
Fターム[5B045GG11]の内容
マルチプロセッサ (2,696) | プログラム、命令の実行処理 (212) | 並列処理 (89)
Fターム[5B045GG11]の下位に属するFターム
アレイプロセッサ、行列配置によるもの (29)
SIMD (12)
MIMD (5)
Fターム[5B045GG11]に分類される特許
1 - 20 / 43
情報処理装置、情報処理方法及び制御プログラム
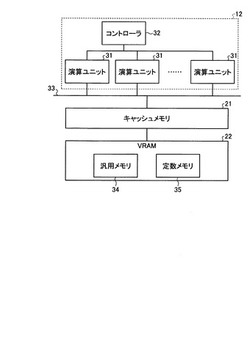
【課題】メモリに対するアクセス時間を低減し、ひいては、実行パフォーマンスを向上する。
【解決手段】実施形態の情報処理装置は、並列処理が可能な複数のプロセッサと、前記複数のプロセッサで共有されるメモリと、を備えている。そして、割当手段は、メモリのアクセス範囲が予め記述可能とされるとともに複数のスレッドで構成されたワークグループを、それぞれ記述されたアクセス範囲を参照して複数のプロセッサのいずれかに実行させるために割り当てる。
(もっと読む)
マルチコアプロセッサシステム、レジスタ利用方法、およびレジスタ利用プログラム

【課題】マルチコアプロセッサシステムでの処理能力の向上を図ること。
【解決手段】初めに、CPU#0は、CPU#0〜CPU#2に割り当てられるスレッドA_0〜スレッドA_2に関する同期命令に偏りがあることを示す情報を取得する。次に、CPU#0は、CPU#0のレジスタを共有元として、CPU#1、CPU#2がレジスタI/F102を通してCPU#0のレジスタにアクセスするようにレジスタI/F102#0〜レジスタI/F102#2に通知する。このように、マルチコアプロセッサシステム100は、CPU#0〜CPU#2のうち同期通知を実行するCPU#0のレジスタをCPU#1とCPU#2に共有させることにより、CPU#0〜CPU#2にてスレッドA_0〜スレッドA_2を実行する。
(もっと読む)
データ処理装置及びデータ処理方法
【課題】 データ処理の領域を分割して複数のプロセッサに並列処理させる際に、分割の最小単位を小さくする。
【解決手段】 データ処理装置が、第一のデータ処理を複数のプロセッサに並列処理させ、並列処理されたデータを記憶部に格納する際に、複数のプロセッサのデータキャッシュのサイズに基づいて記憶部のアドレスを変換して格納する。そして、記憶部に格納されたデータを読み出し、読み出したデータに対して第二のデータ処理を行う。
(もっと読む)
並列処理システム及び並列処理システムの動作方法
【課題】複雑な制御機能を設けることなく、処理性能を向上させることのできる、並列処理システム及び並列処理システムの動作方法を提供する。
【解決手段】並列処理システムは、ネットワークを介して互いにアクセス可能に接続され、複数の処理を分散して実行する、複数の計算機を具備する。前記複数の計算機の各々は、割り当てられた処理を実行する演算処理装置と、第1領域及び第2領域を有する、ローカルメモリ群と、入出力制御回路とを備える。前記演算処理装置は、第1期間において、前記第1領域をアクセス先アドレスとして処理を実行し、前記第1期間に続く第2期間において、前記第2領域をアクセス先アドレスとして処理を実行する。前記入出力制御回路は、前記複数の計算機間で通信を行なうことにより、前記ローカルメモリ群に格納されたデータを最新のデータになるように更新する、更新部を備える。前記更新部は、前記第2期間において、前記第1領域に格納されたデータを更新するように構成されている。
(もっと読む)
グラフィックスプロセッサ
【課題】メモリボトルネックによる性能低下を抑制する
【解決手段】グラフィックスプロセッサは、複数の画素データそれぞれの処理を並列して行う複数のプロセッサコアと、複数のプロセッサコアにより共有されるレジスタと、レジスタを制御するレジスタ制御部と、画素データを保持する画素保持メモリとを備える。レジスタは、画素毎に、画素データと前記画素データに対応する画素座標データとを保持する。レジスタ制御部は、画素座標データを検索キーにレジスタを検索する検索部を含む。
(もっと読む)
情報サービスシステム
【課題】計算資源を有効に利用して効率良く情報サービスを提供することが可能な技術を提供する。
