
Fターム[5B064AA01]の内容
Fターム[5B064AA01]に分類される特許
201 - 220 / 787
文字認識装置、文字認識プログラム、および文字認識方法

【課題】文字が含まれている画像データに対して、手軽な操作で高速の文字認識を実現する文字認識装置、文字認識プログラム、および文字認識方法を提供する。
【解決手段】携帯端末1により、主に英数文字からなる第1認識用英数文字部24aおよびカテゴリ用文字からなる第1認識用カテゴリ文字部24bと、これ以外の文字を含みこれらの文字よりも文字数が多い第2認識用文字についての第2認識用文字部24cとを区別可能に記憶しておき、第1認識用英数文字部24aおよび第1認識用カテゴリ文字部24bによる第1文字認識処理を実行し(ステップS4)、該処理でのマッチング信頼度が低い場合に(ステップS5〜S6)、少なくとも第2認識用文字部24cにより文字認識を実行する第2文字認識処理(ステップS7)を実行する。
(もっと読む)
SIMD型プロセッサ、文字認識装置、文字認識システム、文字認識方法、プログラム及び記録媒体

【課題】文字認識を高速に行うSIMD型プロセッサ、文字認識装置、文字認識システム、文字認識方法、プログラム及び記録媒体を提供する。
【解決手段】同一処理を並行して実行できる複数の内部プロセッサと、内部プロセッサとデータ転送を行うグローバルプロセッサを備えるSIMD型プロセッサが、各内部プロセッサの内蔵メモリに記憶されている辞書データに登録されている文字の特徴量毎に未知文字の特徴量データとの特徴量間距離を算出し、算出された特徴量間距離のうち、最小値1を選出し、各内部プロセッサが選出した複数の最小値1から最小値2を選出し、最小値2と、最小値2を保持していた内部プロセッサの識別番号と、該内部プロセッサで最小値1になった特徴量間距離を示す通し番号とを出力し、さらに最小値2を最大値に置き換え、再び、最小値1と最小値2を選出すなわち次に小さい特徴量間距離の選出を所定の回数行うことを特徴とする。
(もっと読む)
電子機器及び情報表示プログラム
【課題】複数の不明語句が立て続けに生じた場合であっても確実に見出語検索できる。
【解決手段】電子辞書1は、メインディスプレイ10と、見出語に説明情報を対応付けてなる辞書情報を複数記憶するフラッシュROM80と、ユーザによる手書き入力を受け付けるタッチパネル11aと、タッチパネル11aにより入力された複数の筆跡情報をメインディスプレイ10に表示させ、表示された複数の筆跡情報から任意の筆跡情報をユーザ操作に応じて選択し、選択された筆跡情報を文字列として文字認識し、文字認識された文字列を検索語として設定し、この検索語に対応する見出語を辞書DB84から検索し、当該見出語を含む辞書情報をメインディスプレイ10に表示させるCPU20と、を備える。
(もっと読む)
文字認識方法および文字認識装置
【課題】認識対象とする文字種が異なる場合であっても文字認識に用いる閾値を適切に設定するとともに、文字認識の認識精度を向上させること。
【解決手段】認識結果登録部が、同一文字種の各文字データについての1位候補距離値および距離差を正読または誤読の別と対応付けてサンプル値として記憶し、確率領域生成部が、正読のサンプル値の分布に基づく正読確率領域と、誤読のサンプル値の分布に基づく誤読確率領域とを生成するように文字認識装置を構成する。また、境界線決定部が、正読確率領域および誤読確率領域の位置関係に基づき、文字認識に用いる閾値として境界線を決定し、文字認識部が、文字認識結果に対応する1位候補距離値および距離差の組を境界線と対比するように文字認識装置を構成する。
(もっと読む)
電子インク処理
【課題】本発明の目的は例えば電子インクのレイアウトの分析、分類、および/または認識を行うために各種のソフトウェアアプリケーションによって用いることが可能な電子インクの処理技術を提供することである。
