
Fターム[5D015AA05]の内容
Fターム[5D015AA05]に分類される特許
1 - 20 / 90
音声情報解析装置および音声情報解析プログラム
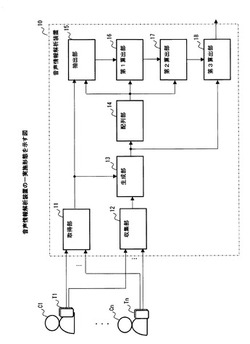
【課題】大まかな位置情報と音声情報とに基づいて、複数の人物がそれぞれ参加している会話グループを特定する可能な音声情報解析装置を提供する。
【解決手段】発話中の複数の人物を、位置情報に基づき、複数の会話グループに分ける組み合わせ候補を生成する生成部と、各組み合わせ候補の各会話グループにおける複数の発話音声を時系列に従って配列する配列部と、配列された発話音声に含まれる発話ペアごとに、韻律情報とパラ言語情報との少なくとも一方を含む特徴情報を抽出する抽出部と、発話ペアが会話の一部である場合に特徴情報が従う確率分布に基づいて、各発話ペアが会話の一部であることの尤もらしさを示す第1尤度を算出する第1算出部と、各発話ペアの第1尤度に基づいて、配列された全ての発話音声が会話を形成している確率を示す第2尤度を算出する第2算出部と、組み合わせ候補に含まれる各会話グループの第2尤度に基づいて、当該組み合わせ候補の尤もらしさを示す第3尤度を算出する第3算出部とを有する。
(もっと読む)
単語重要度算出装置とその方法とプログラム

【課題】対話における重要単語の出現特性を考慮した単語重要度算出装置とその方法とプログラムを提供する。
【解決手段】この発明の単語重要度算出装置は、形態素解析部と相槌単語同定部と単語重要度算出部とを具備する。形態素解析部は、発話者と受話者の会話に基づく対話テキストを入力として、当該対話テキストを形態素解析して単語毎に分割した発話者側単語列と受話者側単語列を出力する。相槌単語同定部は、形態素解析部が出力する受話者側単語列を入力として、当該受話者側単語列内の相槌単語を同定する。単語重要度算出部は、発話者側単語列と相槌単語を入力として、相槌単語より前所定時間内の単語を抽出し、当該抽出した単語の同一単語の数を集計した値をその同一単語の単語重要度とする。
(もっと読む)
音声制御システム及びプログラム
【課題】1つの自然文によって複数のコマンドを実行可能とした音声制御システムにおいて、従来よりも幅広い表現の自然文を受け入れることを可能とし、ユーザの利便性を向上する。
【解決手段】自然文から抽出される言葉と制御コマンドとを直接結びつけるコマンド変換辞書を記憶手段104に備えると共に、制御コマンドに直接結びつかない言葉を制御コマンド生成用のパラメータに変換するための変換補助情報を記憶手段106に記憶する。また、制御コマンドに直接結びつかない言葉については変換補助情報を参照して制御コマンド生成用のパラメータに変換し、制御コマンドを生成するコマンド変換手段103を備える。
(もっと読む)
対話支援装置、方法及びプログラム
【課題】話者が異なる言語で又は同じ言語で対話をする場合に、対話に応じて知識を補うための情報を提示して対話を支援することを可能にする。
【解決手段】実施形態によれば、入力部、音声認識部、対話履歴データベース、推定部、判定部、生成部、選択部、提示部を含む。入力部は、話者間の対話の音声を入力する。音声認識部は、入力音声を音声認識して、対応するテキスト情報に変換する。対話履歴データベースは、テキスト情報の全部又は一部を対話履歴として記憶する。推定部は、テキスト情報に基づいて、発話行為を推定する。判定部は、推定された発話行為に基づいて、補足情報を提示するかどうか判定する。生成部は、補足情報を提示すると判定された場合に、補足情報の候補を生成する。選択部は、対話履歴を利用して、補足情報の候補のうちから、提示すべきものを選択する。提示部は、選択された補足情報を提示する。
(もっと読む)
音声認識装置および音声認識プログラム
【課題】話題に応じて、高精度な音声認識結果を得る。
【解決手段】音声データに基づいて音響特徴量を算出する音響分析部50と、音響特徴量と発音ネットワークに対応する音響モデルとに基づき言語表現ごとの音響スコアを求め、また言語スコアを求め、音響スコアと言語スコアとに基づいて正解候補単語列を探索して認識結果テキスト情報を生成する正解単語探索部60と、話題情報から認識結果テキスト情報に対応する発話対応テキストを抽出する話題トラッキング部80と、話題情報から、発話対応テキストを含む発話相当付近テキストを抽出し、発話相当付近テキストに関連する関連テキスト情報をテキスト情報源2から取得し、言語モデルを関連テキスト情報に基づき適応化して更新する言語モデル適応化部90と、更新した際に適応化言語モデルに基づいて発音ネットワークおよび言語スコアメモリを更新する更新部62とを備える。
