
Fターム[5C122FJ04]の内容
Fターム[5C122FJ04]に分類される特許
81 - 100 / 264
画像表示システム、画像管理装置、画像表示装置、及びプログラム
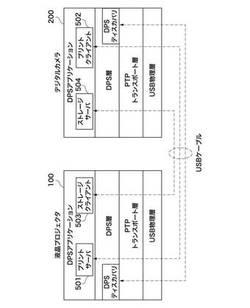
【課題】汎用性の高い通信規格を利用しつつ、表示装置が表示する画像をデジタルカメラ等の画像管理装置側の操作で加工することができる画像表示システムを提供する。
【解決手段】画像表示システムは、画像管理装置としてのデジタルカメラ200と、画像表示装置としての液晶プロジェクタ100とを、画像管理装置とプリンタとを接続するための汎用規格であるPictBridge規格に基づいてUSBケーブルにより接続して構成される。このシステムは、デジタルカメラ200の記録メディアに保存した画像をデジタルカメラ200の操作によって、液晶プロジェクタ100により表示し、デジタルカメラ200上で入力した画像処理の結果を液晶プロジェクタ100により表示された画像にも反映させる。
(もっと読む)
撮像装置

【課題】音声を記録する場合であっても、手振れ補正の際に発生する駆動音による音質の低下を低減する。
【解決手段】光学系により結像される被写体像から画像信号を生成する撮像素子と、前記光学系に含まれる補正光学系を光軸に直交する方向に駆動させて、前記撮像素子に結像される被写体像の振れを補正する第1の手振れ補正手段と、前記撮像素子を光軸に直交する方向に駆動させて、前記撮像素子に結像される被写体像の振れを補正する第2の手振れ補正手段と、前記第1の手振れ補正手段により前記手振れ補正光学系を予め定めた量駆動させたときの第1の駆動音圧と前記第2の手振れ補正手段により前記撮像素子を予め定めた量駆動させたときの第2の駆動音圧を取得する音圧取得手段と、音声と共動画像を撮像する際には、前記音圧取得手段によって取得された第1の駆動音圧と前記第2の駆動音圧のうち、発する駆動音圧が低い手振れ補正手段により振れを補正する。
(もっと読む)
ステータスアウェアネスを用いるハンドヘルド電子デバイス
ハンドヘルド通信デバイスは、ステータスアウェアネスにより、位置、アクティビティ、及び/またはユーザの肉体的または感情的状態を判断できる。この情報は様々な目的に用いることができる。例えば、1)ユーザに入来通信をどうやってアラートするかの判断、2)どのフォーマットを用いてユーザとコミュニケーションするかの判断、3)ユーザのステータスを他の人の通信デバイスにどうやって提示するかの決定などの目的である。  (もっと読む)
(もっと読む)
音声検出装置、音声検出方法及び撮像システム
【課題】室外の音声を確実に除外し、室内音源のみを検出すること。
【解決手段】互いに離間して配置された複数のマイクロフォン112A,112Bと、マイクロフォン112A,112Bで収音された音声情報の位相差に基づいて、マイクロフォンへの音声の入射角θを算出する音方向情報算出部132と、入射角θに基づいて、音源から発せられた音声の方向性を判別する音方向性判別部134と、マイクロフォン112A,112Bで収音された音声情報から、方向性が確定していると判断される音声情報のみを検出する音声検出部120と、を備える。
(もっと読む)
画像音響処理装置及び撮像装置
【課題】ユーザが意図する音響信号を容易かつ精度良く生成することを可能とする画像音響処理装置及び撮像装置を提供する
【解決手段】画像音響処理部30aは、入力画像を解析する画像解析部81と、画像解析部81の画像解析結果に基づいて入力音響信号の制御後の指向特性である目標指向特性を設定するとともに当該目標指向特性が実現されるように入力音響信号の指向特性を制御する指向特性制御部71と、目標指向特性を示す画像を入力画像に重畳させて表示画像を生成する表示画像生成部82と、を備える。ユーザは、指向特性制御部71に指向特性制御指示を入力することで、目標指向特性の設定方法を変更することができる。
