
Fターム[5B042JJ20]の内容
デバッグ、監視 (27,428) | 動作監視、異常又は誤りの検出 (3,508) | 異常又は誤りの検出方法 (1,125) | 時間を監視するもの (556) | 特定処理に要する時間 (77)
Fターム[5B042JJ20]に分類される特許
1 - 20 / 77
ジョブ処理システム、ジョブ処理装置、負荷分散装置、ジョブ処理プログラムおよび負荷分散プログラム
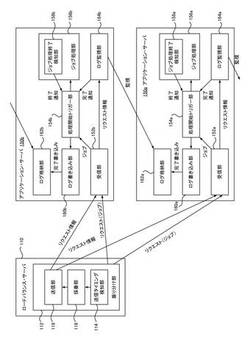
【課題】 要求されたジョブを複数のジョブ処理装置へ振り分けて処理すること。
【解決手段】 本ジョブ処理システム170は、複数のジョブ処理装置150と、負荷分散装置110とを含む。負荷分散装置110は、順序を規定する順序規定手段116と、ジョブ振り分け先のジョブ処理装置に対し、順序で先行する先行ジョブを特定するためのジョブ識別情報と、先行ジョブの振り分け先のジョブ処理装置を識別する装置識別情報とを送信する送信手段118とを含む。ジョブ処理装置150は、受信した装置識別情報で特定されるジョブ処理装置のログを監視し、先行ジョブの完了を検知する監視手段164と、先行ジョブの完了が検知され、かつ、振り分けられた担当ジョブの処理が終了したことに応答して、該担当ジョブを完了させて、振り分けられた次のジョブの処理を開始する処理開始手段154と、担当ジョブの完了をログに書き込む書き込み手段160とを含む。
(もっと読む)
周期エラー検出方法および周期エラー検出回路

【課題】周期処理の処理時間超過を確実に検出することのできる周期エラー検出方法および周期エラー検出回路を提供する。
【解決手段】実施形態の周期エラー検出方法は、カウンタ11と、レジスタ12とを有するキャプチャタイマ1を備え、周辺回路110から出力される周期トリガをキャプチャトリガCTG1として取得した第1のカウント値cnt1、モジュール120の処理開始時にキャプチャトリガCTG2をかけて取得した第2のカウント値cnt2、モジュール120の処理終了時にキャプチャトリガCTG3をかけて取得した第3のカウント値cnt3を、それぞれレジスタ12に保存する。プロセッサ100は、モジュール120からの完了通知を受け取ると、レジスタ12からcnt1、cnt2、cnt3を読み出し、その値にもとづいてモジュール120の処理時間を算出し、所定周期と比較して周期処理エラーの発生の有無を判定する。
(もっと読む)
情報処理装置、プロセス監視方法、プロセス監視プログラム、記録媒体
【課題】アプリケーションに起因してプロセスが異常終了する可能性を検出する。
【解決手段】収集部73は、複数の業務アプリケーション4に基づき処理を実行する複数の業務プロセス3のそれぞれについて、業務プロセス3の特性を表す特性情報を収集する。比較部74は、複数のプロセスの各々から収集した特性情報を比較する。判断部75は、複数の業務プロセス3のうちのある業務プロセス3に関する特性情報が、複数の業務プロセス3のうち、ある業務プロセス3を除いた業務プロセス3のいずれの特性情報とも特性が異なる場合に、ある業務プロセス3について異常が発生したと判断する。
(もっと読む)
情報処理装置、情報処理システム、情報処理装置の異常兆候検出方法、及び異常兆候検出プログラム
【課題】他の情報処理装置のCPUとの間で同期ずれが発生したCPUで、異常兆候を検出する。
【解決手段】情報処理装置10は、CPU11と、入出力関連装置13と、同期制御部14と、他の情報処理装置20との間で情報を送受信する通信部17とを備える。同期制御部14は、CPU11を初期化する初期化設定部140と、CPU11と入出力関連装置13間のトランザクションを監視するトランザクション監視部141と、トランザクションの監視情報と他の情報処理装置20から受信したトランザクションの監視情報とからCPU11の同期ずれを判定する同期判定部142と、トランザクションの監視情報に基づき、異常兆候関連情報を取得する異常兆候関連情報取得部143と、同期ずれ有りのとき、異常兆候関連情報に基づき、CPU11の異常兆候の有無を判定する異常判定部144とを備える。
(もっと読む)
保守管理装置、保守管理方法、および保守管理用プログラム
【課題】通信ネットワーク構成装置の保守管理のための処理に関し、同時に実行不可能な複数の処理が競合する場合にも適切に処理を実行することが可能な保守管理装置、保守管理方法、および保守管理用プログラムを提供する。
