
Fターム[5L096FA72]の内容
イメージ分析 (61,341) | 特徴抽出 (17,550) | 特徴間の関係を構造化するもの (458) | セグメント間の関係 (372)
Fターム[5L096FA72]の下位に属するFターム
Fターム[5L096FA72]に分類される特許
21 - 40 / 58
学習装置及び対象物検知装置

【課題】画像に基づく対象物検知装置において、隠蔽に対応するために対象物の部位を検出する場合、設定する部位の大きさに応じた識別性能と隠蔽耐性とトレードオフの関係から一部隠蔽状態での高精度の検知が難しい。
【解決手段】検知記憶部12は、部位情報120として、予め学習により設定された、部位の情報を記憶する。部位検出部141は、入力画像の各位置において部位情報と対応する部位の有無を識別し、部位があると識別された位置を出力する。対象物判定部142は当該出力された位置が閾値以上集中しているときに対象物を検知する。部位は、識別率が目標値を超える最小の大きさに設定される。
(もっと読む)
画像処理装置、撮像装置、画像処理方法、及び画像処理プログラム、並びに記録媒体

【課題】入力された画像信号が示す画像におけるシーンを精度よく判別して、当該画像信号に対する画像処理を適切に行う。
【解決手段】画像処理装置は、画像信号が示す画像をその行方向及び列方向に複数のブロック領域に分割して、これらブロック領域毎にその色分布の特徴を示す色分布情報を得る色分布情報算出部(110,111)を有している。相対的位置算出部(112,113)は色分布情報に応じてブロック領域間の相対的な位置関係を判定してブロック領域相対位置関係を得る。シーン判別部115はブロック領域相対位置関係に応じて画像信号が示す画像におけるシーンを判別してシーン判別結果を得る。制御部116はシーン判別結果に応じて画像信号の画像処理を制御する。
(もっと読む)
乗員姿勢推定装置
【課題】自己遮蔽が発生した場合の姿勢推定精度を簡易な構成で向上させる
【解決手段】運転席及びその周辺を繰り返し撮影し、撮影された画像データを取得する(S10)。そして、取得された画像データに含まれる運転者の人体特徴点を検出し(S50)、人体特徴点の位置の変化に基づいて、人体特徴点の位置(人体特徴点予測位置)を予測する(S60,S70)。さらに、人体特徴点予測位置に基づいて、運転者の行動を予測する(S80)。また、予測した運転者行動に基づいて自己遮蔽が発生するか否かを判断する(S100,S120)。そして、自己遮蔽が発生すると判断された場合には(S20:YES)、自己遮蔽用人体特徴点検出アルゴリズムに設定する(S40)。一方、自己遮蔽が発生しないと判断された場合に(S20:NO)、自己遮蔽の発生を考慮しない通常用人体特徴点検出アルゴリズムに設定する(S30)。
(もっと読む)
学習型画像分類装置及び方法並びにその処理プログラムを記録した記録媒体撮影装置
【課題】本発明は、学習時の分類対象領域の切り出し、あるいは、分類対象領域の指示等の人手による作業負担を軽減することが可能な学習型画像分類装置及び方法並びにその処理プログラムを記録した記録媒体を提供する。
【解決手段】本発明の一態様による学習型画像分類装置は、どのようにして学習用画像の一部の領域を切出すかを示す領域切出しモードに従って、学習用画像より領域を切出して教師信号を付与し、切出された領域の特徴量から特徴ベクトルを作成し、特徴ベクトルを分類するための分類パラメータを学習し、入力画像から抽出された特徴量及び上記分類パラメータを用いて、入力画像の領域の分類カテゴリを決定してそのカテゴリ名を入力画像に付与する。上記領域切出しモードは、自動的に分割された上記学習用画像の複数の領域から人によって選択された領域が統合されて得られた領域を切出す半自動領域切り出しモードである。
(もっと読む)
マーカー検知装置及びマーカー検知装置用プログラム
【課題】 撮像画像から予め定めたマーカー画像を認識し、マーカーを検知する際、小さい処理負荷で迅速に検知を行えるようにする。
【解決手段】 マーカーは4つの三角形をマーカー要素とし、近接配置した同一三角形の要素(A,A’)よりなる第1要素ペアP1と異なる同一三角形の要素(B,B’)よりなる第2要素ペアP2を図1(B)のように組み合わせて構成する。ペアP1とペアP2の位置関係は、図1(C)のようにペアP1の三角形(A,A’)それぞれの重心を結ぶ直線Cと、ペアP2の三角形(B,B’)それぞれの重心を結ぶ直線Dが所定の角度で交差するように配置する。撮影画像から白領域の形状パラメータ(円形度)を算出するという簡単な処理で要素を認識し、要素間の単純な関係を求めることでマーカーを検知することができる。
