースを生成する
媒体。
【請求項9】
前記命令は、前記マシンに、マネージド・ランタイム環境の仮想マシンに関連するレイヤにおいて前記プロセッサ命令プロキシ・スタブを生成させることによって、前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる請求項8に記載の媒体。
【請求項10】
前記マシンに前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる前記命令は、前記マシンに、マネージド・ランタイム・アプリケーションのインストール中に前記プロセッサ命令プロキシ・スタブを生成させることを備える請求項8に記載の媒体。
【請求項11】
前記マシンに前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる前記命令は、前記マシンに、ストリーミングSIMD拡張(SSE)命令、SSE2命令、およびマルチメディア拡張命令のうちの1つに関連する前記プロセッサ命令プロキシ・スタブを生成させることを備える請求項8に記載の媒体。
【請求項12】
前記命令は、前記マシンに、仮想マシンのマーシャリング言語コードによって前記プロセッサ命令プロキシ・スタブを生成させることによって、1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる請求項8に記載の媒体。
【請求項13】
前記命令は、前記マシンに、前記1つ以上のプロセッサ命令に関連する前記プロセッサを識別したこと応じて、前記プロセッサ命令プロキシ・スタブを生成させることによって、前記プロセッサの前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる請求項8に記載の媒体。
【請求項14】
前記命令は、前記マシンに、前記最適化マネージド・アプリケーション・プログラム・インタフェースに基づいてマネージド・ランタイム・アプリケーションを実行させるために、前記1つ以上のプロセッサ命令に関連する機能を使用可能にさせる請求項8に記載の媒体。
【請求項15】
前記マシンアクセス可能な媒体は、プログラマブル・ゲート・アレイ、特定用途向け集積回路、消去可能プログラマブル・リード・オンリー・メモリ、リード・オンリー・メモリ、ランダム・アクセス・メモリ、磁気メディア、および光メディアのうちの1つからなる請求項8に記載の媒体。
【請求項16】
1つ以上のプロセッサ命令に関連するプロセッサ命令プロキシ・スタブを生成し、前記プロセッサ命令プロキシ・スタブに基づいて最適化マネージド・アプリケーション・プログラム・インタフェースを生成するプロセッサ命令プロキシ・スタブ・ジェネレータと、
前記1つ以上のプロセッサ命令に関連するプロセッサの1つ以上の機能を使用可能にするために前記最適化マネージド・アプリケーション・プログラム・インタフェースをコンパイルするコンパイラと
を備える装置。
【請求項17】
前記プロセッサ命令プロキシ・スタブ・ジェネレータは、仮想マシンおよびコンパイラのうちの1つに組み込まれている請求項16に記載の装置。
【請求項18】
前記プロセッサ命令プロキシ・スタブ・ジェネレータは、前記プロセッサ命令プロキシ・スタブを生成するために、前記1つ以上のプロセッサ命令に関連するプロセッサを識別する請求項16に記載の装置。
【請求項19】
1つ以上のプロセッサ命令は、ストリーミングSIMD拡張(SSE)命令、SSE2命令、およびマルチメディア拡張命令のうちの1つを有する請求項16に記載の装置。
【請求項20】
前記コンパイラは、ジャスト・イン・タイム・コンパイラを有する請求項16に記載の装置。
【請求項21】
前記プロセッサ命令プロキシ・スタブは、マネージド・ランタイム環境の仮想マシンに関連するレイヤにおいて生成される請求項16に記載の装置。
【請求項22】
前記最適化マネージド・アプリケーション・プログラム・インタフェースは、マネージド・ランタイム・アプリケーションの実行に対して前記1つ以上のプロセッサ命令に関連する機能を使用可能にする請求項16に記載の装置。
【請求項23】
1つ以上の最適化マネージド・アプリケーション・プログラム・インタフェースを保存するダイナミック・ランダム・メモリ(DRAM)と、
1つ以上のプロセッサ命令に関連するプロセッサ命令プロキシ・スタブを生成し、前記1つ以上のプロセッサ命令に関連する前記プロセッサの1つ以上の機能を使用可能にするために前記プロセッサ命令プロキシ・スタブに基づいて最適化アプリケーション・プログラム・インタフェースを生成する、前記DRAMに接続されたプロセッサと
を備えるプロセッサシステム。
【請求項24】
1つ以上のプロセッサ命令は、ストリーミングSIMD拡張(SSE)命令、SSE2命令、およびマルチメディア拡張命令のうちの1つを有する請求項23に記載のプロセッサシステム。
【請求項25】
前記プロセッサ命令プロキシ・スタブは、マネージド・ランタイム環境の仮想マシンに関連するレイヤにおいて生成される請求項23に記載のプロセッサシステム。