(もっと読む)
異常状態検出装置、電話機、異常状態検出方法、及びプログラム
【課題】話者の異常状態の検出を高い検出精度で行えるようにする。
【解決手段】第一算出部12は、話者の発話を表している発話データ2から、発話の特徴を表している特徴パラメータの統計量を算出する。擬似発話データ作成部13は、このうちの少なくとも1つの統計量が基準発話データ3のものと一致する擬似発話データ4を、発話データ2と基準発話データ3との特徴パラメータの統計量に基づき作成する。基準発話データ3は平常状態下の発話を表している。第二算出部14は、擬似発話データ4と発話データ2の特徴パラメータの統計量とに基づき、擬似発話データ4を発話データ2が入力された分だけ置き換えて得られる合成発話データ5の特徴パラメータの統計量を算出する。検出部15は、合成発話データ5と基準発話データ3とでの特徴パラメータの統計量の違いに基づいて、発話データ2が表している発話の話者の異常状態を検出する。
(もっと読む)
会話データ解析装置、方法、及びプログラム
【課題】話者間の影響度を適切に推定する。
【解決手段】単語分布推定部30で、t番目の単語wt及びその話者stからなる会話データを読み込み、各時点tにおける各話者の単語の使用頻度を示す単語分布を推定する。影響度推定部40の確率推定部43で、t番目の単語が話者mの影響に依る確率P(m|t)を計算し、影響度推定部44で、確率P(m|t)を用いて、話者nへの話者mの影響度λnmを推定する。尤度計算部45で、影響度λnmの会話データに対する尤もらしさを示す尤度を計算し、判定部46で尤度が収束したと判定されるまで、確率推定部43、影響度推定部44、及び尤度計算部45の処理を繰り返し、尤度が収束したときの影響度集合Λを出力する。
(もっと読む)
プレゼンテーションコーチシステム
【課題】プレゼンターがプレゼンテーションを実施している場合に、プレゼンターをリアルタイムで支援することが可能なプレゼンテーションコーチシステムを提供する。
【解決手段】プレゼンテーション資料を表示する表示手段と、プレゼンターの発声する音声を認識する音声認識手段と、音声認識手段からの認識結果に基づいて、プレゼンターが話した内容の論旨を取得する第1の構文解析手段と、プレゼンテーション資料に含まれる内容の論旨を取得する第2の構文解析手段と、第1の構文解析手段によって逐次取得されるプレゼンターが話した内容の論旨と、第2の構文解析手段によって取得されているプレゼンテーション資料の論旨の対応する部分とを逐次比較する論旨比較手段と、比較された論旨の間に相違が生じていると論旨比較手段が判断することに応答して、プレゼンターに通知を行なう通知手段とを含む。
(もっと読む)
音声認識方法とその装置とプログラム
【課題】認識誤り単語を除外して認識スコアを再計算する音声認識方法を提供する。
【解決手段】この発明の音声認識方法のNベスト候補スコア再計算過程は、過去発話単語の2単語ペアの関連度の平均値である過去発話関連度と、未来発話単語の2単語ペアの関連度の平均値である未来発話関連度とを求め、Nベストの全順位の現在発話単語と全ての過去発話単語の単語ペアの過去・現在関連度と、Nベストの全順位の上記現在発話単語と全ての上記未来発話単語の単語ペアの現在・未来関連度とを求め、上記過去発話関連度と閾値を比較すると共に上記未来発話関連度と閾値とを比較することで上記過去発話単語集合内の関連性と上記未来発話単語集合内の関連性を評価し、関連性がある場合は上記過去・現在関連度と上記現在・未来関連度の値を考慮した認識スコアを再計算する。
(もっと読む)
裏声検出装置および歌唱評価装置
【課題】歌唱者による歌唱の音声から裏声を検出する際に検出漏れを少なくする。
