
Fターム[5B091AA11]の内容
Fターム[5B091AA11]の下位に属するFターム
方言・標準語間 (5)
表意文字・表音文字間 (2)
Fターム[5B091AA11]に分類される特許
21 - 40 / 109
処理装置、処理方法、及び、プログラム
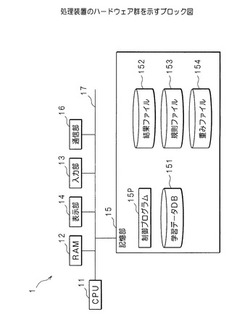
【課題】簡易な処理での抽出が可能となる処理装置等を提供する。
【解決手段】チャンク及び該チャンクを構成する一または複数の単語の種類を受け付ける。予め記憶部15に記憶したチャンク及びチャンクの種類と、受け付けたチャンク及び該チャンクを構成する一または複数の単語の種類とに基づき、チャンクに対する処理を選択する。チャンクを構成する一または複数の単語の属性を選択した処理に対応付けて記憶する。チャンク及びチャンクを構成する一または複数の単語に属性を付与する。単語の属性及び該単語の属性に対応する処理を記憶した記憶部15を参照し、単語に付与された属性に対応する処理を抽出し、抽出した処理を単語に適用する。
(もっと読む)
文章学習用ブロックおよび言語学習プログラムを格納するコンピュータで読み取り可能な記録媒体

【課題】文章を構成する各単語をブロックでイメージ化して結合する方式によって特定言語の構造を覚えさせる言語学習プログラムを格納するコンピュータで読み取り可能な記録媒体と文章学習用ブロックが提供される。
【解決手段】一実施形態の言語学習プログラムは、複数の単語(vocabulary)ブロックを格納する単語ブロックデータベースおよび前記複数の単語ブロックのうちから主語(subject)ブロック、動詞(verb)ブロック、および目的語(objective)ブロックが選択される段階と、前記動詞ブロックと前記主語ブロックが結合可能なペアであれば2つのブロックを並べて結合する段階と、前記結合したブロックの動詞ブロックの部分と前記目的語ブロックが結合可能なペアであれば2つのブロックを並べて結合して全体的に1つの文章を完成する段階とを実行するユーザインターフェースモジュールを含む。
(もっと読む)
対象文章に対する助詞落ち補完プログラム、装置、サーバ及び方法
【課題】対象文章情報について助詞落ちの有無を検出する共に、落ちた助詞を補完することによって、対象文章情報の解析精度を向上させることができる助詞落ち補完プログラム等を提供する。
【解決手段】助詞補完プログラムは、助詞落ち表現を含まない基準文章情報を蓄積した基準文章蓄積手段と、基準文章情報から、助詞を削除することによって助詞落ち文章情報を生成する助詞落ち文章生成手段と、助詞落ち文章情報を正例データとし、基準文章情報を負例データとして学習データベースを生成すると共に、該学習データベースを用いて、入力された対象文章情報から、助詞落ち箇所を特定する識別エンジン手段としてコンピュータを機能させる。
(もっと読む)
上位概念出力プログラム及び上位概念出力装置
【課題】対象とする語句が見出し語となっている概念が概念辞書中に存在しない場合において、対象とする語句の上位概念を出力する上位概念出力プログラム及び上位概念出力装置を提供する。
【解決手段】上位概念出力装置1は、語句を受け付ける表現受付手段100と、表現受付手段100により受け付けられた語句と関連する語句との関連度を計算し、当該関連度に基づいて関連する語句から関連語を検索する関連語検索手段101と、概念辞書111に基づいて、関連語を見出し語として持つ概念を抽出し、抽出された概念の上位概念を概念辞書111に基づいて抽出し、関連語と上位概念とこれらの概念の繋がりとから構成される部分木20を作成する部分木作成手段102と、概念の繋がりの形態に対応付けられた係数基づいて、関連度から上位概念のスコアを計算する関連度計算手段103と、上位スコアを有する上位概念を出力する概念出力手段104とを有する。
(もっと読む)
単語境界判定装置
【課題】より精度良く単語の境界を判定する。
【解決手段】単語境界判定装置1は、2文字以上から構成される一の文字列から、一の文字列の一部を構成する1文字以上の文字列(第1文字列)、および、一の文字列の一部を構成する1文字以上の文字列であって一の文字列において第1文字列に続く文字列(第2文字列)を抽出する抽出部22と、抽出された第1文字列、第2文字列の組合せ毎に、ラベル付学習データ内における、第1文字列に続く第2文字列の出現回数および非出現回数、並びに、第1文字列以外の文字列に続く第2文字列の出現回数および非出現回数を、第1文字列と第2文字列の間の単語境界の有無別に集計する集計部23と、該集計値を用いてモデル検定を行った上でモデル選択を行うことで一の文字列の特徴量を算出する特徴量算出部31と、該特徴量を使用した識別器14aを用いて未知文字列の単語境界を判定する単語境界判定部14とを備える。