【解決手段】アプリケーションプログラミングインターフェースは、インクアナライザオブジェクトをインスタンス化し、そのインクアナライザオブジェクトは、文書をホストし第1の処理スレッドで実行する、ソフトウエアアプリケーションからの電子インクコンテンツを含む文書についての文書データを受け取る。ついで、インクアプリケーションオブジェクトは、第1の処理スレッドを使用して、文書データのコピーを作成し、文書データのコピーを電子インク分析プロセスに提供し、第1の処理スレッドのコントロールを分析プロセスに返す。
(もっと読む)
文字認識プログラム、文字認識方法および文字認識装置
【課題】文字の接触パターンを精度よく判定すること。
【解決手段】文字認識装置(コンピュータ)1は、比較手段2および判定手段3として機能する。比較手段2は、一文字であると判定された判定対象パターンの構造を、記憶部4に記憶された一文字パターンの構造と比較する。判定手段3は、比較手段2の比較結果に加え、サイズ情報(パターンの高さに対する幅の比)を用いて、判定対象パターンを一文字であるか否かを判定する。
(もっと読む)
画像処理装置及び画像処理方法
【課題】視覚的に誤りのない文字区切り境界を得ることができ、元文書画像の内容を変えずに、再編集(再レイアウト、文字効果の変更等)を行うことを目的とする。
【解決手段】文書画像から文字画像を抽出する抽出手段と、抽出手段で抽出された文字画像が分離文字であるか否かを判定する判定手段と、判定手段で分離文字と判定された場合、分離文字と判定された文字画像と、文字画像の後続の文字画像と、の間隔を保持するよう分離文字と判定された文字画像と、後続の文字画像と、を文書画像に配置する配置手段と、を有することによって課題を解決する。
(もっと読む)
文字図形認識方法、情報処理システムおよび情報処理装置
【課題】利用環境によらず容易にかつ安価に実現できるとともに、誤認識を低減可能な文字認識方法、これを実施する情報処理システムおよび情報処理装置を提供する。
【解決手段】情報処理手段により、入力手段を介して筆記入力された筆記情報と筆記時の位置を特定可能な情報を受信する処理と、筆記時刻を取得する処理と、前記受信した筆記時の環境を特定可能な情報と、記憶手段にあらかじめ記憶されている、前記筆記時の環境を特定可能な情報と前記筆記情報の文字や図形を含む前記筆記時の環境を示す情報との対応付け情報とに基づき、該当する前記筆記時の環境を特定する処理と、該筆記時の環境を特定する情報と、前記記憶手段にあらかじめ記憶されている、前記筆記時の環境を示す情報と筆記予定時刻との対応付け情報と、前記筆記情報と、前記筆記時刻とに基づき、前記筆記情報の文字や図形を認識する処理とを実施する。
(もっと読む)
画像読取装置、画像読取装置の制御方法、制御プログラム、及び記憶媒体
【課題】磁気インク文字が傾いた状態で磁気ヘッドを通過した場合における磁気インク文字の誤認識を防止することができる画像読取装置を提供する。
【解決手段】画像読取装置は、原稿に印刷された磁気インク文字を磁気データとして読み取る磁気読取手段(ステップS101)と、読み取られた磁気データとMICR辞書情報とを比較することで得られる磁気的類似度に基づいて、磁気インク文字を認識する磁気文字認識手段(ステップS103)と、原稿の画像を画像データとして光学的に読み取る読取手段(ステップS102)と、読み取られた画像データに基づいて、画像の傾き角を算出する算出手段(ステップS104)と、磁気文字認識手段による磁気インク文字の認識結果と算出手段により算出された前記画像の傾き角とに基づいて、磁気インク文字を最終認識する最終認識処理手段(ステップS105)と、を備える。
(もっと読む)
文書の有効性を決定するためのシステム、方法およびコンピュータプログラム製品
一実施形態による方法は、電子的第1の文書から識別子を抽出するステップと、識別子を使用して、第1の文書と関連付けられた相補的文書を識別するステップと、を含む。第1の文書の有効性は、第1の文書からのテキスト情報、相補的文書からのテキスト情報、および所定のビジネスルールを同時に検討することによって決定される。決定された有効性は、表示として出力される。また、上述の方法論を提供、実行、および/または有効化するためのシステムおよびコンピュータプログラム製品も、提示される。 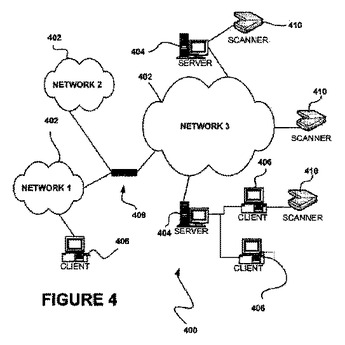 (もっと読む)