(もっと読む)
携帯端末、電子カメラおよび連続撮影プログラム
【構成】携帯端末10は、音声を認識するための第2マイク16bおよびイメージセンサ38bとフォーカスレンズ38cとを制御するカメラ制御回路38aを備える。また、携帯端末10は、カメラ制御回路38aを制御することでカメラ機能を実行し、被写界の画像を撮影する。さらに、携帯端末10は、3秒毎に画像を撮影するベストショット撮影機能を実行することができる。そして、携帯端末10は、ベストショット撮影機能が実行されて、画像が撮影されるときに、音声が入力されると、その画像に識別情報を対応付けてフラッシュメモリ28またはメモリカード44に保存する。
【効果】使用者は、3秒毎に撮影される画像のうち、上手に撮影されたときに発話することで、ベストショットを容易に撮影および保存することができる。
(もっと読む)
情報再生方法及び情報再生装置
【課題】顔認識を利用した操作を基本として、同席している場合、再生する映像や音声を予め設定されている規則に従って選択して再生する情報再生装置および情報再生方法を提供する。
【解決手段】この発明の一つの実施の形態は、視聴者の顔を顔イメージ画像として取り込むカメラモジュールと、このカメラモジュールが取り込んだ顔イメージ画像から特徴点を抽出して符号化または文字列化する符号化モジュールと、この符号化モジュールにより符号化または文字列化された特徴点に従い、視聴者を特定する視聴者特定モジュールと、この視聴者特定モジュールにより特定された視聴者ごとに、再生が認められて情報を再生する情報再生モジュールと、を有することを特徴とする情報再生装置である。
(もっと読む)
再生装置及び再生方法
【課題】多数の音楽カードを次々に交換して音楽の効果を確認する作業を、簡潔な操作で行うことができるようにする。
【解決手段】内蔵固定メディア、リムーバブルメディアにアクセス可能であり、映像は内蔵固定メディア、音楽BGMはリムーバブルメディアから再生している場合、音楽BGMデータが記録されているリムーバブルメディアが新たに装着された場合には、前記新たに装着されたリムーバブルメディアに記録されている音楽BGMに切り替えて再生する。
(もっと読む)
撮影装置、表示装置、再生装置、撮影方法、および表示方法
【課題】撮影した動画を簡単に即座に楽しむことができる撮影装置、表示装置、再生装置、撮影方法、および表示方法を提供する。
【解決手段】動画の画像データを出力する撮像部2と、画像データに基づいて、画像の中に顔が含まれているか否かを判定する顔検出部3と、顔を識別するための識別用データが記憶された顔データベース4bと、顔検出部3による判定結果と、顔データベース4bに記憶された識別用データとに基づいて、画像データの中の顔が識別用データと一致するかを判定し、一致した場合には代表画像と決定する代表画像決定部1bと、代表画像決定部1bによって決定された代表画像を表示する表示部8とを有し、複数の動画の画像データから共通に登場する人物26を動画の最後に表示する。
(もっと読む)
自動音量制御出力装置
【課題】音声出力装置からの出力と雑音とを正確に区別でき、周囲の雑音に応じて適切な音量を出すことができる自動音量制御出力装置を提供する。
【解決手段】入力音声信号のレベルが一定期間に一定量以下かどうか監視して無音状態信号を出力する無音状態検知部105を設ける。入出力切替回路101は、無音状態信号を受信している期間に音声出力装置104を集音装置に切り替える。レベル演算部102は、無音状態信号を受信している期間内で音声出力装置104が集音した雑音に応じて演算した音量調整量をレベル検知信号として出力する。スピーカーアンプ率可変部103は、レベル検知信号を用いて入力音声信号の音量を調整し、音声出力装置104へ出力音声信号を供給する。音声出力装置104は、切替信号を受信していない期間では、スピーカーアンプ率可変部103から受けた出力音声信号を出音する。
