
Fターム[5B005KK12]の内容
階層構造のメモリシステム (9,317) | 適用環境 (907) | 要求元 (807) | CPU (641)
Fターム[5B005KK12]の下位に属するFターム
マルチCPU (447)
Fターム[5B005KK12]に分類される特許
141 - 160 / 194
キャッシュシステム

【課題】 読み出しアドレスのヒット判定が簡便なキャッシュシステムを提供する。
【解決手段】 データ記憶部15は記憶装置3からのデータを固有の識別番号により特定される複数の記憶領域において記憶する。管理情報記憶部11は、データ記憶部が記憶しているまたは記憶処理中のデータのアドレスと識別番号との対応関係、およびデータ記憶部による記憶が完了しているか否かを識別番号ごとに示す有効表示情報を記憶する。リフィル処理部14は、プロセッサ部2から供給された新たなアドレスのデータを記憶すべき記憶領域である指定記憶領域を決定し、新たなアドレスのデータの出力を要求する信号を記憶装置に供給する。検査部17は、指定記憶領域の識別番号を供給され、指定記憶領域の識別番号の有効表示情報が有効か否かを判定し、有効の場合に指定記憶領域内のデータの出力を要求する旨の信号をデータ記憶部に供給する。
(もっと読む)
キャッシュ装置及び演算装置

【課題】 同じデータに頻繁にアクセスされるような場合であっても、キャッシュメモリの高速性をできるだけ損なわずに、キャッシュへのヒット率を可変制御できる、より好適なキャッシュ装置および演算装置の提供。
【解決手段】キャッシュコントローラ4は、プロセッサ1と主メモリ2との間に接続される。
また、キャッシュコントローラ4は、主メモリ2より高速に読み書き可能なキャッシュメモリ3と接続される。キャッシュメモリ3には、主メモリ上2のアドレスを示すタグ部11とキャッシュブロック13の容量値を保持する容量部12とキャッシュブロック13からなるキャッシュライン14を複数備えており、プロセッサ1から主メモリ1へ読み出し要求の際、キャッシュコントローラ4は、キャッシュメモリ3に、前記要求される内容が有るか否かを調べる。キャッシュ容量決定部22は、キャッシュブロック15の容量値を決定し、容量部12へ提供する。
(もっと読む)
キャッシュメモリの運用方法
【課題】キャッシュミスを低減し、かつメモリシステムの高性能化を図る。
【解決手段】中央制御部40が参照する下位メモリ素子48に記憶された大量の情報から取り出される第1情報が格納される第1補助記憶素子42、及び第1情報が含まれる第2情報が格納される第2補助記憶素子44を用意する。参照される情報が、第1補助記憶素子42または第2補助記憶素子44に存在するか、あるいは、参照される情報を含んでいない別の第1情報が第1補助記憶素子42に存在するか否かによって、前記下位メモリ素子48から第1情報または第2情報を選択的に取り出し、第1補助記憶素子42と第2補助記憶素子44とに選択的に格納する。
(もっと読む)
一方向全二重インタフェースを有するメモリのポスト書き込みバッファのための方法、装置及びシステム
一部の実施例では、一方向全二重インタフェースを有するメモリのポストライトバッファのための方法、装置及びシステムが提供される。これについて、バッファエージェントが、データをポストライトバッファに送信し、データをアドレスに書き込むための独立した表示を前記メモリに送信するため導入される。他の実施例がまた開示及び請求される。  (もっと読む)
(もっと読む)
柔軟な構成を有するキャッシュ、それを使用するデータ処理システム、およびそのための方法
キャッシュ(120)は、バス(116)に結合することができ、アレイ(125)と、コントローラ(122)とを備える。アレイ(125)は、複数のセット(200,210,220)を有し、各セットは、複数のキャッシュ・ライン(202)を有し、各セット内の各キャッシュ・ラインは、タグおよび複数のデータ語を含む。コントローラ(122)は、アレイ(125)と結合していて、コンフィグレーション値(232,234)により、各セットの複数のキャッシュ・ライン(202)の第1の部分(205)を第1のバス動作タイプと関連付け、各セットの複数のキャッシュ・ライン(202)の第2の部分(206)を第2のバス動作タイプと関連付ける。コントローラ(122)は、また、バス動作中、バス(116)を通るデータを、バス動作のタイプが第1のバス動作タイプである場合には、第1の部分(205)に選択的に格納するか、またはバス動作のタイプが第2のバス動作タイプである場合には、第2の部分(206)に選択的に格納する。 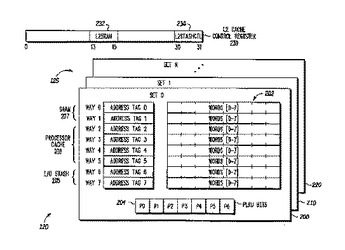 (もっと読む)
