
Fターム[5B075ND03]の内容
Fターム[5B075ND03]に分類される特許
261 - 280 / 3,390
フィルタ設定システム、フィルタ設定方法、及びフィルタ設定プログラム
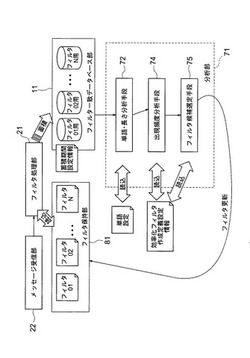
【課題】メッセージ処理にかかる処理負荷を有効に軽減する。
【解決手段】フィルタ条件に一致したメッセージ中の条件単語の出現回数、出現位置、および前記条件単語の長さを条件単語情報として算出し、この条件単語情報が予め設定されたフィルタ作成定義情報の値を上回る場合に、当該条件単語を追加フィルタ候補として抽出する出現頻度分析手段74と、追加フィルタ候補のメッセージ内における出現頻度割合が一定値以上である場合に、この追加フィルタ候補によりフィルタ条件情報の内容を追加更新するフィルタ候補選定手段75と、フィルタ条件情報に一致したメッセージの割合に基づき追加フィルタ情報のフィルタ有効性の有無判定を行いフィルタ有効性がないと判定されたフィルタ条件情報を削除するフィルタ有効性分析手段を備えた。
(もっと読む)
検索結果生成方法、検索結果生成プログラムおよび検索システム

【課題】 関連するドキュメントに類似するドキュメントを検索する。
【解決手段】
ドキュメント・セットの複数の擬似ドキュメントを生成し、擬似ドキュメントの各々は、ドキュメント・セットへの基本クエリの各々の実行に応じて検索されて取り出されるドキュメント・セットの少なくとも一つのドキュメントの代表情報を含み、ドキュメント・セットの複数のドキュメントの各々について該ドキュメントの各々の代表情報を含む擬似ドキュメントの索引を生成し、ドキュメント・セットの第1のドキュメントの代表情報を含む第1のドキュメント・クエリを受信し、第1のドキュメントと所定の関係を有する少なくとも一つのドキュメントの代表情報を含む少なくとも一つの擬似ドキュメントの第1のセットを識別し、少なくとも一つの擬似ドキュメントの第1のセットにもとづいて結果を生成する。
(もっと読む)
コンテンツ検索装置及び方法及びプログラム
【課題】 コンテンツを関連付ける対象領域を設定することなく、低コストでドキュメントの特定位置とコンテンツとを関連付ける。
【解決手段】 本発明は、ドキュメントから、文字ブロックを抽出し、文字ブロックと該文字ブロックが出現するドキュメントにおけるページ識別子とページ内座標を関連付けてインデックスDBに出力する。入力された検索クエリ(ドキュメント内の一部領域)から抽出したクエリ文字ブロックに基づいてインデックスDBを検索し、検索結果をページ毎に集計し、最も多くの文字ブロックが検索されたページをヒットページとし、ヒットページ内で検索された文字ブロックのページ内座標の重心を算出し、ページ内ヒット位置とし、算出されたヒットページとページ内ヒット位置をクエリとして、ページ内ヒット位置の近傍のページ位置が関連付けられたコンテンツをコンテンツDBから検索する。
(もっと読む)
談話要約生成システムおよび談話要約生成プログラム
【課題】話し言葉やノイズといった談話データの特性に強く、談話データの構造を解析した結果から、所望の項目や内容が含まれ、かつ不要な項目が含まれない形で要約を生成する談話要約生成システムを提供する。
【解決手段】談話データ101および談話構造の解析結果である談話セマンティクス200を入力とし、談話についての要約を生成して出力する談話要約生成システム1であって、談話データ101において要約300に含めるべき部分を特定するための単語の連接のパターンと、要約300に含める要約文章のひな型との対応のリストを指定した要約テンプレート72と、要約テンプレート72に指定された各パターンと談話データ101とのマッチングを行い、マッチした場合に要約テンプレート72におけるマッチしたパターンに対応する要約文章のひな型から要約文章を生成して要約300に追加する談話要約部70とを有する。
(もっと読む)
類似文書検索装置、類似文書検索方法、そのプログラムおよび記録媒体
【課題】文書間の類似性を文書に含まれる話題の重要度を加味して判定することより、従来より信頼性に優れた類似文書検索を可能とする。
【解決手段】1以上の参照文書から複数の話題カテゴリを抽出し、各参照文書における話題カテゴリの共起関係から各話題カテゴリの重みを求めた上で、重み付けられた話題カテゴリごとの標本文書と参照文書との類似度を求め、これを全ての話題カテゴリについて足し合わせることにより、標本文書と参照文書との類似度を得る。