【解決手段】ハードウェアリソース群のハードウェアリソースは、他のリソースに依存せずにデータの入出力が可能であり、割り当てられた実行回路を実体化し、その実行回路によって情報サービスのデータ処理を実行する。サービスマネージャは、ユーザから要求された情報サービスに必要なハードウェア機能を判別し、そのハードウェア機能をハードウェアリソースマネージャに要求する。ハードウェアリソースマネージャは、要求されたハードウェア機能に必要なハードウェアリソースをハードウェアリソース群の中から確保し、確保したハードウェアリソースにハードウェア機能の実行回路を実体化させる。
(もっと読む)
データ処理装置及びデータ処理方法
【課題】入力画像の種類や画像内の処理位置による性能変動が少なく、均一の高い処理性能をもつデータ処理装置を提供する。
【解決手段】部分データに対する前段のステージでの処理結果に応じて当該部分データに対する後段のステージでの処理を実行するか否かが決定されるデータ処理を、各ステージに複数の処理モジュールを分配し、ステージ間及び少なくとも1つのステージ内において複数の部分データを並列に処理するように複数の処理モジュールを接続する接続部を有する。データ処理装置は、各ステージについて、後段のステージに処理を実行させる処理結果が得られた率を通過率として検出し、この通過率に基づいて各ステージで処理されるデータ量に対する処理時間を取得し、この処理時間が均一になるように各ステージに分配する処理モジュールの個数を決定する。そして、決定された分配にしたがって、接続部による複数の処理モジュールの接続状態を変更する。
(もっと読む)
画像処理装置、画像形成システム及び画像処理プログラム
【課題】 パイプライン処理方式とリコンフィグ処理方式のうち、画像処理に要する時間が短い方の処理方式で複数のDRPを稼動させる画像処理装置、画像形成システム及び画像処理プログラムを提供することを目的とする。
【解決手段】 入力された印刷ジョブの画像情報の画素数に基づいて、リコンフィグ処理方式によって画像処理する場合に要する第1処理時間とパイプライン処理方式によって画像処理する場合に要する第2処理時間とを算出する処理時間算出部32aと、処理時間算出部32aにより算出された第1処理時間と第2処理時間のいずれか短い時間の処理方式によって、複数のDRP61〜66を稼動させる稼動制御部32bと、を有する。
(もっと読む)
SIMDベクトルの同期
プロセッシングデバイス内のデコーダによって、第1記憶ロケーション、第2記憶ロケーション及び第3記憶ロケーションの間の複数のデータ要素に対するベクトル比較/交換オペレーションを規定する単一命令をデコードする段階と、プロセッシングデバイス内の実行ユニットによって実行するために、単一命令を発行する段階と、単一命令の実行に応答して、第1記憶ロケーションからのデータ要素と、第2記憶ロケーションにおける対応するデータ要素とを比較する段階と、一致が存在するかに応じて、第1記憶ロケーションからのデータ要素を、第3記憶ロケーションからの対応するデータ要素で置き換える段階とを実行することによって、ベクトル比較/交換オペレーションが実行される。 (もっと読む)
コンピュータ、プロセス間通信プログラム、およびプロセス間通信方法
【課題】複数のプロセスが実行されるサーバによるクラスタシステムにおける効率的な全対全のプロセス間通信を可能とする。
【解決手段】送信先サーバ決定手段4aには、全対全のプロセス間通信の同一回の送信先サーバ決定において、複数のサーバが互いに異なるサーバを送信先サーバとして決定するような送信先サーバ決定手順が予め定義されている。そして送信先サーバ決定手段4aには、コンピュータAで実行される自プロセスからの全対全のプロセス間通信要求に応答し、送信先サーバ決定手順に従って送信先サーバを繰り返し決定する。送信先プロセス決定手段4bは、送信先サーバが決定されるごとに、送信先サーバで動作しているプロセスを順番に送信先プロセスとして決定する。データ送信手段4cは、送信先プロセスが決定されるごとに、送信先サーバ内の決定された送信先プロセスに対して取得した送信データを送信する。
(もっと読む)
並列処理システム制御装置、その方法及びそのプログラム
【課題】並列処理システムを制御するための並列処理システム制御装置であって、並列処理システムの各プロセッサ及び各共有メモリの差異を隠蔽し、アプリケーションプログラムから統一的に並列処理システムを制御する並列処理システム制御装置を提供する。