(もっと読む)
データプロセッサ、データ処理方法
【課題】データ処理の効率化を図る。
【解決手段】データプロセッサは、ソフトウェアを実行することによって、命令準備処理ステージと命令実行ステージを有する命令処理プロセッサをエミュレートするように構成されている。そのソフトウェアは、第一に、2以上の命令からなるグループに関して命令準備処理ステージをエミュレートすることにより、準備処理された命令のグループを生成し、次いで、準備処理された命令のグループに関して命令実行ステージをエミュレートすることにより、準備処理された命令のグループの各命令について命令実行ステージのエミュレーションが命令の順番に順次完了するように動作できる。
(もっと読む)
データ処理におけるメモリキャッシング
【課題】データ処理におけるメモリキャッシングを効率的に行うこと。
【解決手段】 データプロセッサは、主メモリと、命令キャッシュおよびデータキャッシュと、を備え、必要とされる命令を前記命令キャッシュから検索し、前記必要とされる命令が前記命令キャッシュに存在しない場合、前記データキャッシュから検索し、前記必要とされる命令がデータキャッシュに存在しない場合、前記必要とされる命令を前記主メモリから前記命令キャッシュにフェッチするように機能する命令フェッチロジックと、データ値を前記データキャッシュのデータアドレスの位置に書き込み、そして前記命令キャッシュにおいても前記アドレスが記述されている場合、そのデータ値を前記命令キャッシュに書き込むように機能するデータライトロジックと、前記データキャッシュから前記主メモリにデータを転送するように機能するキャッシュ制御ロジックと、を実行する。
(もっと読む)
マイクロプロセッサ及びマイクロプロセッサの制御方法
【課題】
ノンブロッキング・ロード機能を備えたマイクロプロセッサであっても、非整列ロード命令が発行された場合、若しくはキャッシュアクセスにおいてキャッシュミスがあると、パイプラインストールが発生する。
【解決手段】
ロード・ストア・ユニット22は、ロード先レジスタのロード前の値を格納するTopレジスタ103と、命令デコード部13より発行されたロード命令が、非整列ロード命令であるか否かを判定する非整列命令判定部104と、Topレジスタ103に保持されたデータを格納可能な退避レジスタ106とを備えており、非整列命令判定部104が非整列ロード命令と判定した場合に、Topレジスタ103の格納データを退避レジスタ106に格納し、Topレジスタ103を命令デコード部13が発行する後続命令に使用可能とする。
(もっと読む)
キャッシュライン境界を横切る命令におけるキャッシュミスの処理
プロセッサーのフェッチセクションは命令を取得するための命令キャッシュといくつかのステージのパイプラインを備える。命令は、キャッシュライン境界を横切ってもよい。パイプラインステージは2つのアドレスを処理し完全な境界を横切る命令を回復する。そのような処理の期間に、命令の第2の部分がキャッシュに存在しないなら、第1のラインに関するフェッチは無効とされ再循環される。この第1のパスに対して、そのデータのいずれかをプロセッサーの後段のステージに渡すことなく、命令の第2の部分のためのアドレスの処理は、より高いレベルのメモリからキャッシュに命令データをロードするためのプリフェッチ要求として取扱われる。第1のラインアドレスが再びフェッチステージを通過すると、第2のラインアドレスが通常の順番で続き、命令の両方の部分は、キャッシュからフェッチすることができ、通常の方法で結合することができる。  (もっと読む)
(もっと読む)
複数の状態のプロセッサのための命令のキャッシング
複数の動作状態をもつプロセッサのための命令をキャッシュに入れる方法および装置。プロセッサの動作状態の少なくとも2つは、異なる命令セットを支援する。プロセッサが状態の1つにおいて動作している一方で、命令のブロックがメモリから検索される。命令は、前記状態の1つにしたがってプリデコードされ、キャッシュにロードされ得る。プロセッサまたは別のエンティティは、キャッシュ内のプリデコードされた命令の1つがプロセッサによって要求されると、プロセッサの現在の状態が、命令をプリデコードするのに使用された前記状態の1つと同じであるかどうかを判断するのに使用され得る。 (もっと読む)
集積回路装置、マイクロコンピュータ及び電子機器
【課題】キャッシュメモリ内蔵のCPUを有する集積回路装置において、機能を低下させることなくキャッシュメモリの消費電流を減らすこと。
