
Fターム[5D015KK01]の内容
Fターム[5D015KK01]に分類される特許
141 - 160 / 465
動画検索方法および動画検索システム
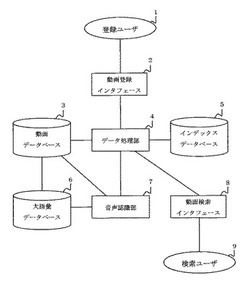
【課題】 インターネットなどの動画サイト上に登録された大量の動画に対するキーワード検索について、時間の経過等による検索キーワードの陳腐化を防ぎ、時代に即したキーワードを用いて動画を検索することを可能にする。
【解決手段】 インターネットなどの動画サイト上に登録された大量の動画の検索について、読み仮名を入力する動画登録インタフェースと、該読み仮名から生成された音素列を基に動画データベース上の動画ファイルについて音声認識を行う音声認識部と、音声認識結果から得られた新たな語彙を追加するインデックスデータベースと各データベースへSQL文を発行することなどによりシステム全体を制御するデータ処理部とを有する構成である。
(もっと読む)
音声出力制御装置および車両用ナビゲーション装置

【課題】電話機の事前の接続や無線端末登録が不要であって、電話機の着信時に車室内の音声出力装置から出力される音声を自動的に消音または音量低減する。
【解決手段】マイク10a〜10dにより入力した車室内の音声波形から、ナビゲーション装置1の音声制御回路9およびオーディオ装置15が出力する音声波形を減算することにより、背景音を除いた差分音声の音声データを生成する。予め外部メモリ6に登録されている電話機の着信音の音声波形データと差分音声の音声波形データを比較し、一致する場合にはナビゲーション装置1およびオーディオ装置15を消音状態とする。
(もっと読む)
音声認識ロボットおよび音声認識ロボットの制御方法
【課題】発話者から発生する音声を認識する音声認識性能の向上する音声認識ロボット、および音声認識ロボットの制御方法を提供すること。
【解決手段】音声認識ロボットにおいて、音声の発生した方向を特定する音源特定部と、音声取得部と、音声の内容を認識する音声認識部と、取得した音声の音圧を測定する測定部と、取得した音声の発生した方向について撮像する撮像部と、撮像した画像内に存在する人物の顔を検出する顔検出部と、検出した顔の中から、口唇を抽出する抽出部と、抽出した口唇の中心点を特定する特定部と、音声取得部を保持し、伸縮動作または関節角度の変化の少なくともいずれかの駆動動作により姿勢変更可能な保持部と、を備えさせることで、発話者の口唇の中心点と、前記音声取得部との相対的な位置を、測定した音声の音圧と基づいて修正するように前記保持部の姿勢を変更するようにした。
(もっと読む)
モータ雑音下におけるロボット用音声認識方法
【課題】モータ雑音下におけるロボット用音声認識の性能向上を図る。
【解決手段】所定の動作またはジェスチャを行いつつ人の音声を認識するロボットであって、前記動作またはジェスチャを行わせる駆動ユニットと、実行されている前記動作またはジェスチャを判別する判別ユニットと、マルチコンディション学習を含む少なくとも2つの認識アルゴリズムを備えた音声認識ユニットと、判別された前記動作またはジェスチャに応じて前記認識アルゴリズムの1つを選択する切り替えユニットと、を備えたロボット。
(もっと読む)
音声認識遊技装置及び記録媒体
【課題】遊技者が命令として入力した音声が音声認識処理によってどのように認識されているかを確認しながら、命令を選択することができる音声認識遊技装置を提供する。
【解決手段】キャラクタを表示する表示部と、キャラクタに対する命令等を音声により入力する音声入力部と、音声入力部から入力された音声を認識する音声認識処理部と、予め登録されているキャラクタの動作に対応する命令が音声認識処理部で認識されると、表示部にその動作を表示させる内部処理部とを備えた音声認識遊技装置であって、表示部は、音声入力すべき命令等を選択肢として複数表示し、内部処理部は、音声入力部に音声入力があると、複数表示された音声入力すべき命令等の選択肢の中から音声入力と一致した選択肢のみを表示部に表示し、一致しない選択肢を表示から消去し、選択肢のうち音声入力されたと認識した選択肢に基づきキャラクタの動作を表示させる。