(もっと読む)
感性辞書編集支援システム及びプログラム
【課題】自然文からユーザの価値判断が示されている表現を抽出する際に参照する感性辞書を効率的に編集できるように支援する技術の実現。
【解決手段】事物に対する肯定/否定の価値判断を表す感性用語と、肯定/否定の何れであるかを示す極性との組合せを格納しておく感性辞書記憶部18と、複数の用語について、各用語の類義語を定義したデータが格納された類義語辞書記憶部34と、起点語が入力された場合に、この起点語をキーに類義語辞書記憶部34を検索して起点語の類義語を抽出し、各類義語をキーに類義語辞書記憶部34を検索して各類義語の類義語を抽出し、抽出された用語のリストを含む感性用語登録画面80を生成してクライアント端末58に送信し、この画面80を介してリスト中の1または複数の用語を選択する情報と、各用語の極性を指定する情報が入力された場合に、選択された用語を指定された極性に関連付けて感性辞書記憶部18に格納する辞書編集支援部38を備えた。
(もっと読む)
関連語計算装置、関連語計算方法及び関連語計算プログラム
【課題】同義語より広い範囲の関連語を精度良く得る。
【解決手段】関連語計算装置100において、グループ化部130は統計情報データベース110から各単語の共起頻度に基づき作成された各単語のベクトルに基づき各単語のグループを作成する。グループ間計算部140は前記作成された各グループのベクトルに基づき計算された値から任意の2つのグループ間の距離を算出する計算を全てのグループの組に対して行い、前記算出された距離に基づく値が閾値を超えるグループを統合化の対象から除外する。グループ化判定部150は前記除外によって残されたグループの集合からグループ間で統合した場合の当該グループ間の距離が最小となるグループの対を選択しこの選択されたグループ間の距離が閾値未満である場合には当該グループの対を前記グループ化手段に供する一方で前記距離が閾値以上である場合には当該対の各グループのデータを出力する。
(もっと読む)
重要語句抽出装置及び方法及びプログラム
【課題】 ごく僅かな文書にしか出現しない非重要語を抽出することなく、重要語を抽出する。
【解決手段】 本発明は、「タイトル」「本文」「コメント」などの、文書において異なる役割を持つ文章群を「セクション」として定義し、複数のセクションから構成される訓練文書の集合を基に、入力文書から、前記入力文書中に語句が出現するセクション数と、前記訓練集合と前記入力文書から算出する残差逆文書頻度を用いて、前記入力文書の重要な語句を抽出する。
(もっと読む)
文書分析装置
【課題】 電子化された文書群の分析結果を表すテーブルを表示する際に、テーブル内で注目すべき零セルを強調して表示する。
【解決手段】 本明細書に開示された実施形態のベクトル生成部は、テーブル情報に基づいて、各行項目名の各々と当該各々の行項目名に関連付けられた各セルとを含む複数の行方向ベクトル情報と、各列項目名の各々と当該各々の列項目名に関連付けられた各セルとを含む複数の列方向ベクトル情報とを生成する。行方向クラスタリング部及び列方向クラスタリング部は、それぞれ各方向ベクトル情報間の類似度に基づいてクラスタリングを実行する。零セルスコアリング部は、各クラスタリング結果情報に基づいて各セルのスコアリングを実行してテーブルスコア情報を作成する。表示部は、テーブルスコア情報に基づいて、零セルに強調表示データを付加したテーブル情報を表示する。
(もっと読む)
文字列入力支援装置、文字列入力支援方法およびプログラム
【課題】文字列入力支援装置が、入力文字に含まれる文字の出現位置に応じて用語候補の選択や優先順位付けをより適切に行う。
【解決手段】文字位置情報生成部123が、ユーザにより入力済みの文字列に含まれる文字が、用語記憶部131の記憶する用語中に出現する位置を示す文字位置情報を生成する。そして、順位決定部124が、文字位置情報生成部123が生成した文字位置情報に基づいて、用語の順位を決定する。
(もっと読む)
情報検索装置、情報検索方法、及びプログラム
【課題】パトリシア木を用いた情報検索を従来技術よりも効率良く行うための技術を提供する。
