
Fターム[5B056BB31]の内容
Fターム[5B056BB31]の下位に属するFターム
ベクトル命令 (47)
条件付き演算 (7)
要素間の論理的処理 (10)
スパースデータの処理 (9)
特殊又は特定の演算 (36)
複数の処理装置の結合 (13)
Fターム[5B056BB31]に分類される特許
1 - 20 / 31
情報処理装置、メモリアクセス制御装置及びそのアドレス生成方法
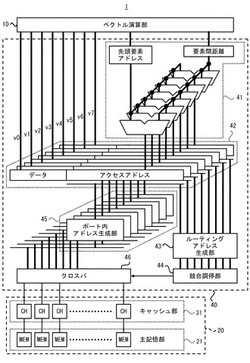
【課題】アクセス単位が複数ワード長の記憶部を利用しながらアクセス時間を短縮する。
【解決手段】情報処理装置1は、アクセス要求を出力する演算部10と、複数の接続ポートと、同時並行処理が可能な複数のメモリとを備え、接続ポートに対するアクセス単位が複数ワード長の記憶部20と、演算部10から処理サイクル毎に受信する前記アクセス要求に対応する複数のアクセスアドレスを複数の接続ポートに振り分けて、1アクセス単位に演算部10の異なる処理サイクルに属する不連続なワードを含むポート内アドレスを接続ポート毎に生成するメモリアクセス制御部40と、を有する。
(もっと読む)
行列計算処理方法、プログラム及びシステム

【課題】 FMM(Funny Matrix Multiplication)の計算を高速化すること。
【解決手段】 FMMで中心となるva[k] + vb[k]の最小値を計算する処理において、k=1,…nについて順番に処理するのではなく、best = ∞に初期設定してから、以下の処理Xと処理Yを一回ずつ適用した上で、bestの値をva[k]+vb[k]の最小値として出力することにある。
(処理X) k=a1,a2,…の順にva[k]+vb[k]の値を計算していき、それまでに見つかった最小値をbestとしたときに、va[k] > best/2となるkで処理をやめる(そのようなkが無ければk = anまで処理したらやめる)
(処理Y) 処理Xと同様の処理をk = b1,b2,…についても行い、vb[k] > best/2の値となるkで処理をやめる(そのようなkが無ければk = bnまで処理したらやめる)。
(もっと読む)
ベクトル演算処理装置、ベクトル演算処理方法およびベクトル演算処理プログラム
【課題】キャッシュメモリと主記憶装置との間の負荷を軽減し、ロードバッファの解放タイミングを早める。
【解決手段】投機的に実行されるベクトルロード命令が発行された場合に、ベクトルデータのバッファ領域M2を確保するロードバッファ管理部31と、メモリアクセスリクエストに基づいて要素データをキャッシュメモリM1又は主記憶装置9から読み出し、読み出した要素データをバッファ領域M2に格納させるキャッシュ処理部4と、投機的実行に成功した場合にバッファ領域の要素データをベクトルレジスタM3に転送してからバッファ領域M2を解放し、一方、投機的実行に失敗した場合にバッファ領域M2の要素データをベクトルレジスタM3に転送せずにバッファ領域M2を解放するベクトル処理部6とを備え、キャッシュ処理部4は投機的実行に失敗した場合に要素データの主記憶装置9からの読み出しを抑止する。
(もっと読む)
ベクトル浮動小数点引数削減
【課題】処理回路6、8と、受信した引数削減命令FREDUCE4、FDOT3Rに応答して、処理回路6、8を制御するための制御信号16を生成するデコーダ回路10とを備える、処理装置を提供する。
【解決手段】引数削減命令の作用は、入力ベクトルの各成分を、指数シフト値Cを入力ベクトル成分の指数に加算または減算するスケーリングの対象とすることである。指数シフト値Cは、この指数シフト値Cと、入力ベクトル成分のうちのいずれかの最大指数値Bとの合計が、第1の所定値と第2の所定値との間の範囲内にあるように選択される。この引数削減命令の実行の結果は、ドット積演算される場合、結果のベクトルが、浮動小数点のアンダーフローまたはオーバーフローに耐えるということである。
(もっと読む)
行列ベクターを分解する方法および非負値行列因数分解を特定の行列に適用する方法
【課題】分解を最大マージン分類器と結合することによりNMFの分解を式の形で活用し、共同の更新方程式を公式化し、分解とともに最大マージン分類器のパラメーターを特定する新規方法を提供する。