【解決手段】固有のプロセッサに依存しない共通コマンドを解析してアプリケーションプログラム40の各部分処理を実行する各プロセッサを特定し、各部分処理の入出力データ用のバッファが格納された共有メモリを特定し、各プロセッサが入出力データ用のバッファをアクセスするためのアドレスを特定し、共通コマンドを各プロセッサへの個別のコマンドであるプロセッサ個別コマンドに変換し、並列処理システムを実行制御するための、共通コマンド変換・メモリ管理部、個別実行制御部、メモリ管理情報、個別実行制御登録部と、を備える。
(もっと読む)
分散型シミュレーションシステム
【課題】各シミュレータ間のデータの配送経路の設定が、容易に且つ適切に設定可能な分散型シミュレーションシステムを提供する。
【解決手段】管理装置により設定されたシミュレータ間のデータ配送経路情報に基づいて他のシミュレータに送信すべきデータの一覧情報を当該他のシミュレータに送信し、一覧情報に含まれるデータが格納される当該他のシミュレータの共有メモリのアドレス情報を当該他のシミュレータから受信し、当該アドレス情報に対応づけて自己の共有メモリに当該データの格納アドレスを設定するとともに当該データが格納される自己の共有メモリと他のシミュレータの共有メモリ間のアドレス変換テーブルを生成する共有メモリ管理部と、当該アドレス変換テーブルに基づいて自己の共有メモリから読み出した送信用データを他のシミュレータの通信処理部に送信する通信処理部を各シミュレータに備えている。
(もっと読む)
データ処理装置、印刷システムおよびプログラム
【課題】CPUとGPUとの間で、大量のデータを効率良く処理する。
【解決手段】複数の処理を非同期で並列に実行可能なデバイス3と、このデバイス3との間でデータの授受を行うホスト2とを有し、ホスト2には、システムメモリ12内にデバイス3との間でデータ転送を行うためメモリ領域が確保され、デバイス3は、ホスト2からのデータを処理している間に並列してメモリ領域へのアクセスを行ってデータ転送を行い、ホスト2では、デバイス3に転送するデータを3以上に分割し、分割された2番目以降のデータについて、デバイス3で前回のデータが処理されている間に、メモリ領域への書き込みを行う。
(もっと読む)
マルチプロセッサシステム、ノードコントローラ、障害回復方式
【課題】ノードコントローラの障害によるシステム停止時間を短縮することが可能なマルチプロセッサシステムを提供することにある。
【解決手段】第一ノードコントローラと第二ノードコントローラは、リクエストに含まれるアクセス先のメモリアドレスに基づいて、リクエストの送信先の識別子を決定する第一、及び第二リクエスト制御部と、第一リクエスト制御部へリクエストを出力すべきリクエストの送信先の識別子を記憶する第一レジスタと、第二リクエスト制御部へリクエストを出力すべきリクエストの送信先の識別子を記憶する第二レジスタと、リクエストを受信すると、リクエストの送信先の識別子と、第一、及び第二レジスタに設定された識別子に基づいて、第一、第二リクエスト制御部のいずれかにリクエストの出力先を決定する第一ルーティングテーブルと、第一、第二リクエスト制御部の決定した送信先の識別子に基づいて、送信先の識別子に対応する信号線を選択して、リクエストを送信する第二ルーティングテーブルと、を備える。
(もっと読む)
マルチコア通信トポロジを生成する装置および関連する方法
マルチコア通信トポロジを生成する装置および関連する方法。マルチコアコンピュータの予め決められた数のコアに対応するトポロジが、アプリケーションプログラミングデバイスを用いて生成される。多くのノードが、マルチコア通信トポロジの予め決められた数の利用可能なコアに対するマッピングのために記述される。多くのノードの各々の特性が特定される。マルチコア通信トポロジのノードの各々間の通信が、アプリケーションプログラミングデバイスの電子メモリの専用のマルチコア通信ライブラリを用いて特定される。検証された出力ファイルは、アプリケーションプログラミングデバイスでマルチコアトポロジのために生成される。出力ファイルは、マルチコアコンピュータのためにマルチコア通信可能実行可能アプリケーションプログラムインターフェース(API)を生成するように処理される。  (もっと読む)
(もっと読む)
単一パステセレーション
【課題】 テセレーションシェーダープログラムを実行するための改良されたシステム及び方法を提供する。