【解決手段】端末の保守に関する処理ごとの、自身の処理が実行中であるときの後発の競合対象の処理に対する優先度を示す先発優先度と、先発の競合対象の処理に対する自身の処理の優先度を示す後発優先度とを記憶する管理テーブル記憶部11と、実行対象の処理の後発優先度が現在実行中の競合対象の処理の先発優先度よりも高いときには競合対象の処理の実行を非優先として停止するとともに実行対象の処理を優先して実行を開始し、実行対象の処理の後発優先度が現在実行中の競合対象の処理の先発優先度よりも低いときには競合対象の処理の実行を優先して継続し実行対象の処理を非優先として実行を中止する処理実行制御部12を備える。
(もっと読む)
情報処理装置、印刷装置及び監視方法
【課題】 起動時に発生する障害を検知する際に、装置の状態を監視する監視制御部を備えていては、コストが高くなってしまう。
【解決手段】 上述の課題を解決するために、装置全体の制御を行うための制御部と、装置に関する情報をネットワークを介して送受信する通常モードとして動作する通信制御部とを備える情報処理装置であって、情報処理装置の起動に際して、前記通信制御部の動作モードが監視モードに移行して、監視モードに移行した前記通信制御部が、前記制御部による当該起動に際して行うべき複数の処理の中で最後に実行される処理が完了した旨の情報の、所定の記憶領域に対する書き込みの有無に基づき、起動に際しての異常の発生を監視し、異常が発生した際には、前記監視モードに移行した前記通信制御部が、ネットワークに対して異常の発生を出力することを特徴とする。
(もっと読む)
情報処理装置、その制御方法、および制御プログラム
【課題】情報処理装置において起動異常を確実に検知する。
【解決手段】CPU108および117にはそれぞれ異なるメモリデバイスが接続されている。CPUの各々には、自己が起動された際、起動段階のいずれの段階まで進んだかについて特定して、特定された起動段階を起動情報として、別のCPUに接続されたメモリデバイスに書き込む。CPUの各々は自己に接続されたメモリデバイスに書き込まれた起動情報を参照して、別のCPUの起動に異常が生じたか否かを検知する。
(もっと読む)
監視装置、状態監視システム及び装置設定方法
【課題】ネットワーク状態監視システムにおける監視装置の配置作業の工数を低減する。
【解決手段】監視装置5は、ネットワーク装置3からネットワーク2の状態情報を取得する状態情報取得部50と、監視装置5からアクセス可能なデータベース80から、状態情報を収集する収集装置6を識別する収集装置情報を取得する収集装置情報取得部60と、収集装置情報に基づいて複数の収集装置6の負荷情報を取得する負荷情報取得部62と、負荷情報に基づいて収集装置6を選択する収集装置選択部63と、選択された収集装置6へ監視装置5を識別する監視装置情報を通知する監視装置情報通知部64を備える。
(もっと読む)
電子制御装置
【課題】ソフトウェアの処理負荷が所定負荷を超えた場合に、処理負荷の異常原因を解析できる電子制御装置を提供する。
【解決手段】タスクの起床元では、起床対象のタスクを起床すると(S420)、起床対象のタスクからリターンされる起床結果に基づいて起床が成功したか否かを判定し(S422)、起床に失敗すると(S422:No)、連続失敗回数カウンタを+1する(S424)。起床されたタスクは、起床元のタスクでカウントした連続失敗回数カウンタの値を今回値として記憶し(S430)、連続失敗回数カウンタをクリアし(S432)、今回の起床までにおける連続失敗回数の最大値を算出する(S434)。起床されたタスクは、連続失敗回数がソフトウェアの設計時に設定した許容範囲を超えている場合(S436:No)、ソフトウェアの処理負荷異常と判定し、判定結果と処理負荷異常時の車両走行情報とを記憶する(S438、S440)。
(もっと読む)
情報処理装置およびそのプログラム実行監視方法
【課題】 プログラム実行監視に伴うオーバーヘッドを減少させて、リアルタイムにプログラムの実行監視を行い得る情報処理装置およびそのプログラム実行監視方法を提供する。
【解決手段】 監視対象プログラム61の実行順i(i=1〜N)に対応付けて、監視対象プログラム61の任意の処理ステップにおける固有のアドレス情報を予め設定する設定情報保持部22に設定し、監視部21では、CPU10の命令ステップ毎に、CPU10が獲得したアドレス情報と現時点の実行順iに対応した固有のアドレス情報とを比較して両者が一致し、且つ現時点の実行順iがN未満であるときに、実行順iをインクリメントし、現時点の実行順iがN以上であるときに計時クリア要求を発行する。