【解決手段】パトリシア木から目的のキー情報を検索する情報検索装置において、パトリシア木を格納する情報格納手段と、前記情報格納手段に格納された前記パトリシア木から前記キー情報を検索する情報検索手段とを備え、前記情報格納手段に格納された前記パトリシア木において完全二分木となる部分木が配列で表現されており、前記情報検索手段は、前記キー情報を検索する際に、前記配列を参照することにより前記完全二分木となる部分木を探索するように構成する。
(もっと読む)
関係情報抽出装置、その方法及びプログラム
【課題】複数の固有表現間の関係情報を高精度で抽出可能な装置、方法及びプログラムを提供する。
【解決手段】入力された複数の固有表現に関係する情報を抽出する装置であって、前記各固有表現を含むテキストが入力されると、入力テキストを形態素解析するとともに入力テキストを構成する文節の係り受けを解析する解析処理部10と、解析処理部による解析結果を取得すると、入力テキストに含まれる少なくとも一つの自立語を関係情報候補として抽出するとともに、該各固有表現の関係情報として過去に用いられた過去関係情報が該関係情報候補に経時変化したと推定される度合を表す変化情報を、抽出された関係情報候補毎に取得し、解析結果及び変化情報に基づいて関係情報候補から関係情報を抽出する関係情報抽出処理部20とを備えた。
(もっと読む)
関連コンテンツ提示装置及びプログラム
【課題】 関連コンテンツの候補のキーワード分布特性が一致していない場合やテキスト量が少ない場合においても精度の高い関連コンテンツを提示する。
【解決手段】 本発明は、対象文書がWeb文書である場合は主要コンテンツの抽出を行い、文書内のテキストからキーワード候補を抽出し、抽出されたキーワードの重要度をWebIDFやBM25といったアルゴリズムを用いて出現頻度及び、キーワードの形態素の固有名詞の出現頻度、キーワード辞書のリンク構造に基づいて得られた文書のランキング、閲覧された回数、検索エンジンに投入された回数、キーワードが文の先頭に存在するか否か等の要素により重要度を計算し、重要度に基づいてキーワードを選択し、当該キーワードを組み合わせて検索クエリを生成し、検索することにより関連コンテンツを取得する。
(もっと読む)
投影システム、投影装置及びプログラム
【課題】電子辞書の使用環境を拡大し、より多くのユーザ間で知識を共有する。
【解決手段】画像信号を入力する入力部21と、入力した画像信号に対応する光像を形成して投影する投影系(22〜27)と、外部接続された電子辞書から送られてくる見出し語情報を受信するUSB・I/F32と、ネットワークを介して、文字情報を含むレコードを蓄積したデータベース(DB)サーバと接続し、USB・I/F32で受信した見出し語をネットワークを介してDBサーバに送信し、応答としてDBサーバから送られてくるレコードを受信するLAN・I/F33と、USB・I/F32で電子辞書から受信した見出し語情報とLAN・I/F33でDBサーバから受信したレコードに基づいた画像を形成し、投影系(22〜27)で投影させる投影画像処理部22及びCPU28とを備える。
(もっと読む)
言語横断型情報検索方法、言語横断型情報検索システム及び言語横断型情報検索プログラム
【課題】ユーザは画像情報により検索語の持つ多義性を視覚的に認識することができ、検索語に関連する意味に基づいて提示される翻訳語と検索関連語を選択できる言語横断型情報検索技術を提供する。
【解決手段】検索要求を解析し、原言語の検索語を取得し、原言語の単語と各単語の目的言語における対訳を記憶する対訳辞書を検索し、検索語の対訳を翻訳語候補として取得し、翻訳語候補をキーとして、画像検索を行い、画像情報を取得し、取得した画像情報を検索語に関連する意味に分類し、分類毎に、目的言語における検索関連語を抽出し、翻訳語候補と分類された画像データと検索関連語とをユーザに提示し、翻訳語候補と検索関連語とを選択させるための画面を生成し、ユーザに選択された翻訳語候補と検索関連語をキーとして、目的言語における情報検索を行う。
(もっと読む)
記号入力支援装置、記号入力支援方法、及びプログラム
【課題】入力文中へ絵文字等の記号を挿入する際に、文の内容を考慮した記号を決定し、実際の使用方法に沿った役割と位置を考慮した記号の挿入を、自動的に行う。
