
Fターム[5D015LL11]の内容
Fターム[5D015LL11]の下位に属するFターム
Fターム[5D015LL11]に分類される特許
1 - 20 / 196
対話装置、対話方法及び対話プログラム
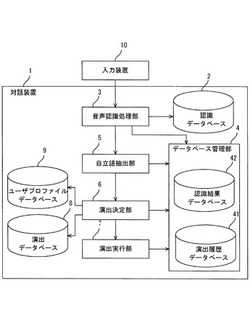
【課題】ユーザとより自然な対話を行うこと。
【解決手段】対話装置は、ユーザの音声を認識する音声認識手段を備え、音声認識手段により認識された音声情報に基づいて、ユーザと対話を行う。また、対話装置は、音声認識手段により認識された音声情報に基づいて、自立語を抽出する自立語抽出手段と、自立語に対応付けられた演出内容を複数記憶する第1記憶手段と、第1記憶手段に記憶された複数の演出内容の中から、自立語抽出手段により抽出された自立語に基づいて、実行する演出内容を決定する演出決定手段と、ユーザとの対話中に、演出決定手段により決定された演出内容を実行する演出実行手段と、を備える。
(もっと読む)
映像付加情報関係性学習装置、方法、及びプログラム

【課題】映像に含まれる画像情報と音響情報との双方を利用し、かつその相互の共起関係を考慮して、それら情報と言語情報との関係性の学習をより高精度に行うことができるようにする。
【解決手段】蓄積画像特徴抽出部5によって、完全蓄積映像及び不完全蓄積映像の各々から、完全蓄積画像特徴及び不完全蓄積画像特徴を抽出する。蓄積音響特徴抽出部6によって、完全蓄積映像及び不完全蓄積映像の各々から、完全蓄積音響特徴及び不完全蓄積音響特徴を抽出する。蓄積付加情報特徴抽出部4によって、蓄積付加情報の各々から蓄積付加情報特徴を抽出する。蓄積潜在変数抽出部8によって、映像と付加情報の関係性を記述するための変数の集合である蓄積潜在変数集合を抽出する。映像・付加情報間関係性学習部9によって、映像と付加情報との関係性を記述するモデルである映像・付加情報関係モデルを学習する。
(もっと読む)
音声認識装置、音声認識方法、及び音声認識プログラム
【課題】音声認識コマンドの操作性を向上させることができる、音声認識装置、音声認識方法、及び音声認識プログラムを提供すること。
【解決手段】ナビゲーション装置1は、ユーザの発話音声を検出する音声検出部2bと、音声検出部2bにて検出されたユーザの発話音声に基づいて、当該ユーザの発話音声に含まれる音声認識コマンドを特定する音声認識コマンド特定部2cと、音声認識コマンド特定部2cにより特定された音声認識コマンドに対応する所定の制御を実行すると共に、音声認識コマンドを選択してディスプレイ6に表示する音声認識制御部2aとを備える。音声認識制御部2aは、ユーザが使用する可能性が高いか否かを判断する所定の条件に基づいて選択した音声認識コマンドを、ディスプレイ6に表示させる。
(もっと読む)
発音複雑度算出装置、音声認識装置、発音複雑度算出方法、音声認識方法、及びプログラム
【課題】高い精度で発音の難しさを評価する。
【解決手段】発音複雑度推定装置100は、発音特徴抽出部110及び複雑度算出部120を有している。発音特徴抽出部110は、発音の仕方を示す記号を複数並べた記号列データから、2つ以上の前記記号の組み合わせである発音特徴データを抽出する。複雑度算出部120は、発音特徴データを用いて、記号列データに従った発音の複雑度を算出する。発音特徴抽出部110に入力される記号列データは、たとえば、言語の音声を表記する音声記号の列である。
(もっと読む)
ソーシャルネットワーキングサービスシステム、ソーシャルネットワーキングサービスサーバ及びソーシャルネットワーキングサービスプログラム
【課題】音声参加型のソーシャルネットワーキングサービスシステム等を提供する。