(もっと読む)
画像処理装置およびプログラム
【課題】表領域ではない領域が表領域として判定されることを少なくする。
【解決手段】コンピュータ装置においては、構造特定部204が、図形特定部201の特定した図形部分において矩形の升目部分が複数行または複数列で並んだ構造を特定する。次に、リスト作成部205が、構造特定部204で特定された構造を表すリストを作成する。コンピュータ装置は、矩形の面積が特定して構造において占める割合を求め、求めた割合を用いて図形部分が表であるか否か判定する。
(もっと読む)
マーカ検出装置、マーカ生成検出システム、マーカ生成検出装置、マーカ検出方法及びマーカ検出プログラム
【課題】 検出対象映像の背景変化により表れたパターンをマーカパターンと誤認して過剰検出することを排除し、マーカ検出を適切に行なう。
【解決手段】 マーカ検出用の画像から抽出された特徴点が所定の空間に配置され、この配置された複数の特徴点とマーカから抽出された特徴点とを照合し、マーカ検出用の画像にもとづく複数の特徴点のうち、マーカから抽出された特徴点と一致する特徴点があると、この特徴点が配置された位置又はこの位置を含む領域を一致検出領域とする照合手段10aと、複数のマーカ検出用の画像から抽出され所定の空間に配置された複数の特徴点のうち一致検出領域に配置される特徴点の数が所定数以下であると、この一致検出領域をマーカが出現しないマーカ非出現領域として検出する照合監視手段20aとを備えた。
(もっと読む)
知識ベースの選択的な視覚分析のための人工視覚システムおよび方法
【課題】蓄積した知覚の知識に従った柔軟性のあるコンピュータビジョンシステムを提供する。
【解決手段】車両またはロボットの人工知覚システムにおいて、知覚可能な感覚事象を機能的な関係を表す直接リンクによって他のノードに接続されるノードエンティティと感覚事象の接続されたグラフの関係意味記憶で表現し、感覚計測から取得した推定値で追加および修正を行って新しいグラフ構造を漸進的に適応することで、関係意味記憶を改善することを再帰的に繰り返すコンピュータビジョンシステムを構成する。
(もっと読む)
物体領域検出装置、物体領域検出方法および物体領域検出プログラム
【課題】本発明は、従来技術の必要とするターゲット物体に関しての設定処理や照合処理や追跡処理や背景差分処理を用いることなく、ターゲット物体を撮影した映像の各フレーム画像からターゲット物体の領域を検出できるようにする技術の提供を目的とする。
【解決手段】映像に対してセグメント分割を行い、それにより得た全セグメントをクラスタリング対象としてクラスタリングを行うことでセグメントクラスタを得る。続いて、セグメントクラスタが同じフレーム画像の中に共に出現する確率を算出して、その確率が大きいものとなるセグメントクラスタを物体領域クラスタとして選定することなどにより、物体領域を表現した物体領域クラスタを選定する。続いて、そのようにして得た物体領域クラスタに属するセグメントに基づいて、ターゲット物体の領域を検出する。
(もっと読む)
画像処理装置、撮像装置、画像処理方法および画像処理プログラム
【課題】正確に被写体領域を検知することができ、これにより、表現力の高い画像データを得る。
【解決手段】画像データに含まれる被写体の顔領域を検知する顔領域検知処理部103と、画像データの輝度情報、または色情報に応じて画像データの分割領域を複数取得する画像領域分割処理部105と、検知された顔領域に基づき、取得された複数の分割領域のうち被写体を構成する分割領域を取得する人物領域生成部106と、を備える。
(もっと読む)
レイアウト構造解析装置及びレイアウト構造解析方法
【課題】名刺上の文字列の属性を示すタグを特定するための規則を簡素化し、さらにタグの判別精度を高める。
【解決手段】本発明のレイアウト構造解析装置10は、名刺上の各文字列のレイアウト情報とタグとからなる第1の画像特徴量を記憶するレイアウト辞書18と、名刺から読み取った入力画像のレイアウト情報を取得するレイアウト解析部14と、文字認識結果などに基づいて記載要素毎の属性を暫定的に判定するタグ判定部15と、判定された記載要素毎のタグとレイアウト解析により得られたレイアウト情報とを関連付けた第2の画像特徴量を生成する特徴量生成部16と、第1及び第2の画像特徴量の比較結果に基づいて、入力画像の記載要素毎のタグを確定させるタグ確定部17と、を備える。