(もっと読む)
画像処理装置および画像処理方法
【課題】文字画像から文字を認識する精度を向上する。
【解決手段】この画像処理装置は、文書画像が記憶されたメモリと、文字とその特徴データが対応して格納された認識辞書と、前記メモリから読み出した文書画像に対して所定の前処理を施して文字画像を生成する前処理部と、前記前処理部より生成された文字画像を、系統毎に異なる処理でいくつかのパターンに変化させた上で前記認識辞書に格納されている文字との類似度を計算する複数の計算系統と、前記複数の計算系統による計算結果として得られる複数の類似度を一つに統合する類似度統合部とを備える。
(もっと読む)
画像処理装置及び画像処理プログラム
【課題】罫線として点線、破線等が含まれている画像を解析する場合にあって、ラベリング技術を用いた場合に比較して、少ない計算機資源の割り当てで、罫線として認識されずに文字として認識してしまう誤りを抑制するようにした画像処理装置を提供する。
【解決手段】画像処理装置の線分長計測手段は、画像内の線分長を計測し、線分長評価手段は、前記線分長計測手段によって計測された線分長と前記線分の位置に基づいて、該線分の評価を行い、類似性評価手段は、前記線分長計測手段によって計測された線分長の類似性と前記線分の位置に基づいて、該線分の評価を行い、罫線判定手段は、前記線分長評価手段による評価結果と前記類似性評価手段による評価結果に基づいて、罫線であるか否かを判定する。
(もっと読む)
ベクトル系列用モデル基準比較指標及びそれを用いたワードスポッティング
【課題】より一般的にオブジェクトの定量的比較をおこなうようにする。
【解決手段】特徴抽出エンジン16により手書きのテキスト画像12から生成された、順序化された特徴ベクトル系列22を、SC−HMM)用モデル化エンジン26がモデル化して、重みパラメータの順序化された系列を生成する。同様に手書きの画像のサンプル画像14から、参照用重みパラメータの順序化された系列の対象モデルの語あるいは句38を生成する。動的時間伸縮法(DTW)の距離コンパレータ40は、これら(36、38)に適切に作用して、定量的比較指標42を生成する。
(もっと読む)
パターン認識辞書作成装置及びプログラム
【課題】 辞書を記憶する記憶容量が小さな装置であっても、画像パターンの認識精度を向上させることができるパターン認識辞書作成装置を提供する。
【解決手段】 入力画像の特徴量を求めて特徴ベクトルを生成する特徴ベクトル生成部111と、各画像の特徴ベクトル同士を比較して類似度の高い画像をグループとしてまとめるグループ化部114と、特徴ベクトル生成部で生成された特徴ベクトルに基づいて、画像の画素分布の情報を含む複数の特徴データを生成する主成分分析部113と、パターン認識用辞書を作成する場合に、グループに含まれない画像の特徴データのデータ量よりもグループに含まれる画像の特徴データのデータ量が多くなるように記憶装置23にデータを記憶させる辞書生成・登録部115とを有している。
(もっと読む)
出版物からOCR認識されたテキストとそれに対応するイメージをクライアント装置において選択に表示すること
光学式文字認識(OCR)処理を使用して出版物のソースイメージからテキストが抽出される。該抽出されたテキストの複数のテキストセグメントを内容とする文書が生成される。該文書は、表示された文書に対するユーザの相互作用に応答する制御モジュールを含む。表示されたテキストセグメントのユーザの選択に応じて、それに対応するイメージセグメントが前記テキストの前記ソースイメージから取り出され、該選択されたテキストセグメントに代えて表示される。該ユーザは該テキストセグメントに表示を戻すように再びトグル式に切り換えることができる。各テキストセグメントは、その品質を示すがらくた度スコアのタグが付けられ得る。或るテキストセグメントのがらくた度スコアが或る閾値を超えていると、それに対応するイメージセグメントがその代わりに自動的に表示され得る。 (もっと読む)
清書支援プログラム及び清書支援方法
【課題】文書データの清書作業を適切に支援することのできる清書支援プログラム及び清書支援方法の提供を目的とする。