【解決手段】SNSシステムは、SNSを提供するサーバと通話装置とが接続されたSNSシステムであって、サーバは、通話装置から音声を入力する音声入力手段と、音声を解析することにより、少なくとも音声を入力したユーザを識別するユーザ識別情報と音声により入力された命令語と音声により入力され該音声が分類されるべきSNSサービス分類を示す分類語とを抽出する音声解析手段と、命令語が音声の登録命令を示す場合、該入力された音声と、ユーザ識別情報に基づくユーザ識別子と、分類語とを対応付けて記憶手段に登録する音声登録手段と、命令語が音声の検索命令を示す場合、分類語を検索キーとして分類語に対応付けられた音声を記憶手段から検索する音声検索手段と、通話装置に対し音声検索手段により検索された音声を出力する音声出力手段とを有する。
(もっと読む)
情報処理装置、ダイジェスト生成方法、及びダイジェスト生成プログラム
【課題】より適切なダイジェストを生成する。
【解決手段】情報処理装置において、所定時間撮影された1又は複数の被写体を含む映像情報及び音声情報を蓄積する蓄積部と、前記蓄積部に蓄積された映像情報及び音声情報を用いて、予め設定された1又は複数の要素に基づき、前記所定時間の時系列における所定の単位時間毎の変化量を評価し、評価された結果に基づいて1又は複数のダイジェスト候補を抽出するダイジェスト生成部と、を有し、前記ダイジェスト生成部は、前記ダイジェスト候補に対応する映像情報及び音声情報に含まれる被写体の状況又は特徴をパターン認識し、認識された結果に基づいて前記ダイジェスト候補からダイジェストを生成するパターン認識部を有する。
(もっと読む)
通信端末及び通信方法
【課題】通話中に言語選択を行う際、言語の選択操作の開始時に通話状態を保留状態に迅速に移行し、通話相手との通話に対応する翻訳先の言語にて通話を再開する旨を明確に伝え、円滑なコミュニケーションを促進する。
【解決手段】他の携帯通信端末30,40と通話する携帯通信端末1であって、他の携帯通信端末30,40との通話時に、入力された音声データを他の携帯通信端末30,40との通話に対応する翻訳先の言語の選択操作の入力を受け付ける入力部11と、翻訳先の言語の選択操作の入力の開始時に、他の携帯通信端末30,40との通話の通話状態を保留状態に移行する制御部10とを備える。
(もっと読む)
会議品質評価装置及び会議品質評価方法
【課題】発言する出席者に対する評価ばかりでなく、会議に参加する他の出席者の態度をも含めて評価することで、会議全体の評価を可能とし、他の出席者の態度を評価数を少なくして簡便にしながら、評価精度を高くして、出席者が評価されていることを意識せずに、時々刻々に会議の品質を評価でき、以って出席者の適正化提案を可能とする。
【解決手段】品質評価手段が、回転方向姿勢から、発言者以外の出席者の回転方向姿勢をうつ伏せ、仰向け及び直立不動の3状態のいずれにあることの姿勢状態決定を行い、発言状態検出手段で検出された発言状態から、予め定められた発言評価テーブルを参照して会議の品質評価の1項目とする発言評価結果を形成し、決定された姿勢状態から、予め定められた姿勢評価テーブルを参照して会議の品質評価の他項目とする姿勢評価結果を形成し、発言品質評価値及び姿勢評価値に基づいて品質評価時の会議の品質評価を演算する。
(もっと読む)
サービス提供装置及びサービス提供方法
【課題】異なる端末間のコンテンツ連携を実現し、特に希望するコンテンツを迅速に表示する。
【解決手段】本発明によるサービス提供装置1は、第1サービス提供部10と、第2サービス提供部20とを備え、第1サービス提供部10は、音声認識機能部12を備え、第1利用者端末100より第2コンテンツの変更要求を受信した場合、音声認識機能部12が第1利用者端末100からの音声から取得した文字情報に基づき、コンテンツ配信表32より変更後の第2コンテンツを選択し、第2サービス提供部20は、第1サービス提供部10が選択した変更後の第2コンテンツを第2利用者端末200に提供する。
(もっと読む)
テキスト及び音声特徴量収集方法、そのシステム、プログラム
【課題】大幅に送信データ量を増やすことなくサーバ端末から音声認識用の音声特徴量と元の音声の発言内容を書き起こすための情報とを送信することができ、かつ、サーバ端末で元の音声の発言内容を示すテキストと音声認識用の音声特徴量を収集することができる技術を提供する。
