
Fターム[5B080CA04]の内容
Fターム[5B080CA04]に分類される特許
1 - 20 / 108
画像処理用のタイルレンダリング
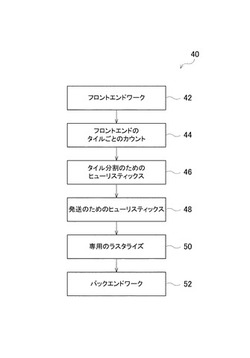
【課題】実際に、バックエンドワークを実行することなく、当該バックエンドワークに要する時間を推算し、タイルを分割する方法を提供する。
【解決手段】フロンドエンドのカウンタが、コストモデルおよびヒューリスティック(heuristic)関する情報であって、タイルを分割して、順序付けられたワークをコアに配送するときに用いられる可能性のある情報を記録する。専用のラスタライザ(specialrasterizer)は、サブタイルの外側の三角形状および断片を放棄する。
(もっと読む)
コンピュータ・グラフィックス回路及びこの回路を用いて、二次元表示システムに表示される三次元オブジェクトに適用される二次元擬似ランダム・テクスチャ・パターンを、一次元テクスチャ画像を用いて生成する三次元コンピュータ・グラフィックス装置

【課題】コンピュータ・システムにおいて二次元テクスチャ座標を算出するシステムにおいてメモリサイズ及び回路サイズの問題を解決する。
【解決手段】二次元テクスチャ座標(u,v)を求め、前記座標u及びvを用いて2つのランダム値の一次元区間を2個生成し、前記ランダム値の一次元区間2個を結合して、4つのランダム値の二次元区間を1個生成し、前記テクスチャ座標(u,v)及び前記4つのランダム値の二次元区間に応じて、ランダム値を生成し、前記ランダム値と前記入力テクスチャ座標(u,v)を結合して、変換された前記二次元テクスチャ座標(u’,v’)を得る。
(もっと読む)
仮想GPU
【課題】仮想グラフィックス処理装置(VGPU)に関する技術及び構造を開示する。
【解決手段】ソフトウェアにとっては、VGPUが独立したハードウェアGPUのように映る。しかしながら、制御構造を使用することにより、及びGPUのいくつかの(ただし全てではない)ハードウェア要素を複写することにより、同じGPU上に2又はそれ以上のVGPUを実装することができる。例えば、複数のVGPUをサポートするGPU内に追加のレジスタ及び記憶スペースを加えることができる。サポートされる異なるVGPUに対応するタスク及びスレッドに、異なる実行優先度を設定することができる。異なるVGPUの仮想アドレス空間の使用を含めて、VGPUのメモリアドレス空間を管理することもできる。異なるVGPUの実行を中断及び再開することにより、より細かい粒度の実行制御及びより良いGPU効率を可能にすることができる。
(もっと読む)
グラフィックスプロセッサ上の物理シミュレーション
【課題】本発明は、少なくとも1つのグラフィクスプロセッサユニット(GPU)上で物理シミュレーションを行うための、方法、コンピュータプログラム製品、およびシステムに向けられる。
【解決手段】該方法は、以下のステップを含む。まず、少なくとも1つのメッシュに関連した物理属性を表すデータは、複数のメモリアレイに格納されることによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。ついで、少なくとも1つのピクセルプロセッサを用いて複数のメモリアレイにおけるデータに演算が行われることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す変更されたデータは、複数のデータメモリに格納される。
(もっと読む)
グラフィック・パフォーマンス改善のための方法、装置およびコンピュータ・プログラム・プロダクト
【課題】デジタル表現されたグラフィックの生成のパフォーマンスを改善する方法を提供する。
【解決手段】本方法は:基本プリミティブの第一の表現を受領し;バーテックス位置決定に関連付けられた命令の組を提供し;前記基本プリミティブの前記第一の表現に対して、有界算術を使って前記の取得された命令の組を実行して、前記基本プリミティブの第二の表現を提供し;前記基本プリミティブの前記第二の表現を選別プロセスにかけることを含む。対応する装置およびコンピュータ・プログラム・プロダクトも提示される。