(もっと読む)
処理時間予測装置、処理時間予測方法および処理時間予測プログラム
【課題】エラーが発生してもバッチ処理に要する処理時間の予測精度を向上させる。
【解決手段】複数のジョブを含むバッチ処理に要する処理時間を予測する処理時間予測装置1であって、ジョブごとのトランザクション数を算出するトランザクション数算出部11と、ジョブごとに一トランザクション分の処理を仮実行して仮処理時間を測定する仮処理時間測定部121と、ジョブごとに想定される予測処理時間を算出する予測処理時間算出部13と、各ジョブの実行時に要する実処理時間を測定する実処理時間測定部211と、各ジョブの実行時に発生するエラー回数をカウントするカウント部212と、予測処理時間の誤差率を算出する誤差率算出部222と、未処理ジョブの予測処理時間を再度算出する予測処理時間再算出部23と、を備える。
(もっと読む)
タイムアウト監視システム及びタイムアウト監視プログラム
【課題】複数のプロセスを連携して依頼処理を実行する場合に、タイムアウトを早期に検知するためのタイムアウト監視システム及びタイムアウト監視プログラムを提供する。
【解決手段】プロセス装置Aのタイマ監視部10は、取引要求を特定し、取引要求に応じてタイマ値を特定する。プロセス装置Aは、タイマ値を含めた電文を後続の各プロセス装置B〜Dに送信するとともに、タイマ監視部10は、イベント監視処理を実行する。タイマ監視部10は、正常完了又はタイムアウトを判定し、タイムアウトと判定した場合には、タイムアウト報告処理を実行する。また、プロセス装置B〜Dにおけるタイマ監視部20〜40は先行プロセスからタイマ値を取得する。そして、タイマ監視部20〜40は、タイマ値から減算値を差し引いた新たなタイマ値を算出し、このタイマ値を含めた電文送信処理を実行する。
(もっと読む)
タスク管理装置、タスク管理方法、及びプログラム
【課題】自然エネルギーに由来する電力を利用して演算を実行する演算装置が演算実行時に有する演算能力を考慮して適当な演算タスクを割り当てること。
【解決手段】自然エネルギーに由来する電力を利用して演算を実行する演算装置から、当該演算装置が設置された地域の気象情報に基づいて予測される当該演算装置の演算能力を示す能力情報を取得する能力情報取得部と、前記能力情報取得部により複数の前記演算装置から取得された能力情報に基づいて当該複数の演算装置に演算タスクを割り当てるタスク管理部と、を備える、タスク管理装置が提供される。
(もっと読む)
画像処理装置、画像処理装置の制御方法
【課題】主電源スイッチがオフにされた場合に、全てのログ情報を記憶させた後に、主電源をオフにする。
【解決手段】主電源スイッチと、主電源スイッチがオフにされたことを検知する検知手段と、ログ情報が記憶される記憶手段と、記憶手段にログ情報を記憶する第1処理、および、主電源をオフにするために必要な第2処理を行なう管理手段と、主電源をオフにするめに必要な第3処理を行い、ログ情報を生成し、該生成されたログ情報について管理手段に第1処理を行わせるための第1要求信号を管理手段に送信する生成手段と、検知手段が主電源スイッチがオフにされたことを検知すると、管理手段に第2処理を行わせ、生成手段に第3処理を行わせる要求手段と、を有し、生成手段は、管理手段は、ログ記憶要求終了信号を受信する時までに、要求されている全てのログ情報を記憶手段に記憶させ、主電源をオフにする。
(もっと読む)
障害監視装置、障害監視システム、障害監視方法およびプログラム
【課題】ユーザへの不要な障害発生の通知を軽減する。
【解決手段】複数の処理装置を含む処理システムの障害を監視する障害監視装置であって、いずれかの処理装置に障害が発生していることを示す情報を含む障害発生情報を受信する障害検知部1と、障害通知情報を出力する出力部2と、複数の処理装置の中のいずれかが自動復旧作業を開始したことを示す情報を含む自動復旧情報を受信する自動復旧検知部3と、障害検知部1が障害発生情報を受信すると、複数の処理各々に、当該処理を行う処理装置を対応付けて記憶する対応付け記憶手段を参照し、障害発生情報で特定される処理装置が行う処理を特定するとともに、当該処理と、自動復旧情報で特定される処理装置が行う処理との関係に基づき、障害通知情報の出力を制限するか否かを決定し、出力部2を制御する出力制御部4とを有する障害監視装置。
(もっと読む)
電子制御装置
【課題】内蔵された第一マイコン及び第二マイコンの起動時における動作モードを一致させることが可能な電子制御装置の提供。