(もっと読む)
撮影装置
【課題】 盗撮防止機能を備えた撮影装置を提供する。
【解決手段】 撮影装置は、被写体を撮影して画像データを生成する撮影手段と、該撮影手段に撮影を実行させるための撮影指示信号を送出する撮影指示手段と、撮影手段により生成された画像データを記憶する画像データ記憶手段と、所定の音を出力する音声出力手段と、該音声出力手段の特性データを検出する検出手段と、該検出手段によって検出された特性データと比較する特性基準データを記憶する特性基準データ記憶手段と、所定のタイミングで音声出力手段に所定の音を出力させ、この出力の際に前記検出手段によって検出された音声出力手段の特性データと特性基準データ記憶手段に記憶された特性基準データとを比較し、両者が不一致であると判定した場合、撮影手段により生成された画像データを画像データ記憶手段に記憶させないようにする規制手段と、を備えている。
(もっと読む)
撮像装置、録音レベル制御方法、録音レベル制御方法を実現するためのプログラムが記憶された記憶媒体
【課題】 近くから発せられる大きな音声から遠くで発せられる小さな音声まで、幅広い音量の音声を聞き取りやすい音声として録音可能な録音レベル制御機能を備えた撮像装置を提供する。
【解決手段】 本発明の撮像装置は、主制御手段と、表示手段と、動画像録画手段と、音声入力手段と、録音レベル制御手段と、を備え、録音レベル制御手段は、音声信号の利得を増減させる可変利得増減手段と、入力電圧値を基準電圧値に近づけるように可変利得増減手段を制御する自動利得制御手段と、動画像データから顔を認識する顔認識手段と、顔認識手段が認識した顔の寸法に対応した基準電圧値を算出する基準電圧値算出手段と、基準電圧値算出手段が算出した基準電圧値を自動利得制御手段の基準電圧値として設定する基準電圧値設定手段と、から構成されている。
(もっと読む)
携帯端末
【課題】緊急事態が発生した場合にその状況を正確に記録し、確実に防犯対策を行うことができる携帯端末を提供する。
【解決手段】音声を集音する集音手段と、集音手段により集音された音声を拡大して外部に出力する拡声モードを起動させる拡声モード起動手段と、拡声モードが起動された場合、集音手段により集音された音声を拡大して出力する拡声出力手段と、集音手段により集音された音声に基づく音声データを記憶する拡声データ記憶手段とを備えた。
(もっと読む)
音声制御画像編集
デバイスは、被写体の画像を撮影し、被写体と関連付けられたオーディオを記録し、被写体が人物である場合に撮影された画像において人物の頭の場所を判定する。更にデバイスは、オーディオをテキストに変換し、テキストを含む会話の吹き出しを作成し、撮影された画像において会話の吹き出しを人物の頭の場所の隣に位置付けて最終画像を作成する。 (もっと読む)
撮像装置及びカメラ
【課題】本発明は、撮影者の発した言葉通りに被写体が反応したか否かを判定して正しい反応時に動作する撮像装置及びカメラを提供することである。
【解決手段】カメラ10は、予め所定のキーワード及び被写体の行動状態を記録部20に記録している。そして、後方音声取得部16で取得した音声が記録部20に記録されているキーワードに該当するか否かをパターン判定部18aで判定する。ここで、該当するキーワードであると判定された場合に、被写体の行動状態が記録部20に記録されている行動状態に従った行動をしたか否かを動き判定部13が判定し、上記キーワードに従った行動をしたと判定した場合には、撮像部12による撮影を開始するように信号処理及び制御部11が制御する。
(もっと読む)
音源の推定方法とその装置