【解決手段】本集積回路装置10は、CPU20とキャッシュメモリ30とキャッシュインターフェース回路40と、CPUの要求データ幅よりも大きいバス幅を持つキャッシュデータバスとを含み、前記キャッシュインターフェース回路40は、要求アドレスに基づきCPUの要求データ幅よりも大きいキャッシュデータバスのバス幅分のデータを読み出し、読み出したデータをCPUの要求データ幅単位で取り出し可能に保持し、CPUの要求アドレスのデータが前記データ保持回路に保持されている場合には、データ保持回路に保持されているデータをCPUにむけ出力し、CPUの要求アドレスに応じたキャッシュメモリへのアクセスを行わないサイクルはキャッシュメモリのクロックをストップ又は低パワーにするための低パワー制御信号を生成して出力する。
(もっと読む)
情報処理装置、演算処理装置およびメモリアクセス制御方法
【課題】 CPUとMMUとをつなぐバスの混雑度を予測し、CPUの効率的な動作を図る。
【解決手段】 命令デコーダ13で命令をデコードして得られるオペコードをスカラリクエスト数計算部42に送信する。スカラリクエスト数計算部42は、発行されるメモリリクエスト数の期待値を計算し、登録時計算制御部46等を経由して演算器48に送信する。また、主記憶部21からデータの読み出しが終了した際には、終了時計算制御部47で実行が完了したメモリリクエスト数が計算され、演算器48に送信される。演算器48はリクエストカウンタ49の保持値と登録時計算制御部46と終了時計算制御部47とから送信された値とを加算し、結果をリクエストカウンタ49に格納する。リクエストカウンタ49の格納値に従って、動作制御部50内の各制御部51〜54からメモリアクセス中の動作を最適化するような各種制御信号を出力する。
(もっと読む)
キャッシュメモリ装置
【課題】キャッシュヒットを向上させるために、常駐させるべき命令コードやデータをキャッシュメモリ3に常駐させる。
【解決手段】システムを動作させるためのプログラムやデータの処理を行うCPU1と、プログラムの命令コードやデータを格納するための低速でかつ大容量の主記憶装置2と、主記憶装置2より小容量でかつ高速な、命令コードやデータを一時的に格納するためのキャッシュメモリ3と、キャッシュメモリ3の置き換えや読み出し動作を行うキャッシュメモリ制御回路4と、キャッシュメモリ3に常駐させた命令コードやデータの領域を置き換え動作時の置き換え対象から除外するための置き換え候補制御回路5とを備えて構成することで、常駐させるべき命令コードやデータが存在しているキャッシュメモリ3の領域を設ける。
(もっと読む)
演算処理回路、データ格納回路、演算処理装置、演算処理方法、データ格納方法、および、演算結果格納読み出し方法
【課題】 演算を実行した演算結果をキャッシュとは別の演算結果メモリに格納しておくことにより、演算結果の取得を高速にする。
【解決手段】 命令処理回路30からの読み出し要求により、キャッシュ10は、キャッシュヒット・ミスを判定し、ミスであると、キャッシュミス情報を命令処理回路30に出力する。命令処理回路30は、キャッシュミス情報により、外部メモリ50にフィル要求を出力し、外部メモリ50は、フィルデータを出力する。キャッシュ10は、フィルデータを格納する。演算回路40は、フィルデータに対する演算を実施し、演算結果を出力する。演算結果メモリ20は、演算結果をキャッシュ10のセットと対応するセットに格納する。命令処理回路30は、演算結果読み出し命令により、演算結果メモリ20から演算結果を読み出す。
(もっと読む)
仮想マシン環境内でのゲスト物理アドレスの仮想化の方法およびシステム
【課題】複数の仮想マシンが存在する環境内において、仮想マシン間でページを共有する方法を提供すること。
【解決手段】まず、第2の仮想マシンとのページ共有のために第1の仮想マシンの一時ゲスト物理アドレスレンジが割り振られる。一時レンジは、第1の仮想マシンのゲスト物理アドレス空間内にある。第2の仮想マシンから、第1の仮想マシンが利用可能なページに対するDMA要求などのアクセス要求が受信される。ページに対する保留アクセスの参照カウントがインクリメントされて保留アクセスが示され、ページは一時ゲスト物理アドレスレンジ内にマッピングされる。ページがアクセスされ、参照カウントはデクリメントされる。次いで、参照カウントがゼロである場合、一時ゲスト物理アドレスレンジ内のマッピングが削除される。
(もっと読む)
記憶装置および情報処理システム
