
Fターム[5B064EA18]の内容
Fターム[5B064EA18]の下位に属するFターム
Fターム[5B064EA18]に分類される特許
21 - 40 / 116
辞書更新装置及び辞書更新プログラム並びに文字認識装置及び文字認識プログラム。

【課題】認識用辞書ファイルを容易に低コストで更新できるようにし、手書き文字等の文字認識精度を向上させる。
【解決手段】入力部11は、入力された画像データから当該画像データに付随する付随データを抽出する。メタデータ生成部12は、付随データからその付随データの属性と値とがセットされたメタデータを生成する。外部システム連携部16は、辞書選択ルールに定義された外部システムに当該辞書選択ルールに定義された命令を与えその結果を取得する。辞書選択部13は、外部システムから得られた情報とメタデータとを基に辞書選択ルールを判定し、成立するルールに定義された辞書ファイルを選択する。辞書更新部14は、選択された辞書ファイルに対して設定された辞書更新ルールを判定し、成立する辞書更新ルールに定義された更新内容に従いそのルールに設定された辞書ファイルを更新する。
(もっと読む)
文字列認識装置及び文字列認識方法

【課題】開示技術は各種の文字から構成される文字列を効率的に認識する。
【解決手段】開示技術の実施例に係る文字認識方法は、文字列画像を複数のセグメントに分割するステップと、複数のセグメントに対してOCR認識を行って、候補文字を取得するステップと、候補文字の統計情報及び/又は候補文字によって形成される文字組み合わせの統計情報を取得するステップと、統計情報と候補文字のOCR認識の信頼度を統合して、候補文字列を確定するステップとを含む。そして、開示技術は文字列認識装置を提供する。
(もっと読む)
画像処理装置及び画像処理プログラム
【課題】文字情報と文字画像が混在している文書の文字画像を認識する場合において、文字画像を単独で認識する場合に比べて認識率を向上させるようにした画像処理装置を提供する。
【解決手段】画像処理装置の文書受付手段は、文字情報と文字画像が混在している文書を受け付け、文字情報抽出手段は、前記文書受付手段によって受け付けられた文書から文字情報を抽出し、文字画像抽出手段は、前記文書受付手段によって受け付けられた文書から文字画像を抽出し、文字認識手段は、文字画像を認識し、文字認識制御手段は、前記文字画像抽出手段によって抽出された文字画像の周辺に位置する文字情報に基づいて、該文字画像を前記文字認識手段に認識させるように制御し、文書整形手段は、前記文字情報抽出手段によって抽出された文字情報と前記文字認識手段による認識結果に基づいて、前記文書を整形する。
(もっと読む)
電子文書処理装置及びプログラム
【課題】文字画像と文字情報とが混在した電子文書に対する文字認識の精度を向上させる。
【解決手段】電子文書処理装置10は、文字情報と文字画像とを含む電子文書を取得し、電子文書に含まれる文字情報と文字画像の少なくとも一部を処理対象文字列に設定し、処理対象文字列に含まれる少なくとも1つの文字画像を文字認識した結果得られた複数の文字候補を、その評価値と共に生成する。また、電子文書処理装置10は、複数の文字情報に対して他の文字情報との共起関係に基づく関係評価値を保持し、複数の文字候補毎に、処理対象文字列に含まれる少なくとも1つの文字情報との共起関係に基づく関係評価値を取得し、複数の文字候補毎の、生成された評価値と、取得された関係評価値とに基づく評価に応じて、複数の文字候補の中から文字認識した文字画像に対応する文字情報を選択する。
(もっと読む)
カメラで取得されたドキュメント用の低解像度のOCR
【課題】2値化タイプのプロセス、セグメント化、および認識を結合して単一のプロセスにする、低解像度の撮影されたドキュメントの光学式文字認識(OCR)用のグローバル最適化フレームワークを提供する。
【解決手段】このフレームワークは、大量のデータ上でトレーニングされる機械学習アプローチを含む。コンボリューショナルニューラルネットワークを採用して、複数の位置において分類関数を計算し、2値化を不要とする中間調の入力を受け入れることができる。このフレームワークは、前処理、レイアウト分析、文字認識、および単語認識を活用して、高い認識率を出力する。またこのフレームワークは、ダイナミックプログラミングおよび言語モデルも採用して、希望の出力に到達する。
