
国際特許分類[G06F15/80]の内容
物理学 (1,541,580) | 計算;計数 (381,677) | 電気的デジタルデータ処理 (228,215) | デジタル計算機一般 (4,503) | プログラム記憶式汎用計算機のアーキテクチャ (1,034) | 共通制御機構をもつ処理装置の配列からなるもの,例.単一命令複数データプロセッサ (410)
国際特許分類[G06F15/80]に分類される特許
1 - 10 / 410
画像音声信号処理装置及びそれを用いた電子機器
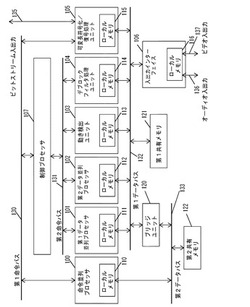
【課題】 MPEG−4 AVCの符号化/復号処理のような、大量のデータ処理量が要求される画像処理に対して、高性能で、高効率な画像処理が行える信号処理装置及びそれを用いた電子機器を提供する。
【解決手段】 信号処理装置は、命令並列プロセッサ100、第1データ並列プロセッサ101、第2データ並列プロセッサ102、及び、専用ハードウェアである動き検出ユニット103とデブロックフィルタ処理ユニット104と可変長符号化/復号処理ユニット105とを備える。この構成により、処理量の多い画像圧縮伸張アルゴリズムの信号処理において、ソフトウェアとハードウェアで負荷が分散され高い処理能力と柔軟性を実現した信号処理装置、及びそれを用いた電子機器を提供出来る。
(もっと読む)
SIMDプロセッサ及びコントロールプロセッサ並びにプロセッサ要素

【課題】2次元データを幅がPE数Nであるブロックに分割して横方向優先方式でPEのローカルメモリに格納するSIMDプロセッサの処理効率を向上させる。
【解決手段】CP150は、ローカルメモリに格納された、2次元データにおける座標値が(X,Y)である先頭データから行方向に並ぶN個のデータのローカルアドレスをPEアレイ110に対して指定する際に、アドレス算出部により得られた、ローカルアドレスA1と、ローカルアドレスA2と、閾値番号Zとを放送する。各PEは、閾値番号Zと、自身の番号との大小関係を比較すると共に、比較結果に応じてローカルアドレスA1とローカルアドレスA2のいずれかを選択する。
(もっと読む)
画像処理装置及び方法
【課題】所定の輪郭画像を有する入力画像データから、従来技術に比較して、輪郭画像の境界座標を高速で算出する。
【解決手段】複数の角度と当該各角度に対応する正接値とを格納する正接値テーブルを用いて、所定の輪郭画像を有する画像の輪郭境界点座標を検出する画像処理装置であって、主走査方向で、輪郭画像を有する画像の各画素のデータ値をデータメモリに入力しながら、各画素のデータ値が所定のしきい値以上の画素の輪郭境界点座標を検出し、検出した輪郭境界点座標に基づいて所定の中心座標に基づく各輪郭境界の正接値を計算して並列処理用メモリに格納することを副走査方向で実行し、並列処理用メモリ内の各輪郭境界点の正接値を、指定された角度に基づいて、正接値テーブルから得た正接値と並列処理により比較し、各正接値が一致したとき、一致した正接値に対応する角度の輪郭境界点座標を輪郭境界点座標として決定する。
(もっと読む)
メモリコントローラ及びSIMD型プロセッサ
【課題】画像処理などの所定の処理に用いられるSIMD型プロセッサ全体の処理時間を従来技術に比較して削減できるメモリコントローラと、当該メモリコントローラを備えたSIMD型プロセッサとを提供する。
【解決手段】リードバッファカウンタ回路51は、リードバッファRB0がプロセッサエレメントPE0〜PENのレジスタRjにデータを転送する毎にアドレス値C51をインクリメントして出力する。ループレジスタ52は、所定の最大アドレス値を格納する。比較器53は、リードバッファカウンタ回路51から出力されるアドレス値C51を最大アドレス値C52と比較し、アドレス値C51が最大アドレス値C52と一致したとき、リードバッファカウンタ回路51をリセットするためのカウンタリセット信号S53を発生してリードバッファカウンタ回路51に出力する。
(もっと読む)
ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all−to−allcommunication)を含む、複数の計算処理をスケジューリングする方法、プログラム及び並列計算機システム。
【課題】n次元の(トーラスまたはメッシュ)ネットワークを構成している複数のノード(プロセッサ)間において、全対全通信(A2A:all-to-all communication)を含む複数の計算処理を、最適にスケジューリングすること。