【解決手段】記号入力支援装置において、学習用の文中の各記号について、共起する単語との出現頻度を表す共起単語情報と、コンテクスト情報と、当該記号と記号ごとに与えられた所定の辞書中の語との共起情報とを算出し、算出結果を学習結果として学習結果格納手段に格納する記号出現頻度学習手段と、入力文中における記号挿入位置候補の位置ごとに、挿入対象である各記号について、前記学習結果格納手段に格納された前記学習結果を用いて、前記記号挿入位置候補の各位置に記号を挿入した場合における文特徴量を算出し、当該文特徴量に基づき、挿入に最も適した記号と挿入位置を特定し、当該記号と挿入位置とを変換候補記号格納手段に格納する挿入記号選定手段と、を備えて構成する。
(もっと読む)
文字列ベクトル変換装置、文字列ベクトル変換方法、プログラム、及びプログラムを格納したコンピュータ読み取り可能な記録媒体
【課題】意味表現として適切な文字列ベクトルを生成することを課題とする。
【解決手段】文字列ベクトルデータベース1と、テキストとを入力とし、前記文字列ベクトルデータベース1の複製である文字列ベクトルデータベース2を生成した後、前記テキスト中の、連続する有限個の単語の列である所定の範囲に存在する、前記文字列ベクトルデータベース1中の文字列A、Bの任意の対に対し、当該文字列Aの前記文字列ベクトルデータベース2中のベクトルに、前記文字列Bの前記文字列ベクトルデータベース1中のベクトルv(B)をスカラー倍したものを加算し、前記文字列Bの前記文字列ベクトルデータベース2中のベクトルに、前記文字列Aの前記文字列ベクトルデータベース1中のベクトルv(A)をスカラー倍したものを加算することを、前記テキスト中の全ての前記所定の範囲にわたって繰り返し、その結果得られた文字列ベクトルデータベース2を出力する。
(もっと読む)
重要語抽出装置とその方法とプログラム
【課題】対話テキストから、テキスト文書集合記憶部を用いずに重要語を抽出する重要語抽出装置を提供する。
【解決手段】この発明の重要語抽出装置は、発話分割部と、共通出現単語抽出部と、単語近傍度算出部と、単語重要度算出部と、を具備し、発話分割部は、複数人による会話の形態素解析済みの対話テキストを入力として、その対話テキストを話者毎の発話単位に分割し、共通出現単語抽出部は、その発話単位に共通して出現する共通出現単語を抽出し、単語近傍度算出部は、共通出現単語が他者の発話に出現する発話間隔を発話距離として検出し、当該発話距離数の逆数を単語近傍度として算出する。そして、単語重要度算出部は、共通出現単語の単語近傍度を入力として、単語近傍度が高く、その回数の多い共通出現単語ほど大きな値となる重要度を算出する。
(もっと読む)
情報処理装置および方法、並びに、プログラム
【課題】コンテンツに対する評価を予測する場合の予測精度を向上させる。
【解決手段】評価情報抽出部114は、ユーザにより言語で表現された情報である言語表現から評価対象および評価対象への評価を含む評価情報を抽出する。タイプ識別部115は、評価情報がコンテンツに関する第1のタイプの評価情報であるか、または、他のユーザに関する第2のタイプの評価情報であるかを識別する。評価予測部121は、注目ユーザによる第1のタイプの評価情報、および、注目ユーザによる第2のタイプの評価情報における他のユーザによる評価情報に基づいて、注目ユーザのコンテンツに対する評価を予測する。本発明は、例えば、ユーザにコンテンツを推薦するシステムに適用できる。
(もっと読む)
対話装置、対話方法、およびプログラム
【課題】ユーザの意思決定を支援できる対話装置がなかった。
【解決手段】スポットと1以上の決定要因と各決定要因の評価値とを有するスポット情報を2以上格納している知識ベースと、出力する文の文パターン情報と評価情報とを有する2以上の情報推薦手法を格納しており、決定要因に対するユーザの嗜好ベクトルと決定要因に対するユーザの知識ベクトルとを有するユーザ状態情報を格納しており、ユーザから文を受け付ける受付部と、ユーザ状態情報を2以上の各情報推薦手法の評価情報に適用し2以上のスコアを算出するスコア算出部と、スコアが最大の一の情報推薦手法が有する文パターン情報から文を構成する文構成部と、文を出力する文出力部と、受け付けた文や出力文から1以上の決定要因を取得し、ユーザ状態情報を更新するユーザ状態情報更新部とを具備する対話装置により、ユーザの意思決定を支援できる。
(もっと読む)
261 - 280 / 3,390
[ Back to top ]