【解決手段】行列ベクターを分解する方法であって、非負値因数分解NMFと最大マージン分類器を組み合わせた費用関数を連続的反復で更新することにより最小化し、分解とともに最大マージン分類器のサポート・ベクターすべての指数を決定する。
(もっと読む)
プロセッサ、プロセッサのデータ処理方法、情報処理装置
【課題】 大容量のレジスタファイルから小さいレイテンシで大量のデータを効率よく計算することができるプロセッサを提供する。
【解決手段】 プロセッサは、演算手段と、演算手段にクロスバースイッチを介して接続する複数の少ポート大容量のRAMをインタリーブ化したレジスタファイルと、演算手段の演算結果を格納し、クロスバーを介して演算結果をレジスタファイルに書き戻すと共に、クロスバーをバイパスするパスを介して演算手段に格納データを出力するレジスタキャッシュとを含む。
(もっと読む)
コンテクスト抽出サーバ、コンテクスト抽出方法、およびプログラム
【課題】編集によりメディアデータに付与されたメタ情報に基づき、他のメディアデータと関連付けられたコンテクストを抽出するコンテクスト抽出サーバ、コンテクスト抽出方法、およびプログラムを提供することにある。
【解決手段】特徴量算出機能部207により、映像中の物体の大まかな位置を検出するアルゴリズムや、平均の色を算出するアルゴリズム等の基礎的な特徴量を抽出するアルゴリズムをメディアデータに適用し、得られる時系列的な特徴量ベクトルと、メタ情報整形機能部206により、メディアデータに時系列的に付与されたコメントを、その発生頻度や言語自体の特性から形成されるメタ情報との相関が、相関計算機能部305により演算される。
(もっと読む)
ベクトルプロセッサ制御装置
【課題】
複数の演算パイプラインを持つベクトルプロセッサにおいて、演算データが供給されない区間を減少させて、演算処理速度を向上させる。
【解決手段】
ベクトルレジスタと演算パイプラインの間にデータ要素を選択する機構を設け、データ要素が入るべき演算パイプラインを選択することで、演算データがないために演算の行われない演算パイプラインに次の命令の演算対象データを入れることにより、演算データが無い状態を削減する。
(もっと読む)
ベクトル積の並列処理方法
【課題】圧縮列格納法を用いたスパース行列とベクトルとの積を効率よく並列に処理する並列処理方法を提供する。
【解決手段】上記課題を解決するために、演算割り当て範囲における部分行列についての行列のベクトル積の演算処理を各スレッドに実行させ、演算結果が更新割り当て範囲か否かを判別し、当該演算結果が、更新割り当て範囲の場合には、行列と列ベクトルとの積を記憶する演算結果記憶手段に記憶し、更新割り当て範囲でない場合には、行列と列ベクトルとの積を一時的に記憶する演算結果退避手段に記憶させ、各スレッドに演算結果退避手段から他のスレッドが算出した更新割り当て範囲の演算結果を読み出させ、演算結果記憶手段に記憶されている演算結果を更新させる。
(もっと読む)
演算方法探索装置、有限体上演算装置、演算方法探索方法、有限体上演算方法、それらのプログラム及び記録媒体
【課題】P個の要素からなる第1有限集合内で閉じた特定の第1演算を、Q個の要素からなる第2有限集合内で閉じた第2演算の組合せで効率よく実現する。
【解決手段】第1演算の被演算子と演算結果とを第2演算の組合せで表現した真理値表T(δ)の被演算子に対応する行要素列からなるベクトルをそれぞれベクトル集合S(δ)の初期要素とする。そして、ベクトル集合S(δ)の要素間の第2演算結果を新たなベクトル集合S(δ)の要素に加える処理を複数回実行する。そして、ベクトル集合S(δ)の要素と、真理値表T(δ)の演算結果に対応する行要素列からなるベクトルとが一致した場合、一致したベクトル集合S(δ)の要素を用い、P個の要素からなる第1有限集合内で閉じた特定の第1演算を、Q個の要素からなる第2有限集合内で閉じた第2演算の組合せで実現する演算式を特定する。
(もっと読む)
行列演算コプロセッサ
【課題】 プロセッサから行列要素を1個ずつしか受け取れない状況でも、行列乗算処理を高速実行可能な行列演算コプロセッサを提供する。