【解決手段】清書対象とされた文書データの画像を表示装置に表示させる画像表示手順と、前記文書データに対する清書文字列の入力を受け付ける清書文字列入力手順と前記画像に対する文字認識結果に対して前記清書文字列をキーワードとする検索処理を実行し、検索された文字列の前記画像上における位置情報を前記文字認識結果より取得する検索手順と、前記検索手順において取得された前記位置情報に係る部分の表示態様を変更する表示態様変更手順とをコンピュータに実行させ、前記表示態様変更手順は、前記位置情報に係る部分の中で前記文字認識結果の確信度が所定値よりも低い文字に係る部分を識別可能なように表示態様の変更を行う。
(もっと読む)
筆跡情報管理システム、サーバ装置、筆跡情報管理方法及びプログラム
【課題】電子ペン用シートを再利用し、かつ筆跡情報を同一の電子ペン用シートへの筆跡情報に重ね合わせて記憶させる。
【解決手段】登録方法決定部107は、電子ペン200から筆跡情報を受信した時点の日時と、筆跡情報を1つの電子ペン用シート300に対する筆跡情報として登録する期間の繰り返し回数を示すサイクルとに基づいて、入力された筆跡情報をデータベース102に新規登録するか追加登録するかを決定する。
(もっと読む)
パターン識別装置及びパターン識別装置の学習方法ならびにコンピュータプログラム
【課題】学習に必要な演算量を低減可能なパターン識別装置の学習方法を提供する。
【解決手段】特徴抽出用パラメータに従ってデータから識別用特徴量を抽出する特徴抽出器11と、識別用特徴量を入力としてそのデータに表されたパターンを識別する識別器12とを有するパターン識別装置1の学習方法は、(a)学習用データセットに含まれる同一のパターンが表された学習用データの組を特徴抽出器11に入力して得られる識別用特徴量のクラスタを決定するステップと、(b)クラスタ間の最小距離を求めるステップと、(c)最小距離の極大値が検出されたか否か判定するステップと、(d)極大値が検出されていないと判定した場合、特徴抽出用パラメータを変更して、ステップ(a)〜(c)を繰り返すステップと、(e)極大値が検出された場合、その極大値に対応する特徴抽出用パラメータが、パターン識別処理の実行時に使用されるものとするステップを含む。
(もっと読む)
業務文書処理装置
【課題】グレースケールで保管された業務文書に対してOCRを適用する際に、文字列と印影が重なっている場合であっても、文字列の情報を残しつつ印影だけを除去するための技術を提供する。
【解決手段】印影の近傍に存在する文字列を、データベースと照合することにより、印影と重なった文字列を推定する。より具体的には、まず、グレースケールで入力された業務文書における印影領域を除去する。次に、除去された印影領域の近傍に存在する文字情報であって、一部の文字が印影領域によって不明確となっている文字情報を印影関連情報として抽出する。そして、抽出された印影関連情報の属性を特定し、文字列候補を格納する取引先の情報を格納する取引先データベースを参照して、属性毎に分類された印影関連情報を基に、印影領域と重複して不明確となっている文字列を推定する。
(もっと読む)
文字認識装置、文字認識装置の確認画面生成方法
【課題】イメージデータと、イメージデータに対応する認識文字列とを容易に比較可能にしたうえで、参酌対象となる他の項目の確認をも可能にして、オペレータによる効率的な確認作業ができる文字認識装置を提供する。
【解決手段】項目切出手段2は、イメージデータ1を項目イメージデータに切り出す。表示生成手段3は、訂正指示を受け付ける際に、訂正対象を含む項目イメージデータに対応する複数項目の文字認識情報の表示と、訂正対象となる文字認識情報に対応する項目イメージデータの表示とを併せた表示画面を生成する。項目イメージデータ表示配置手段4は、表示画面における項目イメージデータの表示位置を、項目イメージデータに対応する文字認識情報の表示位置および関連付け定義された他の文字認識情報の表示位置と重複しない表示位置に配置する。
(もっと読む)
201 - 220 / 787
[ Back to top ]