【請求項26】
前記プロセッサ命令プロキシ・スタブは、マネージド・ランタイム・アプリケーションのインストール時に生成される請求項23に記載のプロセッサシステム。
【請求項27】
前記最適化マネージド・アプリケーション・プログラム・インタフェースは、マネージド・ランタイム・アプリケーションの実行時に前記1つ以上のプロセッサ命令に関連する機能を使用可能にする請求項23に記載のシステム。
【請求項1】
1つ以上のプロセッサ命令に関連するプロセッサ命令プロキシ・スタブを生成するステップと、
前記1つ以上のプロセッサ命令に関連する1つ以上のプロセッサの機能を使用可能にするために、前記プロセッサ命令プロキシ・スタブに基づいて最適化マネージド・アプリケーション・プログラム・インタフェースを生成するステップと
を備える方法。
【請求項2】
前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、マネージド・ランタイム環境の仮想マシンに関連するレイヤにおいて前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項3】
前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、マネージド・ランタイム・アプリケーションのインストール時に前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項4】
前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、ストリーミングSIMD拡張(SSE)命令、SSE2命令、およびマルチメディア拡張命令のうちの1つに関連する前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項5】
前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、仮想マシンのマーシャリング言語コードによって前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項6】
前記プロセッサの前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成するステップは、前記1つ以上のプロセッサ命令に関連する前記プロセッサの識別に応じて、前記プロセッサ命令プロキシ・スタブを生成するステップを備える請求項1に記載の方法。
【請求項7】
前記最適化マネージド・アプリケーション・プログラム・インタフェースに基づいて、マネージド・ランタイム・アプリケーションの実行中に、前記1つ以上のプロセッサ命令に関連する機能を使用可能にするステップを更に備える請求項1に記載の方法。
【請求項8】
命令群を記録したマシンアクセス可能な媒体であって、
前記命令群は、マシン上で実行されることにより、
1つ以上のプロセッサ命令に関連するプロセッサ命令プロキシ・スタブを生成し、
前記1つ以上のプロセッサ命令に関連する1つ以上のプロセッサの機能を使用可能にするために前記プロセッサ命令プロキシ・スタブに基づいて、最適化マネージド・アプリケーション・プログラム・インタフェースを生成する
媒体。
【請求項9】
前記命令は、前記マシンに、マネージド・ランタイム環境の仮想マシンに関連するレイヤにおいて前記プロセッサ命令プロキシ・スタブを生成させることによって、前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる請求項8に記載の媒体。
【請求項10】
前記マシンに前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる前記命令は、前記マシンに、マネージド・ランタイム・アプリケーションのインストール中に前記プロセッサ命令プロキシ・スタブを生成させることを備える請求項8に記載の媒体。
【請求項11】
前記マシンに前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる前記命令は、前記マシンに、ストリーミングSIMD拡張(SSE)命令、SSE2命令、およびマルチメディア拡張命令のうちの1つに関連する前記プロセッサ命令プロキシ・スタブを生成させることを備える請求項8に記載の媒体。
【請求項12】
前記命令は、前記マシンに、仮想マシンのマーシャリング言語コードによって前記プロセッサ命令プロキシ・スタブを生成させることによって、1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる請求項8に記載の媒体。
【請求項13】
前記命令は、前記マシンに、前記1つ以上のプロセッサ命令に関連する前記プロセッサを識別したこと応じて、前記プロセッサ命令プロキシ・スタブを生成させることによって、前記プロセッサの前記1つ以上のプロセッサ命令に関連する前記プロセッサ命令プロキシ・スタブを生成させる請求項8に記載の媒体。