【解決手段】クライアント端末の音声圧縮部が、入力音声信号を低ビットレートコーデックにより圧縮し圧縮音声信号を生成し、音声特徴量変換部が、入力音声信号を音声特徴量に変換し、送信データ結合部が、圧縮音声信号と音声特徴量とを結合し送信データを生成する。サーバ端末の送信データ分割部が、受信した送信データを圧縮音声信号と音声特徴量とに分割し、音声認識部が、音声特徴量を用いて音声認識を行い、認識結果を求め、音声復元部が、低ビットレートコーデックにより圧縮音声信号を低品質の音声に復元する。
(もっと読む)
対話評価装置、方法及びプログラム
【課題】従来よりも性能の高い評価関数を導出する対話評価技術を提供する。
【解決手段】対話データ記憶部1には、複数のユーザのそれぞれについての各対話の対話データが記憶されている。統計量抽出部2は、対話データから各複数のユーザの対話の所定の発言の数の平均値及び対話の長さの平均値を計算し、また、対話データから評価関数の説明変数となる統計量を抽出する。クラスタリング部3は、計算された対話の所定の発言の数の平均値及び対話の長さの平均値に基づいて複数のユーザをクラスタリングする。評価関数導出部4は、各クラスタに対応する評価関数を、その各クラスタに含まれるユーザについての統計量を説明変数としユーザ評定値を応答変数とする重回帰分析により導出する。
(もっと読む)
自動音声応答装置、音声応答処理システム及び自動音声応答方法
【課題】自動的な応答処理をより確実に機能させる。
【解決手段】実施の形態の自動音声応答装置は、音声認識部、応答処理実行部及び管理情報更新部を備える。音声認識部は、入力された音声を音声認識して文字データを取り出す。応答処理実行部は、応答処理の内容と文字データとを予め関連付けて登録した管理情報に基づいて、音声認識の結果に対応した応答処理を実行する。管理情報更新部は、音声認識により得られた文字データが管理情報中に未登録であった場合、管理情報中に登録済みの応答処理の内容のいずれかを未登録の文字データと新たに関連付ける。
(もっと読む)
音声認識装置及び音声認識処理方法
【課題】 音声認識処理を行う場合に、優先度に応じて音声認識処理を行うことができる音声認識装置及び音声認識処理方法を提供することを目的とする。
【解決手段】 音声認識装置300は、音声データを外部から取得し、取得した音声データを一次出力データベース303へ記録し、一次出力データベース303に記録される音声データを、処理すべき優先度に応じた条件を記憶する優先度メモリ305に記憶される条件と比較し、条件に一致した音声データをその条件の優先度に応じて音声認識処理を行わせる。音声認識処理された音声認識結果は、音声認識結果データベース300Dへ格納される。
(もっと読む)
対話システム、対話制御方法およびプログラム
【課題】対話システムで、コミュニケーションギャップをリアルタイムに解決し、持続的かつ自然なコミュニケーションを行う。
【解決手段】インタラクション状態量算出部12は、ユーザPの発話における話者交替潜時、発話区間のピッチ、パワーまたはモーラを含むインタラクション状態量を検出する。コミュニケーション同調制御部13は、ユーザPとロボットシステム10とのコミュニケーション同調ずれ量を算出し、同調モデルを表す状態方程式による連続的な引き込み制御によりコミュニケーション同調ずれ量を最小化すると同時に、インタラクションルールによる離散的な引き込み制御により、ユーザPのインタラクション状態量をロボットシステム10のそれに近づけていく、または、ロボットシステム10のインタラクション状態量をユーザPのインタラクション状態量に近づけつつユーザPのインタラクション状態量をロボットシステム10のそれに近づけていく。
(もっと読む)
韻律変換装置およびプログラム
【課題】韻律に関する適切なパラメータを用いた制御を行うことによって、入力される音声の韻律を変換し、聞き取り易い音声を出力する。