【解決手段】制御部10は、ユーザ歌唱音声データから倍音比率、音高及び経過時間を情報として含む音声情報データを生成すると(ステップS110)、これを音声分布表に割り当てる(ステップS112)。制御部10は、音声情報データに対してフィルタを用いた処理を施し、算出値を算出していく(ステップS114)。制御部10は、算出した算出値が予め定められた閾値を超えると(ステップS116;Yes)、フィルタの位置を、算出値が閾値を超えた時点の位置で決定する(ステップS120)。制御部10は、フィルタにおけるプラスの重み付けがなされた領域に含まれる音声情報データを、裏声に基づく音声情報データであると検出する(ステップS122)。
(もっと読む)
情報処理装置、情報処理方法、情報処理システム、およびプログラム
【課題】言語では明示的に認識されない情報を反映する語句を分析するための情報処理装置、情報処理方法、情報処理システム、およびプログラムを提供する。
【解決手段】情報処理装置120は、会話を記録した音声データから当該音声データにおける言語では明示されない情報を識別しており、音声データを音響データを使用して音響分析するための音響分析部208と、音声データの前後がポーズで分離された領域を識別し、識別された領域の音響分析により前記識別された領域の語句を識別し、当該語句の韻律特徴値を要素とする当該語句の1以上の韻律特徴値を生成する韻律情報取得部212と、音響分析部208が取得した語句の音声データにおける出現頻度を取得する出現頻度取得部210と、出現頻度の高い語句の韻律特徴値の前記音声データ中におけるばらつき度を計算し、特徴語句を決定する韻律ばらつき解析部214とを含む。
(もっと読む)
デジタルカメラおよびカメラ付き電子機器
【課題】写っている人物の体調/気分をわかりやすく撮影すること。
【解決手段】デジタルカメラは、被写体を撮像して画像データを生成する撮像手段13と、被写体画像データに基づいて人物の顔の表情を検出する表情検出手段17と、撮影開始前に撮像手段13で生成された画像データを用いて表情検出手段17が検出した表情に基づいて人物の体調/気分を判定する体調/気分判定手段17と、体調/気分判定手段17による判定結果に基づいて所定の撮影開始条件を選択する撮影開始条件選択手段17と、選択された撮影開始条件を満たす場合に撮影を開始させる撮影制御手段17と、を備える。
(もっと読む)
行動履歴検索装置
【課題】ユーザからの問い合わせに対して、行動履歴情報を検索して、ユーザにとって有意な回答を出力可能な行動履歴検索装置を提供する。
【解決手段】行動履歴検索装置は、ユーザからの問い合わせを受け付け、当該問い合わせを受け付けた時刻と、問い合わせの対象とを出力し、問い合わせの対象を用いて、ユーザの行動の履歴を時刻と共に示す行動履歴情報を検索する範囲を決定し、この範囲内の行動履歴情報によって示される時刻から、出力された時刻までの経過時間を算出し、経過時間と、行動履歴情報によって示される行動の履歴から求められる問い合わせの回答の候補に対してユーザの所望の回答である可能性を経過時間に応じて判定するための絞込みモデルとを用いて、範囲内の行動履歴情報によって示される行動の履歴から、問い合わせの回答の候補毎に可能性を判定し、この可能性に応じて、回答の候補を出力する。
(もっと読む)
音声言語識別装置の学習装置、音声言語の識別装置、及びそれらのためのプログラム
【課題】発話データから、その発話の言語を信頼性高く識別できる音声言語の識別装置を提供する。
【解決手段】学習装置は、言語ラベル付の音声データの記憶装置、これら音声データについて、所定時間長かつ所定シフト長の音声特徴の系列を抽出するブロック特徴生成部180、抽出された音声特徴の系列からコードブックを生成するコードブック算出部184、複数の音声データの各々について、当該音声データから得られた音声特徴の系列に含まれる音声特徴と最も近い代表ベクトルをコードブックから求め、その分布に基づいて当該音声データの言語ラベル付音声言語特徴を生成する言語音素特徴ベクトル算出部186、及びこの音声言語特徴を学習データとして、音声言語特徴から言語を推定するためのSVMを生成するSVM学習部190を含む。
(もっと読む)
回線毎感情検出機能を有する電話制御装置
【課題】
音声データに、笑い,怒り,哀愁,楽しみなどにみられる感情の検出と、音声データの中に繰り返し音声が有るときに、感情検出機能に入力する音声データ量を削減して利用効率を上げる技術を提供する。
【解決手段】
感情検出は、音声データを蓄積する音声蓄積転送部2111と、繰り返し音声を検出する音声繰り返し処理部2112と、繰り返した音声は音声データは音声選択部2113から音声データを音声数値化処理部2114に送り,繰り返さない音声は、音声選択部2113から音声データの転送を停止させて感情を求める。