(もっと読む)
誤認識文字自動変換システム
【課題】従来の技術では、誤文字の辞書マスタを有しているが、マスタへの登録機能がないため、誤文字を誰が、何を基に、どのようにマスタへ反映するかという問題がある。また、誤認識文字を修正する機能はあるが、1つ以上の修正候補より人為的に選択する必要がある。
【解決手段】画像データを文字認識する文字認識処理部120と、文字認識した結果を格納する情報データベース(D1,D2)と、文字認識において誤認識された誤文字と正しい文字を正誤辞書マスタデータベース(D3)へ登録する正誤辞書マスタ登録処理部330と、前記正誤辞書マスタデータベース(D3)に登録された誤文字により、前記情報データベース(D1,D2)に格納されている既存データを全て一括修正する文字正誤チェック処理部250と、を備える
(もっと読む)
画像処理装置、画像形成装置、画像処理方法、コンピュータプログラム及び記録媒体
【課題】原稿の種類の区別無く読み取られた画像データに対しても、文字の認識精度を高めることが可能な画像処理装置、画像形成装置、画像処理方法、並びに前記画像処理装置を実現するためのコンピュータプログラム及び該コンピュータプログラムを記録した記録媒体を提供する。
【解決手段】画像処理装置2のA/D変換部20が受け付けた画像データに基づく画像より、原稿検知部23が、画像入力装置1で読み取られた原稿のサイズを検出して原稿の種類を判定し、判定された原稿の種類が名刺以外の一般原稿の場合(又は名刺の場合)、文字認識部31a(又は31b)が文字を認識し、フォーマット化処理部32a(又は32b)が、認識された文字が埋め込まれたPDF形式の画像データ(又はvCardのデータ)を生成し、送受信装置5が生成されたデータを外部にイメージ送信する。
(もっと読む)
情報入力装置および情報入力方法
【課題】利用者が所望する情報を幅広い情報源から読み取ることで、利用者の情報入力にかかる労力を低減すること。
【解決手段】撮影部13に対して文書を配置した利用者から撮影指示を受け付けると、撮影画像生成部17aは、撮影画像を生成し、表示制御部17bは、撮影画像を表示部12のモニタにて表示するように制御する。そして、情報認識部17cは、モニタに表示されている表示範囲または利用者が指定した指定範囲にて文字列認識処理を実行し、表示制御部17bは、利用者が所望する処理を指定するための指定一覧をタッチパネルとして表示部12のモニタにて表示するように制御する。端末制御部17dは、利用者により処理内容が指定された場合、通信部14を介して、処理内容に該当するアプリケーションにて、認識された文字列を用いた処理が実行されるように制御する実行指示を利用者端末20に送信する。
(もっと読む)
知識補正プログラム、知識補正装置および知識補正方法
【課題】文字が分離して文字認識された場合にも、適正な文字列の特定精度を向上すること。
【解決手段】誤読候補情報記憶手段1aは、複数の補正文字列それぞれに含まれる文字を複数の文字に分離した1つ以上の分離文字列を含む誤読候補文字列を各補正文字列に対応付けて定義した誤読候補情報を記憶する。認識結果文字列生成手段1bは、画像情報2に含まれる文字列の候補として認識結果文字列3を生成する。文字列比較手段1cは、誤読候補情報記憶手段1aに記憶された誤読候補情報を参照して、各誤読候補文字列のうち、認識結果文字列3に最も一致する誤読候補文字列を特定し、この誤読候補文字列に対応する補正文字列4を特定する。出力手段1dは、文字列比較手段1cが特定した補正文字列4を出力する。
(もっと読む)
検索プログラム及び検索方法
【課題】スキャナ等で読み込まれた文書情報における文字認識誤りを考慮した文字列検索を実現する。
【解決手段】文字格納部104は、第1の文字と、第1の文字に対応する誤認識文字等である第2の文字を格納し、派生文字列生成部105は、文字格納部104を参照して、検索文字列に含まれる第1の文字を第2の文字に置き換えた派生文字列を生成する。検索部107は、文書格納部103に格納された検索対象文書から、検索文字列及び派生文字列を検索し、出力部113は、検索文字列及び派生文字列の検索結果を出力する。
(もっと読む)
パターン認識プロセッサのためのバス