(もっと読む)
衝突検出システム、ロボットシステム、衝突検出方法及びプログラム
【課題】衝突検出対象オブジェクトの正確な衝突判定を実現できる衝突検出システム、ロボットシステム、衝突検出方法及びプログラム等の提供。
【解決手段】衝突検出システムは処理部と描画部と深度バッファーを含む。深度バッファーには、対象面に配置設定されるオブジェクトの深度情報を深度マップ情報が設定される。描画部は、深度テストを行って、深度バッファーを参照しながら、衝突検出対象オブジェクトを構成するプリミティブ面のうち、所定の視点から見て裏面のプリミティブ面を描画する第1の描画処理を行う。また深度テストを行わずに、衝突検出対象オブジェクトを構成するプリミティブ面のうち、視点から見て裏面のプリミティブ面を描画する第2の描画処理を行う。処理部は、第1の描画処理と第2の描画処理の結果に基づいて、衝突検出対象オブジェクトが対象面のオブジェクトと衝突したか否かを判定する衝突判定を行う。
(もっと読む)
グラフィックス処理
【課題】頂点シェーディング段階がインスタンス化されたモードで動作している場合の、頂点シェーディング段階を含むグラフィックスプロセッサの動作を改善すること。
【解決手段】グラフィックスプロセッサは、頂点バッファからの入力属性値を処理して、画像を処理する時にラスタライザ/フラグメントシェーダにより用いられることになる、出力である頂点シェーディングされた属性値を生成する、頂点シェーダを含む。頂点シェーダ出力属性の依存する頂点シェーダ入力属性が頂点毎にのみまたはインスタンス毎にのみ定義される、頂点シェーダ出力属性が識別される。次いで、そのような頂点シェーダ出力属性に対し、頂点シェーダは、所与の頂点またはインスタンスの頂点シェーダ出力属性の1つのコピーのみを、画像を処理する際にグラフィックスプロセッサのラスタライザ/フラグメントシェーダ22が用いるために格納する。
(もっと読む)
グラフィックス処理
【課題】頂点シェーディング段階を含むグラフィックスプロセッサの動作を改善すること。
【解決手段】グラフィックスプロセッサは、頂点バッファからの入力属性値を処理し、画像を処理する時にグラフィックスプロセッサのラスタライザ/フラグメントシェーダにより用いられる、出力である頂点シェーディングされた属性値を生成する頂点シェーダを含む。システムは、頂点シェーダ入力属性値から頂点シェーダにより生成される頂点シェーダ出力属性値が、いつ、頂点シェーダ入力属性値のコピーになるかを認識する。この場合、頂点シェーダ20は、コピーの頂点シェーダ出力属性値を生成しないが、ラスタライザ/フラグメントシェーダ22が、対応する頂点シェーダ入力属性値を、本来は頂点シェーダ20の頂点シェーダ出力属性値の代わりに処理する。
(もっと読む)
グラフィックスプロセッサの並列アレイアーキテクチャ
【課題】高い並列度を維持したままで、異なるシェーダーの変動する負荷に適応できるグラフィックスプロセッサを提供する。
【解決手段】グラフィックスプロセッサの並列アレイアーキテクチャは、複数の処理クラスタを含み、各処理クラスタがカバレッジデータから画素データを生成するピクセルシェーダープログラムを実行する少なくとも1個の処理コアを含む、マルチスレッド型コアアレイと、複数の画素のうちの1画素毎にカバレッジデータを生成するラスタライザと、ラスタライザからマルチスレッド型コアアレイ中の処理クラスタのうちの1つにカバレッジデータを配信する画素分配ロジックとを含む。画素分配ロジックは、画像エリアの範囲内の第1画素の位置に少なくとも部分的に依存して第1画素のためのカバレッジデータが配信される処理クラスタのうちの1つを選択する。画素データが処理クラスタから適切なフレームバッファ区画へ直接的に配信される。
(もっと読む)
タイルベースのグラフィックスシステム及びこのようなシステムの動作方法
【課題】複数のタイルを含むグラフィックスデータ生成のための、タイルベースのグラフィックスシステムと、その動作方法、及びグラフィックス処理回路が提供される。