(もっと読む)
情報処理装置及び方法並びにプログラム
【課題】 ユーザの発声方法に対して適切なタイミングで適切な内容のアドバイスを行い、発声方法に起因する誤認識の確率を低減させる。
【解決手段】 音声認識部102は入力音声に対して音声認識を行う。実行部103は音声認識の結果に応じた処理を実行する。分析部104は入力音声の音声認識に対する適性を分析する。取り消し指示部106は実行部103によって実行された処理の取り消し指示を入力する。通知部109は、取り消し指示の入力に応じて、分析部104による分析結果に基づいて、音声入力に関するガイダンスをユーザに通知する。
(もっと読む)
音声対話装置及び音声理解結果生成方法
【課題】過去に否定されていても、正しい認識結果であれば、理解結果として選択されにくくなることなく、同一の誤認識が繰り返されることを回避することができる音声対話装置を提供する。
【解決手段】音声対話装置100は、音声認識処理部111による認識結果である複数の認識結果候補から、各認識結果候補に与えられた所定の選択基準値に基づき選択された認識結果候補を用いて、発話された音声に対する応答となる理解結果を生成する理解結果生成部113を備える。理解結果生成部113は、過去に訂正を指示された理解結果に対応する認識結果候補に与えられた所定の選択基準値を、過去に訂正を指示された理解結果と同一の発話を再度入力した場合の認識結果候補には影響を与えない程度に、過去に訂正を指示された理解結果が選択されにくくなる方向に修正する。
(もっと読む)
車両用音声対応制御装置
【課題】車両内の乗員の会話に合わせてより体感的に訴えるサービスを提供可能な車両用音声対応制御装置を提供すること。
【解決手段】車室内で発声された音声を認識する音声認識手段(20、12)と、複数の音声キーワードが記憶された音声キーワード記憶手段(11)と、音声認識手段により認識された音声と音声キーワード記憶手段に記憶された音声キーワードとを照合する照合手段(12)と、照合手段の照合結果に基づき音声認識手段により認識された音声が指示入力であるか否かを判定し、音声認識手段により認識された音声が指示入力でないと判定した場合に、照合手段の照合結果に基づき車載アクチュエータを作動させる制御手段(13)と、を備える車両用音声対応制御装置(1)。
(もっと読む)
ディジタルテレビジョン受信機
【課題】多数の番組情報が記載された検索画面上から所望の番組を検索するために、音声認識を用いて番組情報の絞込みを行うことができ、ユーザの検索操作の負担を軽減することができる。
【解決手段】マイク18を介して音声情報を入力するとともに、入力した音声情報に基づいてROM13cに記録された音声認識プログラム100にて音声認識を行う。このとき、音声認識プログラム100は、取得した音声情報に基づいて、所定の番組情報を基に検索画面に表示された番組情報の表示/非表示を選択する。
(もっと読む)
HDD内蔵型ディジタルテレビジョン
【課題】記録媒体に記録する際に、操作性を容易にすることが可能なHDD内蔵型ディジタルテレビジョンの提供を目的とする。
【解決手段】マイク18により音声情報を取得するとともに、取得した音声情報により音声プログラム100を実行して映像データを録画する際の録画設定を自動で行う。このとき、音声プログラム100は、取得した音声情報に対応して、コマンドテーブル100bに記録された音声情報とコマンド情報の比較を行いながら、映像データをHDD15aに録画する際の画質と音質の設定を変更する
(もっと読む)
照明装置の効果を検出する方法及びシステム