(もっと読む)
ビジョン・オン・チップ・プロセッサを用いてバーコードを捕捉および検出するためのシステムおよび方法
本発明は、CPU制御されたビジョン・システム・オン・チップ(VSoC)アーキテクチャに基づく効率的処理システムを用いてIDの特徴、例えば1Dバーコードを捕捉、検出および抽出するためのシステムおよび方法を提供する。本発明は、例示的に単一命令複数データ処理(SIMD)アーキテクチャで構成された線形アレイプロセッサ(LAP)を提供し、そこにおいてピクセルアレイの行の各ピクセルは類似の幅のアレイで個々のプロセッサに差し向けられる。ピクセルデータは、潜在的にID状の特徴を含んでいる関心領域(ROI)の大まかな検出と追跡を実行するフロントエンド(FE)プロセスで処理される。ROI検出プロセスは近隣操作におけるLAPの効率を最適化するために2部分で、すなわちピクセルアレイから画像ピクセルを読み出す間に起こる行処理ステップと、典型的に読出しが行われた後に起こる画像処理ステップで行われる。IDを包含したROIのピクセルアレイに対する相対運動が追跡および予測される。任意的にあるバックエンド(BE)プロセスは予測されたROIを用いて画像捕捉後に特徴抽出を実行する。特徴抽出は候補ID特徴を導出し、これらの候補ID特徴は検証ステップによって検証され、検証ステップはIDを確認し、精緻化されたROI、向きの角度および特徴セットを生み出す。これらの候補ID特徴は復号プロセッサまたはその他のデバイスに伝送される。 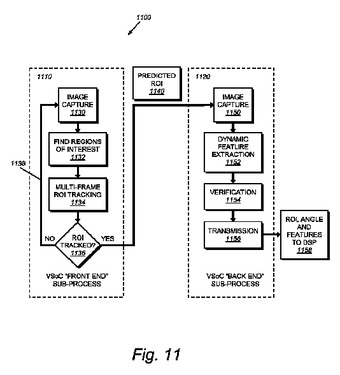 (もっと読む)
(もっと読む)
移動体を含む画像の処理方法及び装置
【課題】少ない参照系列でさまざまな移動体間動作をより詳細に分類可能にする。
【解決手段】観測量検出部26で移動体間相対動作の特徴量を観測量として検出し、該観測量の時系列を観測系列として記憶部27に記憶し、分類部28で観測系列の、予め定められた衝突観測系列に対する類似度を算出する。判定部29は、該類似度が設定値より大きい場合、記憶部30に設定されている停止禁止領域にこの類似度に関係した移動体が停止し、他の移動体が移動していれば衝突事故と判定し、該類似度以外は衝突判定条件を満たしている場合、移動体故障と判定する。観測量として、移動体間相対速度ベクトルを量子化した第1スカラーのみならず、移動体間相対位置ベクトルを量子化した第2スカラーを含むことにより、移動体間の相対動作をより詳細に分類する。移動体追跡部25ではブロック単位で追跡して、画像上で重なった移動体を識別する。
(もっと読む)
画像処理装置、画像処理方法、画像処理プログラム
【課題】動画像に適用した場合に、短時間で、時間方向に安定した処理結果を得ること。
【解決手段】本発明に係る画像処理装置1は、現フレーム画像と前フレーム画像の相違度に基づいて、現フレーム画像の各ノードの信頼度を算出するノード信頼度算出部14と、前フレーム画像の各領域に付与したタグを、対応する現フレーム画像の各ノードに対して割り当てるノードタグ割り当て部15と、現フレーム画像に含まれる2つのノードが同一の領域に含まれるか否かを判定する評価基準に基づいて、2つのノードを含む領域を算出する領域算出部16を備え、領域算出部16は、2つのノードに対して割り当てられたタグが同一のタグであるか否かを判定し、タグの一致状況とノードの信頼度に応じて、評価基準を補正する。
(もっと読む)
画像圧縮装置および画像圧縮方法
【課題】辞書化方式による画像圧縮処理を高速化することができる画像圧縮装置および画像圧縮方法を提供する。
【解決手段】入力した画像を解析してオブジェクト配置情報と頁属性情報を出力する解析部12と、オブジェクト配置情報に基いて画像を部品化して部品画像を出力する部品化部13と、既にある画像辞書の中から頁属性情報に対応する画像辞書を選び、選ばれた画像辞書と部品画像を比較して対応する画像辞書を決定し、決定した画像辞書と辞書インデックスを出力する辞書化部と、画像辞書と辞書インデックスを符号化する符号化部15をもつ画像圧縮装置。
(もっと読む)
画像撮影装置及び画像撮影方法、並びにコンピュータ・プログラム