【解決手段】ネットワークを構成している複数のノード(プロセッサ)を、第1の部分グループに含まれる複数のノード間のみについての全対全通信に要する通信(計算処理)フェーズ(A2A−L)と、第2の部分グループに含まれる複数のノード間のみについての全対全通信に要する通信(計算処理)フェーズ(A2A−Pとに分け、複数のスレッド(スレッド1、スレッド2、スレッド3、スレッド4)にわたって、それぞれのフェーズをオーバーラップさせて並列処理する。FFT(Fast Fourier Transform)(高速フーリエ変換)やT(transpose)((内部:internal)転置)という複数の計算処理についてもあわせて、並列処理することができる。
(もっと読む)
演算制御装置及び演算制御方法並びにプログラム、並列プロセッサ
【課題】並列プロセッサに対して、並列演算に伴う複数のメモリ間でのデータ移動について、ユーザコードの開発者の負担を減らすと共に、ユーザコードの可搬性を高める。
【解決手段】属性群格納部132は、各データブロックに対して夫々設定された属性群を取得して保持する。シナリオ決定部134は、これらの属性群と、並列プロセッサである演算ユニット140の構成を示す構成パラメータとに基づいて、最下位階層のメモリと、他の階層のメモリとの間での各データブロックの転送方式を決定し、決定した転送方式に応じて各データブロックの転送、及び該転送に対応する並列演算の制御を行う。属性群は、転送方式を決定するために必要である一方、並列プロセッサの構成に依存しない属性を1つ以上含む。ライトブロックの属性群は、該ライトブロックが既に他の階層のメモリに存在し、かつ、前記最下位階層のメモリに転送されると仮定して設定されたものである。
(もっと読む)
メモリコントローラ及びSIMDプロセッサ
【課題】2次元データにおける複数の矩形領域のデータを、1矩形領域が1プロセッサ要素に対応するように、SIMDプロセッサの複数のプロセッサ要素と外部との間で交換する際に、SIMDプロセッサの効率低下を抑制する。
【解決手段】SIMDプロセッサにおけるメモリコントローラ140のアドレス記憶部142は、コントロールプロセッサにより、外部メモリにおけるN個のアドレスAi(i=1〜N)を設定可能である。パラメータ記憶部144は、コントロールプロセッサにより、第1のパラメータOSVと、第2のパラメータWと、第3のパラメータLとを設定可能である。データ転送部146は、アドレス記憶部142とパラメータ設定部144の内容に基づいて、外部メモリと、該SIMDプロセッサに含まれるN個のプロセッサ要素のバッファとの間でデータ転送を行う。
(もっと読む)
リコンフィグ可能な集積回路装置
【課題】コンテキスト間のデータ授受を無駄にハードウエアを消費することなく行うリコンフィグ可能な集積回路装置を提供する。
【解決手段】コンフィグレーションデータに基づいて任意の演算状態に構築されるリコンフィグ可能な集積回路装置において,任意の演算状態に構築可能な複数のプロセッシングエレメントと,複数のプロセッシングエレメントを任意の状態で接続するプロセッシングエレメント間ネットワークとを有し,プロセッシングエレメントは,入力データ保持レジスタと,入力データ信号を演算する演算処理回路と,演算結果データを保持する出力データ保持レジスタとを有し,ホールドモードを有効とするコンフィグレーションデータでコンフィグレーションが更新された場合は,入力信号がバリッド,インバリッドにかかわらず,入力データ信号を保持し,演算処理回路は保持された入力データ信号について演算処理を行う。
(もっと読む)
並列処理方法及び並列処理システム
【課題】 領域及び点のデータの2つを入力として各点を包含する領域の探索を高速に並列処理する。
【解決手段】 並列処理方法は、定義空間上に配置されたM個の領域とN個の点とをそれぞれ示すデータを入力する入力ステップ(S01)と、定義空間を複数の格子に分割して、分割した各格子について、入力された領域及び点のうち当該格子に少なくとも当該領域の一部及び当該点を含む領域及び点を当該格子に仕分ける仕分ステップ(S02〜S06)と、分割された各格子について一台以上の計算装置のうち一つの計算装置を選択して、選択した計算装置に当該格子に仕分けられた領域及び点を示すデータを出力する選択ステップ(S07,S08)と、計算装置のそれぞれが、入力した各点が各領域に含まれるか否かを判定して、判定の結果を出力する計算ステップ(S09,S10)とを有する。
(もっと読む)
集積回路装置及び電子機器
【課題】グラフィックス処理性能をスケーラブルに調整可能であり、目標とする処理性能に応じて、最適なシステムを構築することのできる集積回路装置を提供する。
【解決手段】目標性能に応じた数の集積回路をカスケード接続することにより、グラフィックス処理性能をスケーラブルに拡張又は縮小できるという知見に基づく。第1の集積回路1と、第2の集積回路2と、第1の集積回路1と第2の集積回路2を接続する通信用バス4と、第1の集積回路1の演算結果を第2の集積回路2に出力するための入出力用バス5を含む。
(もっと読む)
1 - 10 / 410
[ Back to top ]