【解決手段】処理回路は、第1及び第2動作モード間で切換えられる。第1モードで処理回路は、フレーム用のグラフィックスプリミティブを受け取り、ビニング動作を行う。これにより複数のタイルそれぞれについて、グラフィックスプリミティブのうちタイルと交差するものを特定するリストを決定する。第2モードで処理回路は、割り当てられたタイルのタイルリストを受信し、ラスタライゼーション動作を行う。この動作ではタイルリストに応じて、割り当てられたタイルについてグラフィックスデータを生成する。その結果、ビニング動作およびラスタライゼーション動作で同じ処理単位を使用でき、性能およびエネルギー消費を向上でき、グラフィックスシステムのサイズも大幅に低減する。
(もっと読む)
グラフィックス処理装置
【課題】電力消費とチップ搭載スペースを抑制しつつ,高速処理が可能なグラフィックス処理装置を実現する。
【解決手段】入力されるプリミティブを構成するピクセルに対して予め決められた処理を行う固定機能パイプライン4と,プログラム可能なプログラマブルパイプライン5とを備え,固定機能パイプライン4においては,ピクセル単位での固定された演算処理を行う固定フラグメントシェーダが設けられ,プログラマブルパイプライン5にはプログラマブルなピクセル単位での演算処理を行うプログラマブルフラグメントシェーダが設けられている。処理の内容によって,これらのプログラマブルフラグメントシェーダと,固定フラグメントシェーダとを使い分ける。
(もっと読む)
タイルベース・レンダリング・システムにおけるマルチコアの形状処理
【課題】多数のタイルベースの並列コアにわたるタイリング処理能力の向上。
【解決手段】多数の独立型タイルベース・グラフィック・コアを組み合わせるための方法及び装置が提供される。入ってくる形状ストリームは、複数のストリームに分割され、それぞれのタイルベースのグラフィックス処理コアに送られる。それぞれが別個のタイリングされた形状リストを生成する。これらは、マスター・タイリング・ユニットに組み合わせることができ、或いは代替的に、マーカーをタイリングされた形状リストに挿入することもでき、このマーカーがラスター化段階で用いられ、異なる形状処理コアからのタイリング・リスト間で切り替えを行なう。
(もっと読む)
画像処理装置
【課題】シェーダステージにおける入出力データをより簡易な形で管理することができるようにする。
【解決手段】インデックストランスレータ166が入力インデックスバッファの解析を行い,同インデックスバッファ上の入力データが既にシェーダステージにおいて処理が実行された否かの判定を実施する。処理がまだ実行されていない場合には,入力値,及び出力値への参照情報を前記タスクキュー上に作成する工程と,出力値への記憶領域を前記出力アドレスバッファ,及び出力インデックスバッファに割り当てる工程と,入力値,及び出力値への参照情報をタスクキュー上に作成してシェーダステージにおける処理が完了したことを示す工程とを実行する。出力インデックスバッファ,及び出力アドレスバッファの出力値は,以降に続くステージへの入力値として再利用される。
(もっと読む)
グラフィックスプロセッサ上の物理シミュレーション
【課題】グラフィクスプロセッサを提供すること。
【解決手段】本発明は、少なくとも1つのグラフィクスプロセッサユニット(GPU)上で物理シミュレーションを行うための、方法、コンピュータプログラム製品、およびシステムに向けられる。該方法は、以下のステップを含む。まず、少なくとも1つのメッシュに関連した物理属性を表すデータは、複数のメモリアレイに格納されることによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。ついで、少なくとも1つのピクセルプロセッサを用いて複数のメモリアレイにおけるデータに演算が行われることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す変更されたデータは、複数のデータメモリに格納される。
(もっと読む)
グラフィックスプロセッサ上の物理シミュレーション
【課題】グラフィクスプロセッサを提供すること。