開示されているのは次のような方法およびシステムである。パターン認識プロセッサ(14)、そのパターン認識プロセッサ(14)にパターン認識バス(96)を介して接続される中央処理装置(CPU)(20)、およびCPU(20)にメモリバス(98)を介して接続されるメモリ(100)を有するシステム(94)である。幾つかの実施形態において、パターン認識バス(96)およびメモリバス(98)は、それぞれパターン認識プロセッサ(14)およびメモリ(100)に対するほぼ同数の接続を形成する。 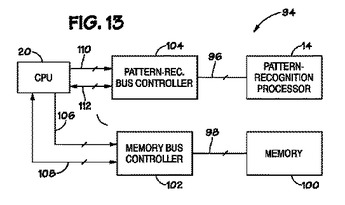 (もっと読む)
(もっと読む)
パターン認識方法、文字認識方法、パターン認識プログラムおよび文字認識プログラム
【課題】効率的にパターンを認識する処理を行うことができるパターン認識方法、文字認識方法、パターン認識プログラムおよび文字認識プログラムを提供できる。
【解決手段】情報処理装置(11)は、複数段階の部分パターンからなるパターン全体を認識する処理において、各段階の認識候補となりうる各認識候補を検出し(S71)、各段階の各認識候補に属する次の段階の認識候補を展開し(S75)、展開された各認識候補に対して、認識処理済みの認識候補に対する全認識処理結果を条件とした事後確率に基づく評価値を算出し(S76)、算出した各認識候補に対する評価値が高い順に所定数の認識候補を選出し(S73)、選出された各認識候補に次の段階の認識候補がない終端の認識候補が含まれる場合(S74、YES)、前記終端の認識候補に対する評価値が所定の閾値以上であれば(S78、YES)、当該終端の認識候補に基づく各段階の認識候補の組合せを認識結果とする(S80)。
(もっと読む)
文書検索装置
【課題】電子文書やイメージ文書、これら混在文書等多様種文書の文字コード正規化は複数の方法を用いるが、正規化後の文字コードでヒットした検索スコアを各正規化法に応じたものにできない。
【解決手段】異なる処理をする等価文字テーブルと異体・異発音文字テーブルと分解合成文字テーブルと同型文字テーブルを備え、検索文書から電子テキスト抽出部での抽出文字コードには同型文字テーブル以外のテーブルを、文字認識部での文字認識された候補文字付きの文字コードには全テーブルを参照して正規化処理し、かつ正規化処理時の分解統合文字の座標位置情報を分解統合前の情報から算出し正規化文字コードと対応した検索インデックスを検索インデックス生成部で生成、検索処理部が全テーブルで検索キーワードを正規化し検索インデックスとの照合結果を検索スコアと共に出力する。
(もっと読む)
文字認識装置、文字認識方法、文字認識プログラムおよび記録媒体
【課題】 認識される文字列を辞書中の文字列に不適切に置き換えることを防止して、文字認識の精度を向上させることができる文字認識装置、文字認識方法、文字認識プログラムおよび記録媒体を提供する。
【解決手段】 文字認識部12が、認識対象文書10に含まれる文字列を認識する。類似度算出部15が、項目別修正辞書部14中の文字列について項目分類部13で分類された分類済文字列との類似度を算出して、類似度の最大値を示す類似文字列を決定する。閾値算出部17が、同一分類項目の更新日付と認識日付とに基づいて、認識対象文書10中に含まれる文字列が項目別修正辞書中に存在する可能性が高いか否かの度合いを示す閾値を算出する。修正制御部18が、類似度の最大値と閾値とを比較して、類似度の最大値が閾値以上の場合、分類済文字列を類似文字列に置き換え、類似度の最大値が閾値未満の場合、分類済文字列を類似文字列に置き換えない。
(もっと読む)
データベース合成装置、文字認識支援システム、及びデータベースの合成方法
【課題】対で用いられる住所名、郵便番号が登録された複数のデータベースの登録内容を効率的に統合する。
【解決手段】本発明のデータベース合成装置3は、住所名を階層的に区分して表す住所文字列階層データと、この住所文字列階層データに対応付けられた郵便番号データとのうちの、少なくとも一方が記憶された複数のデータベースを取得するデータベース取得部2と、取得された複数のデータベースから、住所文字列階層データ中の階層毎の要素をそれぞれ表す複数の部分文字列データと符号文字列データとを互いの対応関係と共に抽出する抽出部6と、抽出された抽出結果に基づいて、個々の部分文字列データとそれらの階層の関係を示す階層情報と符号文字列データとを互いに関連付けて記憶させた合成データベース18を生成する合成部8とを備える。