(もっと読む)
語句分類処理装置、語句検索装置、文字入力支援装置、語句分類処理方法、語句抽出方法、文字入力支援方法、構文解析誤り修正装置、構文解析誤り修正方法、およびコンピュータ読み取り可能な記憶媒体
【課題】テキストデータの中から語句を自動的に抽出し分類する装置、方法、およびプログラムに関し、言語学的にまとまった単位の語句の自動抽出および分類を可能にする。
【解決手段】テキストデータ中の連文節あるいは文などの一次元文字列に含まれる語句を分類する装置であって、前記一次元文字列を構文解析して得た構文解析木の各々の部分木について、前記部分木中のフレーズの一次元列を生成し(S106)、フレーズと該フレーズの属性とを関連付けたフレーズ分類結果のデータベースを参照して、前記生成したフレーズの一次元列中の各フレーズの属性を抽出し(S104)、前記生成したフレーズの一次元列と前記抽出したフレーズの属性とから、前記フレーズの一次元列に対応する属性の一次元列を求め、該属性の一次元列とフレーズの一次元列とを関連付けた語句分類結果を生成してデータベースに格納する(S107,S108)。
(もっと読む)
トークスクリプト利用状況算出システムおよびトークスクリプト利用状況算出プログラム
【課題】談話データの構造を解析した結果に基づいて、各業務におけるトークスクリプトの利用状況を算出するトークスクリプト利用状況算出システムを提供する。
【解決手段】談話データ101および談話セマンティクス200を入力とし、トークスクリプトの利用状況300を出力するトークスクリプト利用状況算出システム1であって、談話セマンティクス200は簡約情報61を含み、簡約された談話データ101におけるブロックと各トークスクリプトとの間の類似度を算出し、最も類似するトークスクリプトを類似度情報71として出力する類似度算出部70と、トークスクリプト毎に、簡約された談話データ101における各ブロックのうち、最も類似するものが当該トークスクリプトでありかつ類似度が所定の閾値より高いブロックの数を算出し、対象の応対業務が行われた数に対する利用頻度を算出して利用状況300として出力する利用状況算出部80とを有する。
(もっと読む)
地域対応手話生成システム、地域対応手話生成方法、および地域対応手話生成プログラム
【課題】手話の地域性に対応し、聴覚障害者がより容易に、より迅速に情報を理解できるようにする。
【解決手段】地域対応手話生成システムであって、外部システム200から少なくとも1つのテキストを入力する入力手段111と、入力された各テキストについて第1の記憶手段101を参照して対応する手話IDを検索し、検索した手話IDに対応する手話表現映像を第2の記憶手段102から検索する検索手段112と、検索した各テキストの手話表現映像を出力する出力手段113とを備え、第1の記憶手段101は、地域毎に個別に作成され当該地域でのみ通用する特有の手話が存在するテキストについては当該地域用の手話表現映像の手話IDが記憶され、第2の記憶手段102には、地域を越えて通用する標準の手話表現映像と所定の地域でのみ通用する特有の手話表現映像とが記憶されている。
(もっと読む)
語順変換装置、機械翻訳用統計モデル作成装置、機械翻訳装置、語順変換方法、機械翻訳用統計モデル作成方法、機械翻訳方法、プログラム
【課題】非主辞後置型言語である原言語(例えば英語)の文の単語について、構文解析結果を用いて、主辞後置型言語の目的言語(例えば日本語)の語順に並び替えることを課題とする。
【解決手段】非主辞後置型言語である原言語の文の単語を、主辞後置型言語である目的言語の語順に並び替える語順変換装置100である。処理部101は、原言語の文について、その構造木のルートノードから始めてすべてのノードについて、その子ノードのうち、語順を変えるべきでないノード以外のノードに対して、主辞ノードを最後の位置に移動する処理を繰り返すことで、原言語の文の単語を目的言語の語順に並び替える。
(もっと読む)
文書平易化装置および平易化規則テーブル作成装置、ならびにプログラム
【課題】不要な変形規則を含まず、難解単語から平易単語への変形規則のみを自動的に獲得することのできる文書平易化装置および平易化規則テーブル作成装置を提供する。