【解決手段】 制御部140は、行列A、Bの乗算結果である行列Qの要素を行毎に順次得るための制御を行う。行列要素レジスタ120は、行列Bの要素を記憶する。制御部140は、行列Qの1行分の要素を累算器111〜114から得るため、累算器111〜114を初期化し、行列Aの1行分の要素をCPU200から1個ずつ受け取る都度、受け取った要素を乗算器101〜104に送るとともに、当該要素を共通の乗算相手とする1行分の要素を行列要素レジスタ120から乗算器101〜104に送って乗算を行わせ、各乗算結果の累算を累算器111〜114に各々行わせる。
(もっと読む)
データの順列演算を実行するための装置および方法
順列演算を実行するための順列回路を有する処理回路と、データを格納するための複数のレジスタを有するレジスタバンクと、プログラム命令に応答して処理回路を制御し、データ処理演算を実行する制御回路と、を含む処理データのための装置が提供される。制御回路は、制御生成命令に応答して、ビットマスクに基づいて制御信号を生成し、入力オペランドに対して順列演算を実行するための順列回路を構成するように構成される。ビットマスクは、第1の順序を有する第1のグループのデータ要素と第2の順序を有する第2のグループのデータ要素とを前記入力オペランド内で特定し、順列演算は、前記第1の順序と前記第2の順序とのうちの一方を保存するが、前記第1の順序と前記第2の順序とのうちの他方を変える。  (もっと読む)
(もっと読む)
スキャン演算を遂行するシステム、方法、及びコンピュータ・プログラムプロダクト
【課題】スキャン演算を効率的に遂行するシステム、方法、及びコンピュータ・プログラムプロダクトを提供する。
【解決手段】使用中に、並列処理装置アーキテクチャを利用することによって、要素の配列がトラバースされる。そのような並列処理装置アーキテクチャは複数のプロセッサを含み、各プロセッサは物理的に所定数のスレッドを並列に実行することができる。効率を目的として、少なくとも1つのプロセッサの所定数のスレッドは、該所定数のスレッドの関数である数(例えば、倍数)の要素を伴うスキャン演算を遂行するように実行されることができる。
(もっと読む)
重複オペランドを使用したSIMDの内積演算
データ処理システム(10)は、複数の汎用レジスタ(34)と、少なくとも2つの内積を同時に実行するためのベクトル内積命令を含む1つ以上の命令を実行するためのプロセッサ回路とを含む。ベクトル内積命令は、各々複数のベクトル要素を格納するための第1および第2のソースレジスタを特定する。第1の内積は、第1のソースレジスタのベクトル要素の第1のサブセットと第2のソースレジスタのベクトル要素の第1のサブセットとの間で実行され、第2の内積は、第1のソースレジスタのベクトル要素の第2のサブセットと第2のソースレジスタのベクトル要素の第2のサブセットとの間で実行される。第2のソースレジスタの第1および第2のサブセットは異なり、第2のソースレジスタの第1および第2のサブセットの少なくとも2つのベクトル要素が重複している。  (もっと読む)
(もっと読む)
高速かつ効率的な行列乗算ハードウェアモジュール
【課題】可変の数の乗算器−加算器を提供すること。
【解決手段】複数の乗算器−加算器ユニットを備えている行列乗算デバイスであって、該複数の乗算器−加算器ユニットのそれぞれが、積の値を生成するために2つのデータ要素を乗算する乗算器回路と、結果値を生成するために該積の値を被加数の値で加算する加算器回路とを備えており、乗算演算が第1の行列と第2の行列とにおいて実行されるときに使用される乗算器−加算器ユニットの数は、乗算演算が実行されているのが、第1の行列のどの行に対応するどの計算ステージであるかに依存して変化する、デバイス。
(もっと読む)
多数の再配置可能な回路(FPGA等)による行列式等計算方法
【課題】フロントエンド計算機にFPGA等搭載ボードをPCIバス等で接続して特定方程式の高速計算を実現する。また、計算実行に当たっては、多くの人々が利用しているFortran等から容易に利用可能な仕組みを提供することにより利便性を向上を併せて可能にすることにある。