【課題】複数の人物の顔認識結果の相互関係に基づいて好適な撮影制御を行なう。
【解決手段】各々の被写体から、笑顔度、画像フレーム内での位置、検出顔の傾き、性別などの被写体の属性といった、複数の顔認識パラメータを検出し、検出されたこれらの顔認識パラメータの相互の関係に基づいて、シャッターのタイミング決定やセルフ・タイマーの設定などの撮影制御を行なうように構成されている。具体的には、検出顔間の距離との各顔の笑顔度並びに傾きを基に、被写体間の親密度合いを「仲良し度」とも呼ぶべき数値で表すことができる。そして、算出された仲良し度が所定の閾値を超えたことに応答して撮影制御を起動する。
(もっと読む)
メッシュ衝突回避
本発明は、モデルベースの画像セグメント化を用いて画像データにおける対象物をセグメント化するシステム100に関する。このシステムは、メッシュの現在の位置に基づき上記メッシュの外部エネルギーを計算するため、上記画像データにおける特徴を特定する特徴ユニット120を有する。この特徴ユニット120は更に、上記画像データにおいて特定される上記特徴に含まれることになる特徴を特定するため、上記画像データにおける複数の候補特徴を選ぶ候補特徴ユニット122と、上記画像データの領域に対する上記複数の候補特徴の各候補特徴の位置を決定する位置ユニット124と、各候補特徴の強度を計算する特徴関数ユニットであって、上記各候補特徴の強度が、上記領域に対する上記各候補特徴の位置に依存する、特徴関数ユニット126と、上記複数の候補特徴の各候補特徴を評価し、上記評価に基づき上記複数の候補特徴における上記特徴を特定する評価ユニット128とを有する。回避されるべきである上記領域内部に、例えば、上記画像データにおける別の対象物に対して適合される別のメッシュ内部に、選ばれた候補特徴が配置されるかどうかを決定すると、上記各特徴の強度の上記計算の間、及び従って上記複数の候補特徴の上記評価の間、この候補特徴に罰を科すことが可能になる。 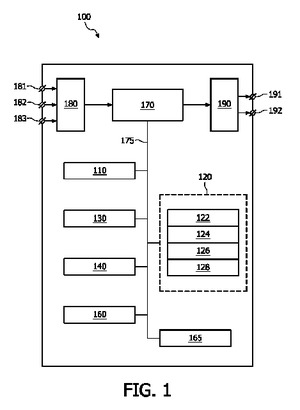 (もっと読む)
(もっと読む)
カラーリストバンドを用いた手指形状推定装置及び手指形状推定方法、並びにプログラム
【課題】手指をカメラで撮影した画像から、その手指の前腕回旋を含んだ形状をより正確に検出できるようにする。
【解決手段】手首に装着したカラーリストバンドをカメラで撮影したときの前記カラーリストバンドの色データと、前記色データの取得時の前腕回旋を含んだ手指の形状データとを記憶してデータベースを構成させる。そして、検出対象の手指を撮影して得た画像データから、カラーリストバンドの色データを検出し、その検出された色データを、データベースに記憶された色データと照合する。さらに、その照合でほぼ一致が検出された色データに基づいて、その色データに対応してデータベースに記憶された画像データを読み出し、その画像データで示される手指形状を、検出対象の手指の形状として判定する。
(もっと読む)
ラベル割当を用いた手サイン認識
【課題】 奥行画像から、重なり合ったり隣接する手を含む手話を認識するための方法およびシステムを提供する。
【解決手段】 リンク構造700は、重なり合ったり隣接する手を含んだ奥行画像212から生成した複数のセグメントを含む。重なり合ったり隣接する手形状を、(i)コスト関数および制約条件を用いてリンクグラフのセグメントを両方の手に分類するような、制約条件付最適化処理を用いるか、または(ii)複数のノードを含んだツリー構造を用いたツリー検索処理を用いて、奥行画212像で表される最も可能性の高い手形状を得る。手形状を決定した後は、リンク構造700のセグメントを、記憶している形状にマッチングさせて、奥行画像212で表されるサインを決定する。
(もっと読む)
画像処理システム及び画像処理プログラム
【課題】画像が正立以外の方向で入力されていても、画像内の領域の配置を用いることによって、その画像の方向を正立にする画像処理システムを提供する。
【解決手段】画像処理システムの画像分解手段は、画素の特徴に基づいて、画像内を領域に分解し、判別手段は、前記画像分解手段によって分解された領域を判別し、算出手段は、前記判別手段による判別結果及び前記領域の配置に応じて、前記画像の回転角度を算出し、画像回転手段は、前記算出手段によって算出された回転角度に基づいて前記画像を回転する。
(もっと読む)
21 - 40 / 58
[ Back to top ]