本発明の方法は、制御システムから効果装置に動作信号を送信するステップと、動作信号に従って効果装置を動作させるステップと、効果装置の効果を検出するステップと、前記効果に対して場所を割り当てるステップと、前記効果の場所を記憶するステップと、を有する。効果装置は照明装置を有することが可能であり、その方法は複数の効果装置を有することが可能である。  (もっと読む)
(もっと読む)
通信装置及び通信方法
【課題】通話中の通話者の状況の変化に応じて背景音を変更可能で、常時、通話者の状況に即した背景音を再生可能な通信装置等を提供する。
【解決手段】通信網3を介して通話音声とともに背景音を送受信し、背景音を再生した状態で通話可能な通信装置等であって、通話者の音声を集音して通話音声を生成するマイク入力部4と、マイク入力部4で生成された通話音声に基づき、通話時の通話者の音声の変化を検出する音声変化検出部6と、音声変化検出部6の検出結果に基づいて背景音を変更する制御部20と、変更された背景音を通話音声とともに通信網3に送信する無線部18とを備える。音声変化検出部6は、平常時の通話者の音声を保持する保持手段と、平常時の通話者の音声と通話時の通話者の音声との差分を算出し、変化ポイントP1を生成する算出手段とを備え、変化ポイントP1に基づいて通話者の音声の変化を検出する。
(もっと読む)
AV機器に対する音声操作システム
【課題】複雑な操作が必要になるAV機器において、音声認識とOSD表示を用いることにより、操作の簡易化を目指す。
【解決手段】リモコンから送信された音声信号を、雑音抑圧及び音声認識特徴量へ変換し、各AV機器の操作項目で構成されている単語辞書から成る音響モデル及び言語モデルを用いてマッチングを行い、尤度もしくは単語信頼度の上位N個を上位順にOSDに表示する。ユーザはその操作候補から選択することで、各AV機器が依頼された動作を行う。
(もっと読む)
録画予約システム、録画装置
【課題】録画予約したい番組の番組名をユーザが思い出せない場合でも、その番組名を調べてユーザに報知し、録画機能の利用率を向上させた録画予約システム、及びこの録画予約システムで適用される録画装置を提供する。
【解決手段】ユーザは、録画予約したい番組で使用されている歌唱を、録画装置3のマイク37に向かって歌う。録画装置3の制御部30は、歌唱に関する歌唱データを、ネットワーク5を介してDBサーバ2に送信する。録画装置3から送信されてきた歌唱データを受信すると、DBサーバ2側の制御部21は、歌唱データが含まれる音楽データに対応する番組名を、ハードディスク22のテーブルから抽出する。問い合わせに対する結果がサーバ2から返信され、番組名が返信された場合、制御部30は、その番組名を表示部35に表示する。
(もっと読む)
音声対話装置
【課題】従来、大語彙検索用音声対話インタフェースは、検索精度の向上ためジャンルにより検索対象を絞るが、検索失敗時に対象外ジャンルの発声か、装置の誤認識かが不明、複数回操作で絞込む場合、絞込み用のジャンル名等検索対象分類数が多いと選択が困難であり、また言い方が多い場合に対応が困難であった。
【解決手段】入力音声を音声認識手段で音声認識し、音声認識結果によりジャンル推定辞書参照し、ジャンル推定手段で対応ジャンルを推定し、検索手段が音声認識結果と属性条件に基づき、検索データベースから検索候補を取得し、検索の候補とジャンル推定結果をユーザが選択可能な動作とともに提示手段が示し、上記検索手段は、検索の候補が目的外のときユーザが選択したジャンル属性に応じて検索対象の属性条件を変更して検索データベースから候補を再度検索する。
(もっと読む)
音声処理装置およびその制御方法
【課題】音声ショートカットの利便性を維持しつつ、音声ショートカットに対する音声認識率を向上可能とする技術を提供する。