【解決手段】FPGA等、素子の並列処理機能を利用し、方程式解法に特化・最適化した論理回路を事前編成(n段のパイプラインをM本並列動作可能な状態を準備)させることによって、アプリケーションプログラムから与えられた計算コードの高速計算実現を図る。また、C言語等の高級言語から引数を伴ったサブルーチンコールを実現することにより利便性を高める。
(もっと読む)
演算装置及びプログラム
【課題】パターン認識装置に好適な次元削減行列Aを算出することのできる演算装置を提供する。
【解決手段】情報処理装置は、パターン認識装置にて認識するクラス毎に、当該クラスに属するパターンの特徴ベクトルのサンプルを取得すると共に、クラス内分散を定義付ける値mとして、実数値の入力を受け付けるための入力画面を表示装置に表示し、ユーザインタフェースから、値mを取得する(S130)。そして、取得したサンプルの一群に基づいて、各クラスの平均ベクトルμi及び全クラスの平均ベクトルμ0を算出する(S140,S150)と共に、クラス間共分散行列B及び各クラスの共分散行列Wiを算出し(S160,S170)、これらの値に基づき、クラスの総数をL、第iクラスの事前確率をPiとする評価関数J(A,m)が最大となる次元削減行列Aを求める。
(もっと読む)
基準行列の推定逆行列を生成する方法、第2のプロジェクタからの第2の投影画像を用いて第1のプロジェクタからの第1の投影画像をシミュレートする方法、投影画像を生成する方法および投影システム
【課題】複雑な表示システムにおける光輸送のモデル化。
【解決手段】第1のプロジェクタにより生成された画像は第2のプロジェクタにより、2
つのプロジェクタを共通視点、好ましくはカメラから見た視点、に関連づけることで再現
される。第1の光輸送行列T¬1が取り込まれ第1のプロジェクタがカメラに関連付けら
れる。次に第2の光輸送行列T¬2が取り込まれ第2のプロジェクタがカメラに関連付け
られる。第1のプロジェクタにより投影される第1画像p1を第2のプロジェクタにより
再現するために、第2のプロジェクタは(T2-1)*(T1*p1)と定義される歪んだ画
像を投影する。本方程式に用いられるT2の逆は、まずT2と等しいサイズの中間行列Ξを
生成することにより定義される推定である。T2の列をTrで示し、Ξの対応列をΞrで
示した場合、Ξの構造および入力はΞr=Tr/(‖Tr‖)2と定義され、T2の逆はΞ
の数学的転置であると推定される。
(もっと読む)
リストベクトル処理装置及び方法
【課題】より高速な計算を可能にするリストベクトル処理装置及び方法を提供する。
【解決手段】クロックサイクル1で出力された第1ベクトルデータの最後のベクトル要素を含み、同一のアドレスを持つベクトル要素が連続している領域である第1連続領域に含まれるベクトル要素のうち、要素番号が最若のものが見つけられ、先頭要素番号として設定される。クロックサイクル1の最後のベクトル要素のアドレスと、次のクロックサイクル2で入力された第2ベクトルデータの先頭のベクトル要素のアドレスとが比較され、先頭のベクトル要素を含み、同一のアドレスを持つベクトル要素が連続している連続領域が検出される。その連続領域に含まれるベクトル要素のうち、要素番号が最後のものが末尾要素番号として設定され、示されるアドレスに基づいてメモリがアクセスされ、情報が読み出される。他のベクトル要素に対しては、その読み出された情報が返される。
(もっと読む)
並列演算システム
【課題】複数の演算装置を用いて行列の積を求める並列演算システムで、演算装置間のネットワークの通信路の数を少なくし、経済的なネットワークを構築することを、本発明の目的とする。
【解決手段】本発明の並列演算システムでは、行列Aのm行n列目の成分amn(mは1〜Mの整数、nは1〜Nの整数)の演算を行う演算装置は、成分a(m−1)n(ただし、m−1=0の場合はaMn)、成分a(m+1)n(ただし、m+1=M+1の場合はa1n)、成分am(n−1)(ただし、n−1=0の場合はamN)、または成分am(n+1)(ただし、n+1=N+1の場合はan1)の演算を行う演算装置としか通信しない。したがって、これらの通信路を確保するネットワークを構築する。
(もっと読む)
1 - 20 / 31
[ Back to top ]