
国際特許分類[G10L21/02]の内容
物理学 (1,541,580) | 楽器;音響 (32,226) | 音声の分析または合成;音声認識;音響分析または処理 (17,022) | 他の可聴信号,または不可聴信号への音声信号変換処理,例.特性や明瞭性を修正するための視覚,触覚 (2,017) | 音声の強調,例.雑音低減またはエコー除去 (1,255)
国際特許分類[G10L21/02]に分類される特許
1,121 - 1,130 / 1,255
車載収音装置及び車内収音情報表示方法
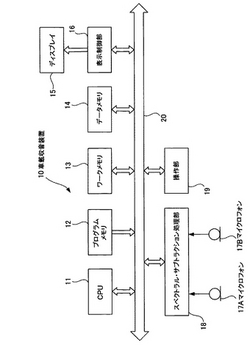
【課題】音源の方向とその音量を従来よりもさらに直感的に把握することができる車載収音装置及び車内収音情報表示方法を提供する。
【解決手段】車内に設置した2つのマイクロフォン17A及び17Bにて車内で話者の音声を収音し、入力音圧レベルを表す画像データと2つのマイクロフォン17A及び17Bによる指向性を表す画像データをデータメモリ14から読み出して、それらの画像データからドット展開した表示データを生成してディスプレイ15上に表示するので、話者の発声を音源とするその方向とその音量を従来よりもさらに直感的に把握することが可能となり、例えばナビゲーション装置を適切な発声音量で音声操作を行うことができる。
(もっと読む)
帯域分割型雑音抑圧装置及び帯域分割型雑音抑圧方法

【課題】 少ない処理量で音声歪が少なくかつ十分に雑音を抑圧すること。
【解決手段】 帯域分割部101は入力音声信号を低域音声信号と高域音声信号とに分割する。低域音声信号は間引き処理部102にて間引き処理を受け、低域雑音抑圧部103にて雑音抑圧処理を受け、補間処理部104にて補間され、帯域合成部106に入力する。一方、高域音声信号は高域雑音抑圧部105にて雑音抑圧処理を受け、帯域合成部106に入力する。帯域合成部106は、雑音が抑圧された低域と高域の音声信号の帯域合成処理を行い、全帯域で雑音が抑圧された音声信号を出力する。
(もっと読む)
通信システムにおけるフレームの連結方法
サンプルの第1のフレームとサンプルの後続の第2のフレームとを連結するための方法であって、本方法は、上記サンプルの第1及び第2のフレーム間の境界における不連続性を最小化するように適合化された位相フィルタを適用することを含む。  (もっと読む)
(もっと読む)
雑音抑圧装置及び音声認識システム
【課題】 非定常雑音下での音声認識性能を改善し、かつ雑音の抑圧を短時間で行なうことができる雑音抑圧装置を提供する。
【解決手段】 雑音抑圧部114は、クリーン音声と雑音とが重畳した雑音重畳音声について所定周期ごとにフレーム化された所定時間長のフレームよりそれぞれ抽出される特徴量124を受けて、雑音重畳音声に関する所定の状態空間モデルと、目的音声に関するクリーン音声HMMとを基に、パーティクルフィルタを用いて、雑音の推定パラメータ206をフレームごとに逐次生成するための雑音確率分布推定部200と、雑音重畳音声の特徴量124と、雑音の推定パラメータ206と、クリーン音声HMM130とを用いて、フレームごとに目的音声の推定特徴量126を算出するためのパラメータ生成部202及びクリーン音声推定部204とを含む。
(もっと読む)
聴覚補助装置、音声信号処理方法、音声処理プログラム及びコンピュータで読み取り可能な記録媒体並びに記録した機器
【課題】低負荷な演算処理で聞き取りやすい音声に補正可能な聴覚補助装置等を提供する。
【解決手段】聴覚補助装置は、音声入力部10で入力された音声信号の振幅を量子化し、量子化された各点のデータにつき、隣接する所定の範囲のデータの振幅値を加算し、これを加算したデータの個数で除算して該データを中心とする部分平均値を求め、各点のデータの振幅値と各々の部分平均値とを比較し、比較結果の真偽に基づいて凹凸波形に変換するための凹凸波形変換部14と、音声信号の凹凸波形から、人の声に対応する声成分を抽出するための声成分抽出部16と、声成分の凸部を高く、凹部を低くすることで強調し、強調声波形を生成するための強調処理部18を備える。