【解決手段】複数の状態を有し、各状態へショートカットするためのショートカットデータを設定する音声処理装置であって、ユーザによる操作入力部への操作入力により前記複数の状態のうちのある状態に遷移した際に、該状態へ遷移するためのショートカットデータと音声認識対象語彙との対応付けを設定する設定手段と、音声を入力する音声入力手段と、前記音声入力手段で入力された音声を、前記音声認識対象語彙を用いて認識する音声認識手段と、前記音声認識手段の認識結果である音声認識語彙に対応するショートカットデータを用いて状態を遷移させる制御手段とを備える。
(もっと読む)
対話装置、対話方法及びコンピュータプログラム
【課題】 ユーザとの対話中に、その対話進行に沿った利用不可通知をユーザに提示することによりアプリが利用不可となったことを効果的にユーザに通知することができる対話装置、対話方法及びコンピュータプログラムを提供する。
【解決手段】 対話対象となる話題の目的をユーザとの対話進行により達成するとともに、ユーザとの対話中に対話進行内容に応じて参照する項目を収集する対話進行部101、ユーザとの対話で前記対話進行手段が参照する話題を正規項目と利用不可項目に分けて管理する話題管理部103、話題の変更を話題管理部103の前記正規項目及び利用不可項目の管理に反映させる話題更新部104及び対話進行部101による項目の収集結果により話題管理部103を参照し、前記収集結果に利用不可の項目が含まれている場合利用不可通知の出力を判定する利用不可通知出力判定部102を具備。
(もっと読む)
音源選択装置
【課題】 従来よりも複数の仮想音源の選択動作の自由度を高めることができる音源選択装置を提供することにある。
【解決手段】 頭部動作判定手段33が、配置パターンの変更動作が行われたことを判定すると、配置パターン選択手段43は、複数の仮想音源の定位音源配置パターンを、定位音源配置パターン記憶手段41に記憶されている別のパターンに変更する。頭部動作判定手段33が、音源を選択する受聴者の頭部の動作を判別すると、受聴者の正面にある音源を選択し、ミシング手段5は選択された音源の再生を継続する。
(もっと読む)
音声駆動式のコントロールアプリケーションにおいて危険を軽減するためのシステムおよび方法
【課題】音声駆動式のコントロールアプリケーションにおいて危険を軽減するためのシステムおよび方法を提供する。
【解決手段】オーディオ入力を受信するためのレシーバと、オーディオ入力を分析してオーディオ入力の少なくとも1つのイベントを識別するためのイベント検知器と、オーディオ入力の少なくとも一部を解釈するための認識器と、複数のルールを含むデータベースと、少なくとも1つのイベントおよび少なくとも1つのルールに基づいてコントロールコマンドを作成するためのコントローラとを含む音声認識およびコントロールシステム。
(もっと読む)
音声認識装置、音声認識方法及び音声認識プログラム
【課題】使用者の発話が曖昧な場合にも、使用者の発話を精度良く認識することができる音声認識装置、音声認識方法及び音声認識プログラムを提供する。
【解決手段】音声認識装置1は、入力された音声についての認識結果に基づいて操作対象の操作内容を決定するため、音声についての認識結果を、予め定めた操作対象及び操作内容の種類に分類することにより、操作対象及び操作内容を特定する特定処理を行う操作特定手段31と、音声についての認識結果から、操作特定手段31で分類し得ない曖昧語を検出する曖昧語検出手段32と、ここで検出された曖昧語により特定される可能性のある操作対象を操作対象候補として抽出する候補抽出手段33とを備える。操作特定手段31は、操作内容の特定は可能で操作対象の特定ができない場合、曖昧語検出手段32で検出された曖昧語を候補抽出手段33で抽出された候補に置換して、当該操作特定手段31で上記特定処理を行う。
(もっと読む)
141 - 160 / 465
[ Back to top ]