【解決手段】 グラフィックプロセッサを通して単一パスでテセレーションを実行するシステム及び方法は、グラフィックプロセッサ内の処理リソースを、異なるテセレーションオペレーションを実行するためのセットへと分割する。頂点データ及びテセレーションパラメータは、メモリに記憶されるのではなく、1つの処理リソースから別の処理リソースへ直接ルーティングされる。それ故、表面パッチ記述がグラフィックプロセッサに与えられ、そしてメモリに中間データを記憶せずに、グラフィックプロセッサを通して単一の非中断パスでテセレーションが完了される。
(もっと読む)
スレッドに最適化されたマルチプロセッサアーキテクチャ
一態様において本発明はシステムであり、(a)単一のチップ上の複数の並列プロセッサと、(b)チップ上に配置されていて、かつプロセッサの各々によってアクセス可能なコンピュータメモリとを備えていて、プロセッサの各々は、de minimis命令セットを処理するように動作可能であり、プロセッサの各々は、プロセッサの中の少なくとも3つの特定のレジスタの各々専用のローカルキャッシュを有している。別の態様において本発明はシステムであり、(a)単一のチップ上の複数の並列プロセッサと、(b)チップ上に配置されていて、かつプロセッサの各々によってアクセス可能なコンピュータメモリとを備えていて、プロセッサの各々は、スレッドレベルの並列処理のために最適化された命令セットを処理するように動作可能であり、各プロセッサは、チップ上のコンピュータメモリの内部データバスにアクセスし、内部データバスはメモリの1行の幅である。  (もっと読む)
(もっと読む)
分散メモリ型マルチプロセッサシステム、マスク付き逆シフト通信方法及びプログラム
【課題】 並列ループの実行速度を高速化できると共に、使用メモリ量を削減することができる分散メモリ型マルチプロセッサシステムを提供する。
【解決手段】 配列データを計算ノードの記憶手段上に分割配置し、当該配列データを使用・定義するプログラム中のループを計算手段上で並列実行する分散メモリ型マルチプロセッサシステムであって、計算ノードが、各計算ノードで定義する配列要素が、他の計算ノードの記憶手段上に分割配置されている配列要素である場合に、並列ループ実行中は、自身の計算ノードの配列データと連続した領域に確保したマスク付き逆シフト通信用バッファに使用・定義する値を格納し、並列ループ実行後に、定義が行われたマスク付き逆シフト通信用バッファの値を、計算ノード間通信手段を経由して他の計算ノードに通信し、他の計算ノード上に配置されている対応する配列要素に反映させるマスク付き逆シフト通信手段を含む。
(もっと読む)
マルチプロセッサシステム
【課題】並列処理用のマルチプロセッサにおいて、価格性能比を改善し、高まりつつある半導体集積度にスケーラブルな性能向上を達成する。
【解決手段】CPUと、分散共有メモリと、ローカルデータメモリと、を備える複数のプロセッシングエレメントと、前記各プロセッシングエレメントに接続される集中共有メモリと、を備えるマルチプロセッサであって、前記各プロセッシングエレメントに割り当てられたタスク間で共通に使用されるデータが、前記各タスクで必要とされるとき以前に、データの消費先の前記プロセッシングエレメントの前記分散共有メモリへ転送され、前記集中共有メモリは、粗粒度並列処理において条件分岐に対応するために使用されるダイナミックスケジューリングにおいて、プログラムの実行時までどのCPUにより使用されるかが決まっていないデータを格納する。
(もっと読む)
ネットワーク・オン・チップ(NOC)上のソフトウェア・パイプライン化の方法、プログラムおよび装置
【課題】統合プロセッサ(IP)・ブロック、ルータ、メモリ通信制御装置およびネットワーク・インターフェース制御装置を含むネットワーク・オン・チップ(NOC)を提供すること。
【解決手段】各IPブロックがメモリ通信制御装置およびネットワーク・インターフェース制御装置を介してルータに接続され、各メモリ通信制御装置がIPブロックとメモリとの間の通信を制御し、かつ各ネットワーク・インターフェース制御装置がルータを介したIPブロック間の通信を制御し、また、このNOCが、ステージに分割されたコンピュータ・ソフトウェア・アプリケーションを含み、各ステージがステージIDによって識別されるコンピュータ・プログラム命令が柔軟に設定可能なモジュールを備え、IPブロック上のスレッドで実行する。
(もっと読む)
1 - 20 / 43
[ Back to top ]