(もっと読む)
フィルタリング装置
【課題】 時々刻々変わる音環境の状況の中で、本来伝えるべき音のみを相手に伝えるように音の情報制限を行なうことによって、音のプライバシを守ること。
【解決手段】 音識別分離抽出により得られた、現在の音環境に存在する各音とその音の意味(種類)を求め、時刻、場所、電話番号、スケジュール帖、相手との関係などの通話者に関する客観的な情報から推定される状況において期待される音の意味(種類)とを比較し、その結果に応じて、どの音を許可/禁止するか選択判断を行ない、音を加工出力することにより、通話者の音に関するプライバシが場所や相手との関係に応じて選択的に守ることができる。
(もっと読む)
音楽と音声の合成システム及び方法、及びこれを利用したサービスシステム及び方法{SYSTEMANDMETHODFORSYNTHESIZINGMUSICANDVOICEANDSERVICESYSTEMANDMETHODTHEREOF}
本発明は、音楽と音声を合成するためのシステム及び方法、及びこれを利用したサービスシステム及びサービス方法に関する。本発明によるシステム及び方法は、音声と音楽を合成することで、リスナーがミキシングの効果を最大限感じることができる。また、本発明によるシステム及び方法は、専用のシンセサイザーのボリューム調節無しに、音声および音楽を様々な効果を付して合成することができる。 (もっと読む)
音声処理装置
【課題】ユーザの音声入力時の音響環境を向上することのできる「音声処理装置」を提供する。
【解決手段】スピーカ3から出力されたオーディオ音A1とユーザの発話音声信号Sとその他のノイズ音Nは、マイク4から入力しマイク出力信号となる。マイク出力信号は入力アンプ5で増幅された後、A/D変換器6でデジタル信号に変換され、発話音声抽出部7に入力する。発話音声抽出部7は、入力したデジタル信号中から発話音声信号成分を抽出し音声認識装置8に入力する。ゲイン制御部10は、A/D変換器6が出力するデジタル信号の発話音声信号成分を除く成分である環境音信号が示す環境音下で、発話音声信号成分が表す発話音声が明瞭に聞こえるように、スピーカ3の出力音量を調整する出力調整アンプ22のゲインを制御する。
(もっと読む)
ロボット装置およびその制御方法
【課題】ロボット装置と操作者間の距離が離れている場合に、肢体と移動手段を利用することにより音声の誤認識を回避し、音声認識の機能を向上できるロボット装置および制御方法を提供する。
【解決手段】移動手段を有した基部101と、基部101の上部に設けられた胴部103と、胴部103の側面上部に設けられたアーム104と、表示機能を有した顔部107と、操作者の音声指令を検知する聴覚センサ105と、操作者の体や顔を検知する視覚センサ106とを備えるロボット装置において、聴覚センサ105をアーム端に備える。
(もっと読む)
音声信号の音響レベルを周波数に依存して増幅する信号処理装置及び音声システム及びその方法
本発明な、音声信号の音響レベルの周波数に依存する増幅方法に関する。当該方法では音声信号(Sig(f))は少なくとも特定の周波数範囲において複数(n)の周波数帯(f1...f10)に分割され、及び特定の可聴閾値(Th(f1)...Th(f10))は周波数帯(f1...f10)毎に指定され、及び各周波数帯では音響レベルは個々の可聴閾値と比較され、音声信号(Sig(f2)、Sig(f3)、Sig(f4))は、少なくとも、音響レベルが個々の可聴閾値(Th(f2)、Th(f3)、Th(f4))の直下にある周波数帯内で増幅される。本発明は、当該方法を実施する信号処理装置、及び当該信号処理装置を備えた音声システムに更に関する。  (もっと読む)
(もっと読む)
1,121 - 1,130 / 1,255
[ Back to top ]