【解決手段】韻律変換装置は、音声の韻律データを記憶する韻律データ記憶部と、前記韻律データに関する基準値をパラメータとして記憶するパラメータ記憶部と、韻律変換処理のための係数を設定値として記憶する設定部と、入力音声を分析し前記入力音声の韻律データを前記韻律データ記憶部に書き込むとともに、前記韻律データに関する基準値を求めて前記パラメータ記憶部に書き込む音声分析部と、前記設定部から読み出した前記設定値を用いて前記パラメータ記憶部に記憶された前記基準値からの韻律の変位量を変化させることによって前記韻律データ記憶部に記憶された前記韻律データを変換し、変換後の韻律データを用いて前記入力音声の韻律を変化させて出力する韻律変換部を具備する。
(もっと読む)
情報提供システムおよび情報提供装置
【課題】ユーザによる操作要求を低減し、ユーザが直感的に操作することができる情報提供システムおよび車載装置を提供する。
【解決手段】ユーザPの要求に応じたテキストデータを車載装置1によって取得する。情報解析サーバ3は、車載装置1から取得したテキストデータに基づいて、検索対象のソース種別を決定する。情報解析サーバ3は、決定したソース種別に関連するソースから情報を検索し、検索結果を車載装置1へ送信する。車載装置1は、情報解析サーバ3から受信した検索結果をユーザPへ提示する。
(もっと読む)
広告配信システム、広告配信方法及び広告配信プログラム
【課題】デジタルサイネージにおいて配信した広告のターゲット層に属する視聴者からのフィードバックをより適切に収集して利用することができる広告配信システムを提供する。
【解決手段】広告配信システムは、顧客情報を記憶する顧客情報記憶手段と、広告を表示する広告表示手段と、前記広告を視聴する視聴者の会話を入力する音声入力手段と、前記入力された会話に対して音声認識を行う音声認識手段と、前記音声認識された音声認識結果を収集する収集手段と、前記収集した音声認識結果に基づいて前記顧客情報記憶手段に記憶されている顧客情報を更新する更新手段と、を備える。
(もっと読む)
対話内容抽出装置、対話内容抽出方法、そのプログラム及び記録媒体
【課題】コンタクトセンタ等における対話内容の検索・分析・視聴の効率化を図る。
【解決手段】音声認識部は、対話音声信号が入力され、認識辞書を参照して音声認識処理を行うことにより、テキスト文書に変換して出力する。個人情報検出部は、認識辞書を参照してテキスト文書を構成する各単語について個人情報にあたるか否かを判断し、個人情報にあたる各単語のテキスト文書内での位置情報を出力する。本人確認発話位置特定部は、各単語の位置情報に基づき、個人情報にあたる単語が集中して現れている部分を特定する。挨拶発話位置特定部は、テキスト文書が入力され、定型辞書を参照して開始定型文と一致する文字列を含む部分及び終了定型文と一致する文字列を含む部分をそれぞれ特定する。対話内容抽出部は、本人確認発話位置特定部及び挨拶発話位置特定部でそれぞれ特定された部分以外の残りの部分をテキスト文書から時系列に抽出する。
(もっと読む)
情報記録装置
【課題】 情報記録再生装置の使い勝手を向上させる。特にシーンの区切りの設定を簡便
化する。
【解決手段】 音声認識手段を備え、記録中に特徴抽出されたタイミングで、シーンの区
切りを設定し、同時にサムネールを設定する。再生時には、該サムネールと同時に、特徴
抽出時の音声を同時に出力する。
(もっと読む)
音声認識支援システム、音声認識支援装置、利用者端末、方法およびプログラム
【課題】利用者が外出先等で音声を入力して音声認識を行う場合においてその場所で入力された音声の音声認識結果の誤りを低減させる。
【解決手段】音声認識支援システムは、場所を示す場所情報と、該場所についての音声認識結果の精度を示す情報とを対応づけて出力する場所認識結果精度情報出力手段501と、前記場所認識結果精度情報出力手段によって出力された場所情報と音声認識結果の精度を示す情報とに基づいて、認識対象の音声を入力する場所として指定された場所が音声認識に適しているか否かの情報を出力する音声認識場所適否情報出力手段502とを備えている。
(もっと読む)
1 - 20 / 196
[ Back to top ]