【請求項14】
前記命令は、前記マシンに、前記最適化マネージド・アプリケーション・プログラム・インタフェースに基づいてマネージド・ランタイム・アプリケーションを実行させるために、前記1つ以上のプロセッサ命令に関連する機能を使用可能にさせる請求項8に記載の媒体。
【請求項15】
前記マシンアクセス可能な媒体は、プログラマブル・ゲート・アレイ、特定用途向け集積回路、消去可能プログラマブル・リード・オンリー・メモリ、リード・オンリー・メモリ、ランダム・アクセス・メモリ、磁気メディア、および光メディアのうちの1つからなる請求項8に記載の媒体。
【請求項16】
1つ以上のプロセッサ命令に関連するプロセッサ命令プロキシ・スタブを生成し、前記プロセッサ命令プロキシ・スタブに基づいて最適化マネージド・アプリケーション・プログラム・インタフェースを生成するプロセッサ命令プロキシ・スタブ・ジェネレータと、
前記1つ以上のプロセッサ命令に関連するプロセッサの1つ以上の機能を使用可能にするために前記最適化マネージド・アプリケーション・プログラム・インタフェースをコンパイルするコンパイラと
を備える装置。
【請求項17】
前記プロセッサ命令プロキシ・スタブ・ジェネレータは、仮想マシンおよびコンパイラのうちの1つに組み込まれている請求項16に記載の装置。
【請求項18】
前記プロセッサ命令プロキシ・スタブ・ジェネレータは、前記プロセッサ命令プロキシ・スタブを生成するために、前記1つ以上のプロセッサ命令に関連するプロセッサを識別する請求項16に記載の装置。
【請求項19】
1つ以上のプロセッサ命令は、ストリーミングSIMD拡張(SSE)命令、SSE2命令、およびマルチメディア拡張命令のうちの1つを有する請求項16に記載の装置。
【請求項20】
前記コンパイラは、ジャスト・イン・タイム・コンパイラを有する請求項16に記載の装置。
【請求項21】
前記プロセッサ命令プロキシ・スタブは、マネージド・ランタイム環境の仮想マシンに関連するレイヤにおいて生成される請求項16に記載の装置。
【請求項22】
前記最適化マネージド・アプリケーション・プログラム・インタフェースは、マネージド・ランタイム・アプリケーションの実行に対して前記1つ以上のプロセッサ命令に関連する機能を使用可能にする請求項16に記載の装置。
【請求項23】
1つ以上の最適化マネージド・アプリケーション・プログラム・インタフェースを保存するダイナミック・ランダム・メモリ(DRAM)と、
1つ以上のプロセッサ命令に関連するプロセッサ命令プロキシ・スタブを生成し、前記1つ以上のプロセッサ命令に関連する前記プロセッサの1つ以上の機能を使用可能にするために前記プロセッサ命令プロキシ・スタブに基づいて最適化アプリケーション・プログラム・インタフェースを生成する、前記DRAMに接続されたプロセッサと
を備えるプロセッサシステム。
【請求項24】
1つ以上のプロセッサ命令は、ストリーミングSIMD拡張(SSE)命令、SSE2命令、およびマルチメディア拡張命令のうちの1つを有する請求項23に記載のプロセッサシステム。
【請求項25】
前記プロセッサ命令プロキシ・スタブは、マネージド・ランタイム環境の仮想マシンに関連するレイヤにおいて生成される請求項23に記載のプロセッサシステム。
【請求項26】
前記プロセッサ命令プロキシ・スタブは、マネージド・ランタイム・アプリケーションのインストール時に生成される請求項23に記載のプロセッサシステム。
【請求項27】
前記最適化マネージド・アプリケーション・プログラム・インタフェースは、マネージド・ランタイム・アプリケーションの実行時に前記1つ以上のプロセッサ命令に関連する機能を使用可能にする請求項23に記載のシステム。
【図1】


【図2】
【図3】
【図4】

【図5】
【図6】

【図7】
【図8】

【図2】
【図3】
【図4】
【図5】
【図6】
【図7】
【図8】
【公開番号】特開2012−69130(P2012−69130A)
【公開日】平成24年4月5日(2012.4.5)
【国際特許分類】
【外国語出願】
【出願番号】特願2011−228831(P2011−228831)
【出願日】平成23年10月18日(2011.10.18)
【分割の表示】特願2010−51081(P2010−51081)の分割
【原出願日】平成17年2月2日(2005.2.2)
【出願人】(591003943)インテル・コーポレーション (1,101)
【Fターム(参考)】
【公開日】平成24年4月5日(2012.4.5)
【国際特許分類】
【出願番号】特願2011−228831(P2011−228831)
【出願日】平成23年10月18日(2011.10.18)
【分割の表示】特願2010−51081(P2010−51081)の分割
【原出願日】平成17年2月2日(2005.2.2)
【出願人】(591003943)インテル・コーポレーション (1,101)
【Fターム(参考)】
[ Back to top ]