【解決手段】本発明は、少なくとも1つのグラフィクスプロセッサユニット(GPU)上で物理シミュレーションを行うための、方法、コンピュータプログラム製品、およびシステムに向けられる。該方法は、以下のステップを含む。まず、少なくとも1つのメッシュに関連した物理属性を表すデータは、複数のメモリアレイに格納されることによって、シーンに描写される少なくとも1つのメッシュの運動を支配する線形方程式系を設定する。ついで、少なくとも1つのピクセルプロセッサを用いて複数のメモリアレイにおけるデータに演算が行われることによって、時刻に対する線形方程式系を解く。ここで、時刻に対する線形方程式系に対する解を表す変更されたデータは、複数のデータメモリに格納される。
(もっと読む)
デプスエンジンの動的な再配置を用いたグラフィックシステム
【課題】デプスエンジンの動的な再配置を用いたグラフィックシステムを提供する。
【解決手段】グラフィックシステムは、グラフィック画像を処理するように構成された複数のユニットと、選択値に基づいて2つのユニットのうちの1つから選択されたデータを受信し、処理するように構成されたデプスエンジンとを備えるグラフィックプロセッサを含む。
(もっと読む)
タイル化されたプリフェッチ及びキャッシングされたデプスバッファ
【課題】3Dグラフィックス処理において、深さタイルのキャッシュを供給するプリフェッチメカニズムをパイプライン化する。
【解決手段】プリフェッチメカニズムは、予測的で、前のパイプライン段階からの三角形幾何情報を用いて前記キャッシュに予め装填することができ、それによってメモリ帯域幅効率の向上を可能にすることができる。電力消費量のさらなる低減及びメモリ帯域幅を考慮してz値圧縮技術をオプションで利用可能である。
(もっと読む)
拡張されたプリミティブの頂点キャッシュの処理を加速する装置
【課題】 本発明は,3次元コンピュータグラフィックスにおいて用いられるアルゴリズムなどにおける入力情報として用いられる,再分割表面パッチや,NURBSパッチ,隣接する三角形など,拡張された幾何学的プリミティブに関するチップ上のプロセッシングに関する問題を解決することを目的とする。
【解決手段】上記課題は,3次元コンピュータグラフィックスに用いられるシステムであって,初期頂点バッファストア(Primary Vertex Cache Store, PVC)と,頂点プロセッシングユニット(VPU)と,第2の頂点キャッシュストア(SVC)と,プリミティブエンジン(PE)と,固定プリミティブアセンブリ(FPA)と,頂点キャッシュ制御装置(VCC)とを具備するシステムなどにより解決される。
(もっと読む)
レンダリングプロセッサ
【課題】 複数のレンダラを用いて画像の描画処理を行う場合に、より簡便な方法でもってこの描画処理を実現するための技術を提供すること。
【解決手段】 メインプロセッサ102は描画命令101を用いて、描画対象画像を構成する各画素のエッジ情報及び色情報を収集し、収集したそれぞれの画素のエッジ情報及び色情報を、後段のサブプロセッサ103に送出する。サブプロセッサ103は左方の矩形領域のエッジ情報及び色情報をサブプロセッサ104に送出し、右方の矩形領域をレンダリングし、サブプロセッサ104から処理待ち信号を受けると、レンダリング結果をサブプロセッサ104に送出する。サブプロセッサ104は、左方の矩形領域をレンダリングし、レンダリング結果を外部に送出すると共に、サブプロセッサ103に処理待ち信号を送出することで取得した右方の矩形領域のレンダリング結果を外部に送出する。
(もっと読む)
画像処理用のタイルレンダリング
【課題】実際に、バックエンドワークを実行することなく、当該バックエンドワークに要する時間が推算されうる。
【解決手段】フロンドエンドのカウンタが、コストモデルおよびヒューリスティック(heuristic)関する情報であって、タイルを分割して、順序付けられたワークをコアに配送するときに用いられる可能性のある情報を記録する。専用のラスタライザ(special rasterizer)は、サブタイルの外側の三角形状および断片を放棄する。
(もっと読む)
1 - 20 / 108
[ Back to top ]