【解決手段】平易化規則テーブル作成装置内では、置換可能単語対作成部が、辞書テーブル記憶部から読み出した単語と語釈文に基づき置換可能単語対として出力する。平易化規則候補認定部は、置換可能単語対に含まれる単語それぞれについて難易度データを読み出し、置換可能単語対が平易化規則となり得るか否かを認定する。文脈類似認定部は、置換可能単語対に含まれる単語に基づいて文脈類似データベース記憶部を読み出し、置換可能単語対に含まれる単語同士が文脈類似な関係にあるか否かを認定する。平易化規則テーブル書込部は、平易化規則候補認定部によって平易化規則となり得ると認定され且つ文脈類似認定部によって文脈類似な関係にあると認定された平易化規則を生成する。
(もっと読む)
辞書作成装置、辞書作成方法及び辞書作成プログラム
【課題】形態素解析に必要なシステム辞書に存在しない単語を拡張辞書にエントリさせることで当該解析に係る辞書の単語を拡充させる。
【解決手段】テキストデータから形態素解析の拡張辞書データを作成する辞書作成装置1であって、テキストデータからページデータを抽出するページ抽出部11と、前記ページデータからそのタイトルデータを抽出するタイトル抽出部12と、前記抽出したタイトルデータが形態素解析のシステム辞書データ16に存在しない場合に当該タイトルデータを前記形態素解析の拡張辞書のエントリデータとして格納するエントリ格納部14と、前記格納したエントリデータを形態素解析の拡張辞書データとして出力する拡張辞書データ出力部15を備える。
(もっと読む)
述部機能表現正規化方法、その装置及びプログラム
【課題】自然言語処理において文情報の中心となる述部を、その意味を出来るだけ変えずに最も単純な形に変換すること。
【解決手段】形態素解析部2で解析され、述部抽出部3で抽出された入力文の述部に対応する形態素毎の単語情報に対し、意味ラベル付与部4において、述部の意味に影響を与える機能表現の意味を表す意味ラベルと、各意味ラベルに対応する機能表現のリストとを少なくとも組み合わせてなる機能表現意味ラベル辞書1を用いて、機能表現を構成する機能語列の単語情報に意味ラベルを付与し、当該意味ラベルに従ってNULL削除部5及び冗長ルール適用部6において述部の意味に影響を与えない機能語及び冗長な機能語を削除し、活用生成部7で残りの入力文の述部に対応する形態素毎の単語情報に基づき、入力文の述部を生成する。
(もっと読む)
自然言語処理プログラム及び自然言語処理装置
【課題】第1及び第2の自然言語文の比較にあたり、これらの統語解析を行わない場合に比較して、両自然言語文の差異に関する情報を正確に出力できる自然言語処理プログラム及び自然言語処理装置を提供する。
【解決手段】自然言語処理プログラムは、第1の自然言語文を含む原文書データ、及び第1の自然言語文の一部が変更された第2の自然言語文を含む変更文書データ112を取得する取得ステップと、取得ステップで取得した第1の自然言語文及び第2の自然言語文をそれぞれ統語解析する解析ステップと、解析ステップで統語解析した第1の自然言語文の統語解析結果と第2の自然言語文の統語解析結果とを比較する比較ステップと、比較ステップにおける比較の結果に基づいて、第1の自然言語文と第2の自然言語文との差異に関する情報を出力する出力ステップとを有する。
(もっと読む)
未知語を含む文章を修正するための文章修正プログラム、方法及び文章解析サーバ
【課題】口語的な「くだけた表現」を含む文章情報であっても、未知語と判断されることのない、文章解析に適した文章に修正する文章修正プログラム等を提供する。
【解決手段】修正基準文章情報の集合を記憶した基準文章記憶手段と、基準文章記憶手段を用いて、解析対象文章情報の内容に類似する1つ以上の修正基準文章情報を検索する基準文章検索手段と、解析対象文章情報を形態素に分割し、未知語を抽出する未知語抽出手段と、未知語と、当該未知語に対する前方及び後方の少なくとも一方の隣接形態素とからなる検索キーを生成する検索キー生成手段と、修正基準文章情報の中から、検索キーを用いて、未知語に近似する1つ以上の修正ルールを検索する修正ルール検索手段と、修正ルールの中から、文章構成指標に基づいて1つの修正ルールを選択する修正ルール選択手段とを有する。
(もっと読む)
未知語を含む文章を修正するための文章修正プログラム、方法及び文章解析サーバ
【課題】口語的な「くだけた表現」で記述された文章情報であっても、未知語と判断されることのない、文章解析に適した文章に修正する文章修正プログラム等を提供する。