【課題】現場において、測定データの任意の部分を抽出して音源位置の推定を行う方法とその装置を提供する。
【解決手段】複数のマイクロフォンM1〜M5とカメラ12とを一体化した音・映像採取ユニット10を用いて音の情報と映像の情報とを同時に採取し、音の情報である音声波形データと映像の情報である画像データとを記憶手段24に保存するとともに、音圧波形データのみを記憶手段24から抽出して表示手段25の表示画面25Mに音圧レベルの時系列波形のグラフを表示し、このグラフ上で音源方向の解析を行う時刻tzを指定した後、この指定された時刻tzを中心とした解析時間長Twの音圧波形データを用いて、複数のマイクロフォンM1〜M5で採取した音の音圧信号間の位相差を算出して音源の方向を推定するようにした。
(もっと読む)
音源の推定方法とその装置
【課題】突発的な音や間欠的な音が発生した場合でも、音源の推定を確実に行うことのできる方法とその装置を提供する。
【解決手段】複数のマイクロフォンとカメラとを一体化した音・映像採取ユニットを用いて音と映像とを同時に採取した後、音圧波形データと画像データとをバッファに一時保存しておき、時刻t0にて、制御ユニットから測定開始信号の指令が発せられたときには、時刻t0から所定の遡行時間長Tz分だけ遡った時刻t1=t0−Tzと時刻t2=t0+(Tw−Tz)との間にバッファに保存されたデータを取出して音ファイルと動画ファイルとを作成してメモリーに保存し、この保存された音ファイルの音圧波形データを用いて、複数のマイクロフォンで採取した音の音圧信号間の位相差を算出して音源方向を推定するようにした。
(もっと読む)
画像抽出装置及び撮像装置
【課題】 連続的に撮像された複数の画像から容易に所望の画像を抽出することができる技術を提供することを目的とする。
【解決手段】 連続的に撮像された複数の画像を読み込む入力部と、複数の画像の各々に対応付けられる撮像時の情報を取得する情報取得部と、所定の条件を満たす情報を撮像時の情報から抽出する情報抽出部と、情報抽出部の抽出結果に基づいて複数の画像から対応する画像を抽出する画像抽出部とを備える。
(もっと読む)
国籍判定装置、方法およびプログラム
【課題】個人の人種・形質のような生物学的特性、民族といった文化人類学的特性、発声した言語の属する母国語ないし方言といった言語学的特性その他の個人の外部的特徴を客観的に測定し、その測定結果に基づいて個人の国籍を自動的・総合的に判定し、それに応じたアクションを実行する。
【解決手段】国籍判定装置5は、画像解析装置2または音声解析装置4による個々の解析結果に対応する国籍情報を国籍情報DB6から抽出する。次に、国籍判定装置5は、国籍情報DB6から抽出された個々の国籍情報に基づいて人物の最終的な国籍を判定する。これは例えば、各解析結果に対応する個別の国籍情報に優先度を予め国籍情報DB6などの記憶媒体に定義しておき、最も高い優先度を有する個別の国籍情報を最終的な国籍とする。
(もっと読む)
撮像装置および話し手認識方法
【課題】 本発明は、動画撮影時に、話し手となる人物(被写体)の認識を高精度に行うことのできる撮像装置および話し手認識方法を提供することを目的とする。
【解決手段】 本発明の撮像装置(11〜32)は、画像解析手段(11)と、音声解析手段(11)と、話し手認識手段(11)を備え、画像解析手段は、連続的に取得される画像から人物の顔領域中の口唇領域を検出すると共に、その口唇領域のデータから口唇動作の特徴を抽出する。また、音声解析手段は、画像と同期して取得される音声データから音声の特徴を抽出する。そして、話し手認識手段は、画像解析手段により抽出された口唇動作の特徴と、音声解析手段により抽出された音声の特徴とに基づき、画像に写る複数の人物から話し手となる人物を認識する。
(もっと読む)
81 - 100 / 264
[ Back to top ]