【解決手段】第二マイコンは、起動されると、第一マイコンの動作を許可する許可信号を出力する(S130)。一方、始動された第一マイコンは、第二マイコンからの許可信号が入力されるまで待機した後(S210)、状態管理領域に格納されている正否情報の内容を確認する(S240)。その確認した正否情報の内容に応じた動作モードを、第一マイコン自身の動作モードとして特定して、その特定した動作モードの種類を表すモード通知を第二マイコンに出力する(S250)と共に、特定した動作モードで第一マイコン自身を動作させる(S260,S290)。第二マイコンは、第一マイコンから受信したモード通知の種類に応じた動作モードを特定して第二マイコン自身を動作させる(S160,S180)。
(もっと読む)
プログラム、アプリケーションサーバ装置の制御方法、アプリケーションサーバ装置
【課題】データベースサーバへの問合せが実行されない場合にデータベースサーバを再起動するアプリケーションサーバのプログラムを提供する。
【解決手段】アプリケーションサーバ1のプログラムは、データベースサーバ2へのSQLを発行する問合せステップと、問合せステップにおいて発行されたSQLをデータベースサーバ2に対して実行する実行ステップと、問合せステップにおいて発行されたSQLを監視対象として、SQLが予め定められた期間に実行ステップにおいて実行されない状態であるタイムアウトを監視し、予め定められた数のSQLがタイムアウトした場合に、データベースサーバ2を再起動する監視ステップとを、コンピュータに実行させる。
(もっと読む)
コンピュータ装置の異常検査方法及びそれを用いたコンピュータ装置
【課題】コンピュータ装置に顕在化することなく内在する障害を、起動時間のバラツキをより正確に監視することで検出し、ハードウェアの障害やその予兆を判断するためのコンピュータ装置の異常検査方法及びそれを用いたコンピュータ装置を提供する。
【解決手段】異常検査方法及びそれを用いたコンピュータ装置10は、計時手段を備え、電源投入直後の起動時刻を取得する起動時刻取得手段22と、OS起動処理完了後の終了時刻を取得する終了時刻取得手段27と、起動時刻から終了時刻までの時間を起動時間として求める起動時間算出手段28と、起動時間を蓄積して記憶する起動時間記憶手段29と、記憶された起動時間が所定時間を超えた場合に起動異常と判断する第1異常判断手段30と、記憶された各起動時間の偏差が所定範囲を超える場合に起動異常と判断する第2異常判断手段31とを備え、リトライ動作による起動時間の遅れを計測できる。
(もっと読む)
デジタル信号処理装置
【課題】 周期的に起動される信号処理に処理落ちが発生したか否かを判定することが可能なDSPを提供する。
【解決手段】 要求発生回路120Aは、読み出しフラグREAD0に応じてフレーム切り換えフラグFX01をリセットし、周期的に発生する処理要求REQ0に応じてフレーム切り換えフラグFX01をセットする処理落ち判定支援機能を有する。DSPコアは、処理要求REQ0に応じて、処理1を実行し、該処理1の開始の際に読み出しフラグREAD0を出力してフレーム切換フラグFX01をリセットさせ、該処理の終了の際にフレーム切換フラグFX01をリセットさせるとともに、リセット前におけるフレーム切換フラグFX01がセットされていたか否かを判定することにより、処理要求REQ0の1周期以内に処理1が終了しない処理落ちがあったか否かを判定する。
(もっと読む)
仮想計算機システム、仮想計算機システムの監視方法及びネットワーク装置
【課題】WANと、データセンタのLAN機器と、サーバのVMMと、VMM上の仮想マシンで発生する遅延増大を検知し、遅延増大の要因を迅速に特定する。
【解決手段】ネットワーク装置と仮想マシンを有するサーバ計算機に接続された性能低下要因特定装置が、ネットワーク装置から遅延通知を受信したときに、監視対象とする通信の監視条件とサーバ計算機と仮想マシンの対応関係を設定した通信フロー情報を参照して遅延が増大した仮想マシン及びサーバ計算機を特定し、仮想マシン間で共有するサーバ計算機の資源を特定する共有資源情報を参照して、遅延が増大した仮想マシンと計算機資源を共有する他の仮想マシンを抽出し、当該抽出された仮想マシン及びサーバ計算機と、遅延が増大した仮想マシン及びサーバ計算機について、物理的な計算機資源の性能情報と、仮想的な計算機資源の性能情報を取得して、遅延が増大した部位を特定する。
(もっと読む)
1 - 20 / 77
[ Back to top ]