【解決手段】複数の修正基準文章情報を、複数のカテゴリに分類して記憶した基準文章記憶手段と、未知語を抽出する未知語抽出手段と、未知語と隣接形態素とからなる検索キーを生成する検索キー生成手段と、修正基準文章情報のカテゴリ毎に、検索キーを用いて、未知語に近似する1つ以上の修正ルール候補を検索する修正ルール検索手段と、カテゴリ毎に、修正ルール候補の中から、文章構成指標に基づいて1つの修正ルール候補を選択する修正ルール候補選択手段と、カテゴリ毎に選択された修正ルール候補について、当該修正ルールの文章構成指標に基づくスコアが最も高いカテゴリを選択するカテゴリ選択手段と、選択されたカテゴリに基づく修正ルールを選択する修正ルール選択手段とを有する。
(もっと読む)
対訳辞書拡張装置およびそのプログラム
【課題】本発明は、類義語の手話訳が日本語−手話対訳辞書に登録されていない場合でも、新たな日本語語彙の手話訳を得ることができる対訳辞書拡張装置を提供することを目的とする。
【解決手段】対訳辞書拡張装置1は、日本語−手話対訳辞書を拡張するものであり、類義語データが入力される入力端子10と、類義語データを記憶する対訳なし類義語記憶手段20と、日本語−手話対訳辞書を記憶する日本語−手話対訳辞書記憶手段30と、日本語−手話対訳辞書を拡張する日本語−手話対訳辞書拡張手段40と、更新信頼度を算出する更新信頼度算出手段50と、日本語−手話対訳辞書を出力する出力端子60とを備え、拡張した後の日本語−手話対訳辞書を繰り返し検索する。
(もっと読む)
情報処理装置、情報処理方法および情報処理システム
【課題】既存のプログラムを大幅に修正することなく、外部表示される文字列情報を変更する。
【解決手段】情報処理装置10は、表示部14と、表示される文字列情報が埋め込まれたプログラムソースから作成されたアプリケーションプログラムが稼動するアプリケーション稼動部12と、アプリケーションプログラムの稼動中に文字列情報を表示するべき状態となった場合、情報処理装置10における現在の状況情報に応じて上記文字列情報を変換し、変換後の文字列情報を変換前の文字列情報と差し替え、表示部14に表示させる文字列変換部13と、を備えている。
(もっと読む)
情報処理装置、情報処理方法、及びプログラム
【課題】文書データから文をより適切に抽出することを目的とする。
【解決手段】情報処理装置が、文字列データが含まれる複数のオブジェクトに係る文書データから、複数のオブジェクトの各々に含まれる文字列データと、複数のオブジェクトの各々を解析して得る解析結果情報とを抽出し、抽出した文字列データの各々を文の区切り毎に分割する処理を行い、分割する処理を行った後のデータを断片データとして抽出し、抽出した解析結果情報に基づいて抽出した断片データの各々を結合するか否かを判別し、結合すると判別した断片データの各々を結合することによって課題を解決する。
(もっと読む)
文章変換装置、方法及びプログラム
【課題】書き言葉を話言葉に変換する文章変換装置、方法及びプログラムを提供する。
【解決手段】現代語に関する文章変換装置1は、処理対象の文章を受け付ける文章受付部11と、受け付けた文章を複数の形態素に分割する形態素解析部13と、分割された複数の形態素の各々に対して所定の手段を適用して文章を変換する法則適用部14と、変換された変換後文章を出力する変換後文章出力部15と、を備え、所定の手段は、文末表現の形態素に対して適用する文末表現変換手段14Bと、左連接の動詞連用の形態素に対して適用する左連接動詞連用変換手段14Cと、左連接の未然形の形態素に対して適用する左連接未然形変換手段14Dと、格助詞連語の形態素に対して適用する格助詞連語変換手段14Eと、を有する。
(もっと読む)
辞書機能を備えた電子機器およびプログラム
【課題】効率的に所望の動詞の活用表を表示することが可能になる辞書機能を備えた電子機器を提供する。
【解決手段】動詞(活用表)番号にそれぞれ対応付けられた動詞活用表データベースと、動詞の語尾の文字数n(=6〜2)別に当該語尾n文字のスペルに前記動詞(活用表)番号を対応付けた動詞−動詞活用表対応テーブル(語尾6文字動詞テーブル)〜(語尾2文字動詞テーブル)とを備える。辞書検索された説明情報表示画面など、辞書情報が表示された状態で所望の単語を選択すると、この選択された単語が動詞である場合に、当該単語の原形の語尾n文字のスペルと一致するところの動詞−動詞活用表対応テーブルが、文字数nの大きいテーブル順に判断され、対応する活用表番号に従い動詞活用表データベースから動詞活用表が読み出されて表示される。
(もっと読む)
21 - 40 / 109
[ Back to top ]