(もっと読む)
用件区間抽出方法、装置、及びそのプログラム
【課題】コンタクトセンタにおけるオペレータと顧客との対話から用件区間を正確に抽出することを可能とする。
【解決手段】学習用通話データに含まれる複数の発話から、発話の出現頻度と出現位置に基づき、用件区間の終了時に典型的に現れる発話(典型フレーズ)を抽出し、更に典型フレーズ内に偏って出現する単語を抽出する。そして、用件区間抽出対象の通話データを構成する各発話に前記抽出した単語が含まれる個数に基づき、どの発話が用件区間の終了発話であるかを特定し、オペレータの第一発話の次の顧客発話を用件区間の開始発話とすることにより用件区間を抽出する。
(もっと読む)
情報処理装置、および情報処理方法、並びにプログラム
【課題】ユーザ発話に基づいてユーザの意図を判定する装置および方法を実現する。
【解決手段】予め登録された複数の意図情報の各々に対応する意図モデル単位で、観測情報として得られるコンテキスト情報に基づく事前スコアを算出する事前スコア調整部、ユーザ発話に基づく入力音声に最も適合する単語系列の決定とその単語系列に付与される音響スコアと言語スコアを前記意図モデル単位で算出するマルチマッチング部、意図モデル単位の事前スコアと音響スコアと言語スコアから算出される総合スコアを比較して、最も高い総合スコアが得られた意図モデルに対応する意図情報をユーザ発話に対応する意図として決定する意図判定部を有し、意図モデル単位のスコア比較によりユーザの発話に対応するユーザの意図を判定する。
(もっと読む)
会話の話題を決定して関連するコンテンツを取得して提示する方法及びシステム
【課題】会話の話題を決定して関連するコンテンツを取得して提示する方法及びシステムを提供することを目的とする。
【解決手段】会話の話題を決定して、関連するコンテンツを取得して提示する方法及びシステムが開示される。開示されたシステムは、継続中の会話における“創造的なインスピレータ”を提供する。システムは会話からキーワードを抽出し、議論されている話題を決定するためにキーワードを使用する。開示されたシステムは、インテリジェントなネットワーク環境で検索を行い、会話の話題に基づいてコンテンツを取得する。コンテンツは、会話の参加者に提示され、その議論を補うことができる。オーディオトラックと新聞記事とジャーナル紙との写しを含むテキストドキュメントの話題を決定する方法もまた開示される。
(もっと読む)
情報集計システム、情報集計装置および情報集計方法
【課題】評価や感想の集計を容易に行う。
【解決手段】情報集計装置100が、通信端末200,300からコンテンツを指定してアクセスされた場合、当該コンテンツに対応する所定のメッセージを通信端末200,300へ送信し、当該メッセージに対して通信端末200,300から送信されてきた音声信号に含まれる言語を認識してその言語から単語を抽出し、音声信号に含まれる言語の状態に基づいて、その音声信号を送信した利用者の感情を推測し、コンテンツ情報と、抽出された単語と、推測された感情を示す感情情報とを対応付けて、集計情報として記憶する。
(もっと読む)
トークスクリプト利用状況算出システムおよびトークスクリプト利用状況算出プログラム
【課題】談話データの構造を解析した結果に基づいて、各業務におけるトークスクリプトの利用状況を算出するトークスクリプト利用状況算出システムを提供する。
【解決手段】談話データ101および談話セマンティクス200を入力とし、トークスクリプトの利用状況300を出力するトークスクリプト利用状況算出システム1であって、談話セマンティクス200は簡約情報61を含み、簡約された談話データ101におけるブロックと各トークスクリプトとの間の類似度を算出し、最も類似するトークスクリプトを類似度情報71として出力する類似度算出部70と、トークスクリプト毎に、簡約された談話データ101における各ブロックのうち、最も類似するものが当該トークスクリプトでありかつ類似度が所定の閾値より高いブロックの数を算出し、対象の応対業務が行われた数に対する利用頻度を算出して利用状況300として出力する利用状況算出部80とを有する。
(もっと読む)
1 - 20 / 90
[ Back to top ]