(もっと読む)
健康保険証および免許証の記載情報の読み取り・デジタル伝送およびラベル発行する装置
【課題】わざわざ健康保険証や運転免許証の記載情報をコンピューターシステムに入力したり、設置されている複写機まで移動し複写しなくても、自動的にコンピューターシステムに入力されたり、客の目の前で、容易に貼り付け可能なラベルに複写するようにする。
【解決手段】保険証や免許証の読み取り口1を介して情報を中央演算処理装置2に取り入れ、必要な文字情報をコンピューターシステムに伝送すると同時に、複写機能制御部3に健康保険証や運転免許証のイメージ情報を伝送し、ラベル発行口4からラベルを複写発行する。
(もっと読む)
文字列認識装置及び方法、並びにプログラム
【課題】文字切出や文字認識の不確定さを伴う文字列認識において、文字列の品質低下に対するロバストな文字列認識処理を提供する。
【解決手段】文字切出や文字認識の不確定さを文字列仮説と呼ばれる有向グラフとしてモデル化する。準正規表現に基づいて定義された表記文法と、文字パタンの配置を規定する文字パタン配置辞書を用い、文字列仮説を、文法駆動と半順序構造に対応したビタビアルゴリズムにより解析することで、読取結果である文字列テキストを確定する。文法駆動に対応するためにビタビアルゴリズムをスタック計算方式に拡張し、更に半順序構造に対応するために変数縮約を用いたコスト関数の構造変形処理を採用する。これにより読取対象画像の劣化(ノイズ混入、文字欠落、接触等)に対してロバストな文字列表記解析を実現する。
(もっと読む)
プログラム、情報記憶媒体及び文字列認識装置
【課題】文字列を少ない文字数に解釈する傾向や、文字列を多い文字数に解釈する傾向を弱めて、認識率を向上させることが可能なプログラム、情報記憶媒体及び文字列認識装置を提供すること。
【解決手段】ストローク間のオフストロークのうち、仮切出しポイントとして設定するオフストロークを決定し、前記仮切出しポイントによって切り出された仮切出しユニット毎に文字認識を行い、候補文字列を生成する。前記仮切出しユニットは、隣接する前記仮切出しポイントにより切り出される最小仮切出しユニットを少なくとも1つ含む。前記候補文字列の各候補文字に対応する前記仮切出しユニットに含まれる前記最小仮切出しユニット、および隣接する前記最小切り出しユニット間の連結について、複数項目の確からしさを評価し、前記複数項目の確からしさについて各項目に与える重みの値を設定する。
(もっと読む)
画像処理装置、画像処理方法及びプログラム
【課題】精度よく適正な画像処理を実現する。
【解決手段】少なくとも文字コードを入力する入力手段と、入力された認識結果から文字列を切り出す文字列切り出し手段と、切り出した文字列を記憶する記憶手段と、切り出した文字列が、格納されている文字列と類似あるいは一致しているかどうか判定する判定手段と、類似文字列として比較した文字列を関連付ける関連付け手段と、関連付けされている類似文字列が一致文字列とみなせるかどうかを判定する文字列一致判定手段と、類似文字列に対して異なる文字を置き換える文字置換手段と、を有する。
(もっと読む)
領域抽出プログラム、文字認識プログラム、および文字認識装置
【課題】文字数が変動する正規表現で表された情報を効率良くかつ正確に文字認識すること。
【解決手段】文字ラティス生成部107は、文字列領域に対して文字別辞書を用いた文字認識を実行し、文字列における1文字分の単位領域とその接続関係を示す文字ラティスを生成する。認識信頼度算出部108は、正規ラティスおよび文字ラティスの単位領域の組み合わせについて認識信頼度から成立可能性を判定し、成立する可能性がある組み合わせをノードとする対応テーブルを生成する。パス生成部109は、対応テーブルにおいて、ノードを連結してパスを生成する。最適パス決定部110は、対応テーブルにおけるパスのうち再現率および適合率が最大のパスを最適パスと決定する。対象領域抽出部111は、最適パスに対応する文字ラティスの単位領域を含む領域を、最終的に文字認識の対象となる対象領域として抽出する。
(もっと読む)
21 - 40 / 116
[ Back to top ]