【課題】非選択データの冗長な書き込み操作を不要とでき、ページの配列を書き換えに効率の良い状態に最適化することが可能な記憶装置を提供する。
【解決手段】記憶装置50において、外部との入出力インターフェース回路53には内部バスBS50を介してNAND型フラッシュメモリよりなる大容量のメインメモリ51と、強誘電体メモリよりなる比較的小容量の補助メモリ52が接続されており、さらに転送制御回路54を有し、メインメモリ51は内部が高並列化されており、32kBのデータ群が単位ページとして同時にアクセスされ、内部バスBS50に入出力転送される。装置内部にはページを管理単位としたアドレステーブル60が構築されている。インターフェース回路53は内部に32kBのページバッファーを備え、内部バスBS50から一旦ページ単位でデータを取得し、512Bのファイルセクター単位でデータを入出力する。
(もっと読む)
データ処理システム及びデータ伸長方法
【課題】 ライトアロケート方式のキャッシュメモリを採用するデータ処理システムにおいて、キャッシュミス時の無駄なメモリリードを防ぎ、データ処理を高速に行う。
【解決手段】 メインメモリ300からキャッシュメモリ100に圧縮データが格納され、該圧縮データに対応する伸長データの容量が算出される(ステップS002)。後のデータ書込みの際にキャッシュミスが生じないように、伸長データの格納先アドレスがキャッシュメモリ100に書き込まれ、算出したデータ量に対応するデータ領域が前記キャッシュメモリ内に確保される(ステップS003)。キャッシュメモリ100に格納された圧縮データは伸長され、該伸長データはキャッシュメモリ内に確保された領域に書き込まれる(Sステップ004)。キャッシュメモリ100に格納された伸長データは、キャッシュメモリコントローラ150によりメインメモリ300に移動される。
(もっと読む)
データ処理装置
【課題】 顧客プログラムの保護の強化を図る。
【解決手段】 命令コードを実行可能な中央処理装置(1600)と、暗号化された命令コードを保持可能な命令キャッシュ(100)と、上記中央処理装置と上記命令キャッシュとの間に配置され、上記暗号化された命令コードを、上記命令キャッシュを介して取り込み、それを復号化して上記中央処理装置に供給するための命令コード復号化論理(300)と、を含んでデータ処理装置を構成することにより、上記命令キャッシュの内容を暗号化された命令コードとし、復号化された命令コードが命令キャッシュに格納されるのを回避することで、顧客プログラムの保護の強化を達成する。
(もっと読む)
特定コード部分のキャッシュトラッシングの低減
キャッシュメモリ割り込みサービスルーチン(ISR)は、それらが割り込みする命令ストリーム(301)の必要な命令の置換を生じさせる。これは、ISR(302)の実行前に命令キャッシュ(102)に含まれる命令が、ISR命令によって上書きされるので、「命令キャッシュトラッシング」として知られている。命令キャッシュメモリのトラッシングを低減するために、命令キャッシュは、実行中、第1のメモリ部分(501a)及び第2のメモリ部分(501b)に動的に分割される。第1のメモリ部分(501a)は、現在命令ストリーム(301)の命令を記憶し、第2のメモリ部分(501b)は、ISR(302)の命令を記憶する。このように、ISR(302)は、第2のメモリ部分(501b)にのみ影響を及ぼし、第1のメモリ部分(501a)に記憶された命令データが損なわれないままにする。命令キャッシュ(102)のこの分割は、プロセッサのフェッチ処理を低減するとともに、命令キャッシュメモリ(102)のパワー消費を低減する。  (もっと読む)
(もっと読む)
電子機器、データ処理方法、及びコンピュータプログラム
【課題】 電子機器のスタートアップ時間を飛躍的に短縮させるようにする。
【解決手段】 ROM1003のデータセグメントの初期値が格納されたエリアから、データセグメントの対応するエリア(RAM1004)へデータコピーが行われたかどうかを記憶する複写済みエリア管理テーブル107を有し、RAM1004のデータセグメント内にあるROM103からのデータコピーが未だ行われていないエリアに対するアクセスを検出すると、実行中のプログラムを中断して、NMI割り込みハンドラの処理の中でデータコピーを行った後、複写済みエリア管理テーブル107の情報を更新して、前記プログラムの実行を再開することにより、データセグメントの初期値をROM1003からRAM1004へコピーする動作を、オンデマンドに分散して行う。
(もっと読む)
141 - 160 / 194
[ Back to top ]